CategoricalImputer#
分类数据在大多数数据科学项目中都很常见,并且也可能显示缺失值。有 2 种主要的插补方法 用于替换分类变量中的缺失数据。一种方法是用最频繁的类别替换缺失值。第二种方法是用一个专门的字符串替换缺失值,例如,“缺失”。
Scikit-learn 的机器学习算法无法直接处理缺失数据或分类变量。因此,在数据预处理阶段,我们需要使用插补技术来用任何允许的值替换 nan 值,然后在训练分类或回归模型之前进行分类编码。
处理缺失值#
Feature-engine 的 CategoricalImputer() 可以用任意值(如字符串 ‘Missing’)或最频繁的类别来替换分类变量中的缺失数据。
你可以通过将分类变量的名称以列表形式传递给 CategoricalImputer() 来输入分类变量的子集。或者,分类输入器会自动查找并输入训练数据框中所有类型为对象和分类的变量。
最初,我们设计这个插补器仅用于分类变量。在1.1.0版本中,我们引入了参数 ignore_format,以允许插补器也使用此功能插补数值变量。这是因为,在某些情况下,本质上为分类的变量具有数值。
Python 实现#
我们将使用 Ames 房价数据集展示 CategoricalImputer() 的数据插补功能。首先,我们将加载必要的库、函数和类,加载数据集,并将其分为训练集和测试集。
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from feature_engine.imputation import CategoricalImputer
data = fetch_openml(name='house_prices', as_frame=True)
data = data.frame
X = data.drop(['SalePrice', 'Id'], axis=1)
y = data['SalePrice']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)
print(X_train.head())
在以下输出中,我们看到了房价数据集的预测变量:
MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape \
254 20 RL 70.0 8400 Pave NaN Reg
1066 60 RL 59.0 7837 Pave NaN IR1
638 30 RL 67.0 8777 Pave NaN Reg
799 50 RL 60.0 7200 Pave NaN Reg
380 50 RL 50.0 5000 Pave Pave Reg
LandContour Utilities LotConfig ... ScreenPorch PoolArea PoolQC Fence \
254 Lvl AllPub Inside ... 0 0 NaN NaN
1066 Lvl AllPub Inside ... 0 0 NaN NaN
638 Lvl AllPub Inside ... 0 0 NaN MnPrv
799 Lvl AllPub Corner ... 0 0 NaN MnPrv
380 Lvl AllPub Inside ... 0 0 NaN NaN
MiscFeature MiscVal MoSold YrSold SaleType SaleCondition
254 NaN 0 6 2010 WD Normal
1066 NaN 0 5 2009 WD Normal
638 NaN 0 5 2008 WD Normal
799 NaN 0 6 2007 WD Normal
380 NaN 0 5 2010 WD Normal
[5 rows x 79 columns]
这两个变量显示为空值,我们来检查一下:
X_train[['Alley', 'MasVnrType']].isnull().sum()
我们在以下输出中看到空值:
Alley 1094
MasVnrType 6
dtype: int64
使用任意字符串进行插补#
让我们设置分类插补器,用任意字符串 ‘missing’ 来插补这两个变量:
imputer = CategoricalImputer(
variables=['Alley', 'MasVnrType'],
fill_value="missing",
)
imputer.fit(X_train)
在拟合过程中,转换器验证两个变量是否为对象类型或分类类型,并创建一个变量到替换值的字典。
我们可以如下检查将用于“fillna”的值:
imputer.fill_value
我们可以像这样检查每个变量的替换值的字典:
imputer.imputer_dict_
字典的键包含变量的名称,而其值包含插补值。在这种情况下,结果并不特别令人兴奋,因为我们用相同的值替换了所有变量中的 nan 值:
