SelectByTargetMeanPerformance#
SelectByTargetMeanPerformance() 根据性能指标选择特征,例如分类的 ROC-AUC 或准确率,或回归的均方误差和 R 平方。
性能指标是通过将预测值与目标的真实值进行比较获得的。预测值越接近真实目标值,性能指标的值就越好。通常,这些预测值是从机器学习模型中获得的。
SelectByTargetMeanPerformance() 使用一种非常简单的方法来获取“预测”。如果变量是连续的,它返回每个类别或每个区间的目标值的平均值。通过将这些“预测”值与目标值进行比较,它确定每个特征的选择性能指标的值。
程序#
这个特征选择的想法非常简单;它涉及对每个级别(类别或区间)的响应(目标)取平均值,因此相当于在单个分类变量与响应变量之间进行最小二乘拟合,连续变量中的类别由区间定义。
尽管方法简单,但它有许多优点:
速度:计算均值和区间快速、直接且高效。
关于特征大小的稳定性:连续变量的极端值不会像在许多模型中那样扭曲预测。
连续变量与分类变量之间的可比性。
不假设线性关系,因此可以识别非线性。
不需要将分类变量编码为数字。
该方法也有一些局限性。首先,区间数量的选择以及阈值的设定是任意的。此外,当在评估过程中意外引入NAN时,稀有类别和非常偏斜的变量会引发错误。
SelectByTargetMeanPerformance() 与交叉验证一起工作。它使用 k-1 折来定义数值区间并学习每个类别或区间的目标均值。然后,它使用剩余的折来评估特征的性能:即在最后一折中,它将数值变量排序到区间中,用学习到的目标估计值替换区间和类别,并计算每个特征的性能。
重要#
SelectByTargetMeanPerformance() 自动识别数值变量和分类变量。它将选择分类变量为那些被转换为对象或分类类型的变量,以及数值变量为那些数值类型的变量。因此,请确保您的变量具有正确的数据类型。
故障排除#
使用此选择器时,您可能会遇到的主要问题是,在用目标均值估计替换类别或区间时,变量中引入了缺失数据。
分类变量#
当第 k 折中存在的类别在用于计算每个类别平均目标值的第 k-1 折中不存在时,分类变量中会引入 NAN。这可能是由于分类变量具有高基数(很多类别)或稀有类别,即在观察中仅占很小比例的类别。
如果发生这种情况,尝试减少变量的基数,例如通过将罕见标签分组到一个组中。查看 RareLabelEncoder 以获取更多详细信息。
数值变量#
当第k次交叉验证折叠中存在的区间在用于计算每个区间平均目标值的第k-1次折叠中不存在时,数值变量中会引入NAN。这可能是因为数值变量高度偏斜,或者具有很少的唯一值,例如,如果变量是离散的而不是连续的。
如果发生这种情况,检查有问题的变量的分布,并尝试识别问题。尝试使用等频区间而不是等宽区间,并减少箱的数量。
如果变量是离散的并且具有较少的唯一值,你可以做的是将变量转换为对象类型,这样选择器就会评估每个唯一值的平均目标值。
最后,如果一个数值变量确实是连续的且没有偏斜,检查它是否没有意外地被转换为对象类型。
示例#
让我们看看如何使用这种方法在泰坦尼克号数据集中选择变量。这个数据集包含数值变量和分类变量,因此它是展示这个选择器的一个好选项。
让我们导入所需的库和类,并准备泰坦尼克号数据集:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from feature_engine.datasets import load_titanic
from feature_engine.encoding import RareLabelEncoder
from feature_engine.selection import SelectByTargetMeanPerformance
data = load_titanic(
handle_missing=True,
predictors_only=True,
cabin="letter_only",
)
# replace infrequent cabins by N
data['cabin'] = np.where(data['cabin'].isin(['T', 'G']), 'N', data['cabin'])
# cap maximum values
data['parch'] = np.where(data['parch']>3,3,data['parch'])
data['sibsp'] = np.where(data['sibsp']>3,3,data['sibsp'])
# cast variables as object to treat as categorical
data[['pclass','sibsp','parch']] = data[['pclass','sibsp','parch']].astype('O')
print(data.head())
我们可以看到以下数据的前5行:
pclass survived sex age sibsp parch fare cabin embarked
0 1 1 female 29.0000 0 0 211.3375 B S
1 1 1 male 0.9167 1 2 151.5500 C S
2 1 0 female 2.0000 1 2 151.5500 C S
3 1 0 male 30.0000 1 2 151.5500 C S
4 1 0 female 25.0000 1 2 151.5500 C S
