EndTailImputer#
The EndTailImputer() 用分布末尾的值替换缺失数据。该值可以通过均值加减若干倍的标准差来确定,或者使用四分位距接近规则来确定。该值也可以确定为最大值的因子。
您决定缺失数据应放置在变量分布的右侧还是左侧尾部。
从某种意义上说,EndTailImputer() “自动化” 了 ArbitraryNumberImputer() 的工作,因为它会自动找到变量分布末端远处的“任意值”。
EndTailImputer() 仅适用于数值变量。您可以通过传递变量名称列表来仅对数据中的部分变量进行插补。或者,插补器将自动选择训练集中的所有数值变量。
以下是使用房价数据集的代码示例(关于数据集的更多详情 请参见此处)。
首先,让我们加载数据并将其分为训练集和测试集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from feature_engine.imputation import EndTailImputer
# Load dataset
data = pd.read_csv('houseprice.csv')
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['Id', 'SalePrice'], axis=1),
data['SalePrice'],
test_size=0.3,
random_state=0,
)
现在我们设置 EndTailImputer() 来填补数据集中的两个变量。我们指示填补器使用均值加上3倍标准差的方式来寻找填补值,如下所示:
# set up the imputer
tail_imputer = EndTailImputer(imputation_method='gaussian',
tail='right',
fold=3,
variables=['LotFrontage', 'MasVnrArea'])
# fit the imputer
tail_imputer.fit(X_train)
通过 fit,EndTailImputer() 学习了指定变量的插补值,并将其存储在其一个属性中。我们现在可以继续对训练集和测试集进行插补。
# transform the data
train_t= tail_imputer.transform(X_train)
test_t= tail_imputer.transform(X_test)
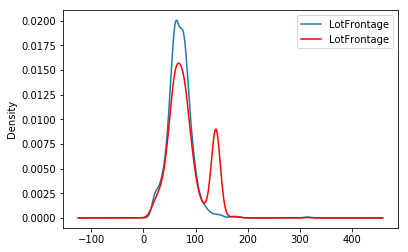
需要注意的是,在插补之后,如果缺失值的百分比相对较大,变量分布将与原始分布不同(红色为插补的变量):
fig = plt.figure()
ax = fig.add_subplot(111)
X_train['LotFrontage'].plot(kind='kde', ax=ax)
train_t['LotFrontage'].plot(kind='kde', ax=ax, color='red')
lines, labels = ax.get_legend_handles_labels()
ax.legend(lines, labels, loc='best')
其他资源#
在下面的 Jupyter 笔记本中,您将找到有关 CategoricalImputer() 功能的更多详细信息,包括如何自动选择数值变量、如何用最频繁的类别进行插补,以及如何用用户定义的字符串进行插补。
有关此方法和其他特征工程方法的更多详细信息,请查看以下资源:

机器学习的特征工程#
或者阅读我们的书:

Python 特征工程手册#
我们的书籍和课程都适合初学者和更高级的数据科学家。通过购买它们,您正在支持 Feature-engine 的主要开发者 Sole。