{'Alley': 'missing', 'MasVnrType': 'missing'}
我们现在可以继续处理缺失数据,并在插补后的结果变量中绘制类别:
train_t = imputer.transform(X_train)
test_t = imputer.transform(X_test)
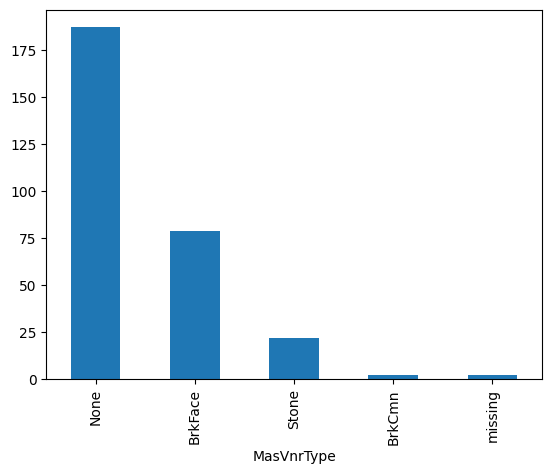
test_t['MasVnrType'].value_counts().plot.bar()
plt.ylabel("Number of observations")
plt.show()
在下图中,我们可以看到“缺失”类别的存在,这对应于填补的值:
使用最频繁的类别进行插补#
现在让我们用最频繁的类别来填补变量:
imputer = CategoricalImputer(
variables=['Alley', 'MasVnrType'],
imputation_method="frequent"
)
imputer.fit(X_train)
我们可以在插补器字典中找到每个变量的最频繁类别:
imputer.imputer_dict_
在以下输出中,我们看到 Alley 最频繁的类别是 'Grvl',而 MasVnrType 最频繁的值是 'None'。
{'Alley': 'Grvl', 'MasVnrType': 'None'}
我们现在可以继续填补缺失的数据,以获得一个完整的数据集,至少对于这2个变量,然后在填补后绘制值的分布:
train_t = imputer.transform(X_train)
test_t = imputer.transform(X_test)
test_t['MasVnrType'].value_counts().plot.bar()
plt.ylabel("Number of observations")
plt.show()
在下图中,我们看到了结果变量的分布:

自动填补所有分类变量#
CategoricalImputer() 可以在我们将参数 variables 设置为 None 时,自动查找并填补训练数据集中所有的分类特征:
imputer = CategoricalImputer(
variables=None,
)
train_t = imputer.fit_transform(X_train)
test_t = imputer.transform(X_test)
我们可以在 variables_ 属性中找到分类变量:
imputer.variables_
下面,我们看到了在训练数据框中找到的分类变量的列表:
['MSZoning',
'Street',
'Alley',
'LotShape',
'LandContour',
...
'SaleType',
'SaleCondition']
具有2种模式的分类特征#
一个变量可能有一个以上的众数。在这种情况下,转换器将引发错误。例如,当你将转换器设置为用最频繁的值来填补变量‘PoolQC’时:
imputer = CategoricalImputer(
variables=['PoolQC'],
imputation_method="frequent"
)
imputer.fit(X_train)
PoolQC 有超过一种模式,因此转换器引发以下错误:
196 self.imputer_dict_ = {var: mode_vals[0]}
198 # imputing multiple variables:
199 else:
200 # Returns a dataframe with 1 row if there is one mode per
201 # variable, or more rows if there are more modes:
ValueError: The variable PoolQC contains multiple frequent categories.
我们可以这样检查变量是否有多种模式:
X_train['PoolQC'].mode()
我们看到这个变量有3个类别,每个类别的最大观测数相似:
0 Ex
1 Fa
2 Gd
Name: PoolQC, dtype: object
考虑因素#
用一个自定义类别替换分类特征中的缺失值是标准做法,可能也是更自然的事情。当缺失值的百分比很小且变量的基数较低时,我们可能希望用最频繁的类别进行插补,以免引入不必要的噪声。
将插补与数据分析结合使用有助于确定最方便的插补方法以及插补对变量分布的影响。请注意,变量分布及其基数将影响机器学习模型的性能和工作方式。
使用最频繁类别进行插补会将缺失值与变量的最常见值混合。因此,通常的做法是添加虚拟变量以指示这些值最初是缺失的。参见 AddMissingIndicator。