现在让我们继续将数据分割为训练集和测试集:
# separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['survived'], axis=1),
data['survived'],
test_size=0.1,
random_state=0)
X_train.shape, X_test.shape
我们看到了以下数据集的大小:
((1178, 8), (131, 8))
现在,我们设置 SelectByTargetMeanPerformance() 。我们将使用3折交叉验证来检查roc-auc。我们将数值变量分离成等频区间。并且我们将保留那些roc-auc大于所有特征的平均ROC-AUC的变量(默认功能)。
sel = SelectByTargetMeanPerformance(
variables=None,
scoring="roc_auc",
threshold=None,
bins=3,
strategy="equal_frequency",
cv=3,
regression=False,
)
sel.fit(X_train, y_train)
通过 fit() 方法,转换器:
用目标均值替换类别
将数值变量分类到等频箱中
用目标均值替换箱子
计算每个转换变量的roc-auc
选择roc-auc大于平均值的特征
在属性 variables_ 中,我们找到了被评估的变量:
sel.variables_
['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'cabin', 'embarked']
在属性 features_to_drop_ 中,我们找到未被选择的变量:
sel.features_to_drop_
['age', 'sibsp', 'parch', 'embarked']
评估特征重要性#
在属性 feature_performance_ 中,我们找到每个特征的 ROC-AUC。请记住,这是每个交叉验证折中的平均 ROC-AUC:
sel.feature_performance_
在以下输出中,我们看到了每个变量的目标均值编码返回的ROC-AUC:
{'pclass': 0.668151138112005,
'sex': 0.764831274819234,
'age': 0.535490029737471,
'sibsp': 0.5815934176199077,
'parch': 0.5721327969642238,
'fare': 0.6545985745474006,
'cabin': 0.630092526712033,
'embarked': 0.5765961846034091}
所有特征的平均 ROC-AUC 为 0.62,我们可以如下计算:
pd.Series(sel.feature_performance_).mean()
0.6229357428894605
在属性 feature_performance_std_ 中,我们找到每个特征的 ROC-AUC 的标准差:
sel.feature_performance_std_
下面我们看到 ROC-AUC 的标准差:
{'pclass': 0.0062490415569808975,
'sex': 0.006574623168243345,
'age': 0.023454310730681827,
'sibsp': 0.007263903286722272,
'parch': 0.017865107795851633,
'fare': 0.01669212962579665,
'cabin': 0.006868970787685758,
'embarked': 0.008925910686325774}
我们可以将性能与标准差一起绘制,以更好地了解特征的重要性:
r = pd.concat([
pd.Series(sel.feature_performance_),
pd.Series(sel.feature_performance_std_)
], axis=1
)
r.columns = ['mean', 'std']
r['mean'].plot.bar(yerr=[r['std'], r['std']], subplots=True)
plt.title("Feature importance")
plt.ylabel('ROC-AUC')
plt.xlabel('Features')
plt.show()
在下图中,我们可以看到特征的重要性:
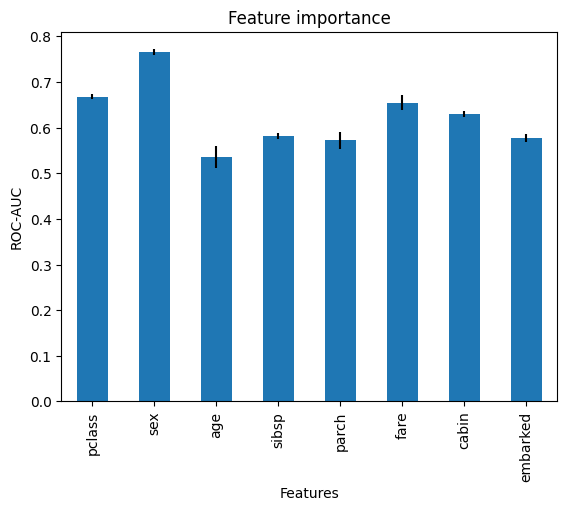
通过这个,我们可以更好地理解特征与目标变量之间的关系,基于线性回归模型。
检查生成的数据框#
通过 transform() 我们可以继续并删除这些特征:
Xtr = sel.transform(X_test)
Xtr.head()
pclass sex fare cabin
1139 3 male 7.8958 M
533 2 female 21.0000 M
459 2 male 27.0000 M
1150 3 male 14.5000 M
393 2 male 31.5000 M
最后,我们还可以获取最终转换数据中的特征名称:
sel.get_feature_names_out()
['pclass', 'sex', 'fare', 'cabin']

