LogCpTransformer#
LogCpTransformer() 应用变换 log(x + C),其中 x 是要变换的变量,C 是一个正的常数,它将分布向正值方向移动。
LogCpTransformer() 是 LogTransformer() 的一个扩展,允许添加一个常数以使分布向正值移动。有关对数变换的更多详细信息,请查看 LogTransformer() 的用户指南。
定义 C#
你可以将需要添加到变量的正值作为字典输入,其中键是变量名,值是添加到每个变量的常数。如果你想给所有变量添加相同的值,你可以传递一个整数或浮点数。
或者,LogCpTransformer() 将找到必要的值以使变量的所有值为正。对于严格正的变量,C 将为 0,转换将为 log(x)。
Python 示例#
让我们来看看 LogCpTransformer() 的功能。
转换严格正变量#
让我们加载 Scikit-learn 自带的加州住房数据集,并将其分为训练集和测试集。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
from feature_engine.transformation import LogCpTransformer
# Load dataset
X, y = fetch_california_housing( return_X_y=True, as_frame=True)
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)
现在我们想对数据集中的两个变量应用对数变换,使用 LogCpTransformer()。我们希望变换器能自动检测需要添加到变量中的量“C”:
# set up the variable transformer
tf = LogCpTransformer(variables = ["MedInc", "HouseAge"], C="auto")
# fit the transformer
tf.fit(X_train)
通过 fit() 方法,LogCpTransformer() 学习了参数“C”并将其存储为一个属性。我们可以如下所示地可视化学习到的参数:
# learned constant C
tf.C_
由于这些变量严格为正,变压器将在应用对数变换之前将0添加到变量中:
{'MedInc': 0, 'HouseAge': 0}
在这种情况下,LogCpTransformer() 应用的转换与使用 LogTransformer() 相同,因为这些变量严格为正。
我们现在可以继续并转换变量:
# transform the data
train_t= tf.transform(X_train)
test_t= tf.transform(X_test)
然后我们可以绘制原始变量的分布:
# un-transformed variable
X_train["MedInc"].hist(bins=20)
plt.title("MedInc - original distribution")
plt.ylabel("Number of observations")
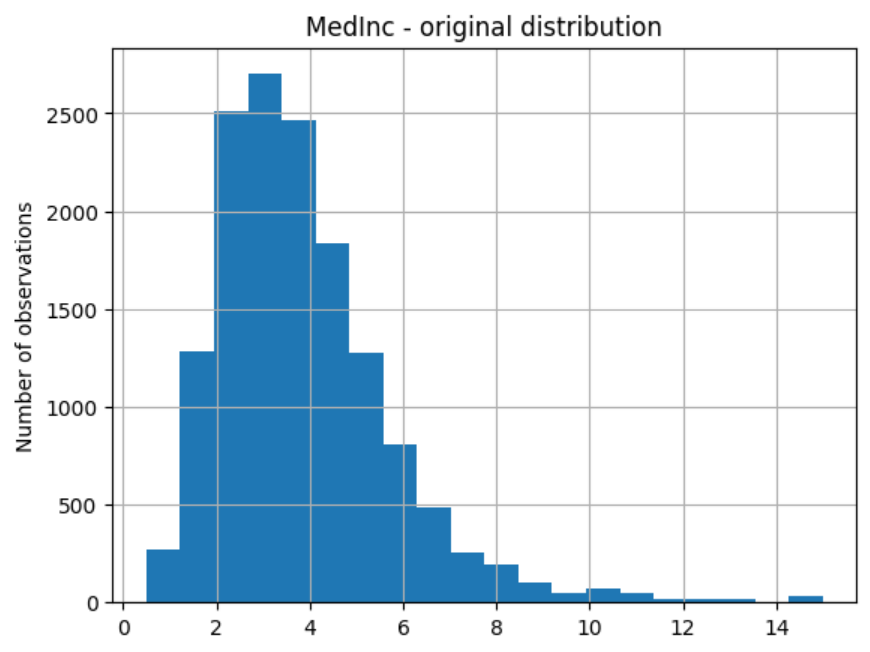
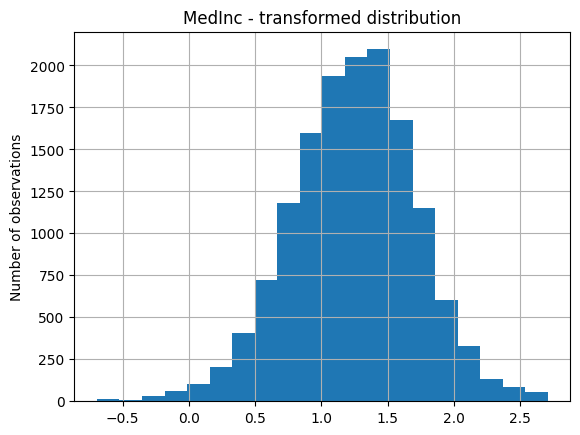
以及变换变量的分布:
# transformed variable
train_t["MedInc"].hist(bins=20)
plt.title("MedInc - transformed distribution")
plt.ylabel("Number of observations")
转换非严格正变量#
现在让我们展示 LogCpTransformer() 的功能,使用包含小于或等于 0 的值的变量。让我们加载糖尿病数据集:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from feature_engine.transformation import LogCpTransformer
# Load dataset
X, y = load_diabetes( return_X_y=True, as_frame=True)
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)
让我们打印出两个变量的主要特征的摘要:
print(X_train[["bmi", "s3"]].describe())
在以下输出中,我们看到变量包含负值:
bmi s3
count 309.000000 309.000000
mean -0.001298 0.000511
std 0.048368 0.048294
min -0.084886 -0.102307
25% -0.036385 -0.032356
50% -0.008362 -0.006584
75% 0.030440 0.030232
max 0.170555 0.181179
现在让我们设置 LogCpTransformer() 将变量的分布转移到正值,然后应用对数:
tf = LogCpTransformer(variables = ["bmi", "s3"], C="auto")
tf.fit(X_train)
我们可以检查将添加到每个变量的常量值:
tf.C_
由于这些变量不是严格正的,LogCpTransformer() 找到了使其值变为正所需的最小值:
{'bmi': 1.0848862355291056, 's3': 1.102307050517416}
我们现在可以转换数据:
train_t= tf.transform(X_train)
test_t= tf.transform(X_test)
让我们在转换之前绘制 bmi:
X_train["bmi"].hist(bins=20)
plt.title("bmi - original distribution")
plt.ylabel("Number of observations")
在下图中,我们看到了 bmi 的原始分布:
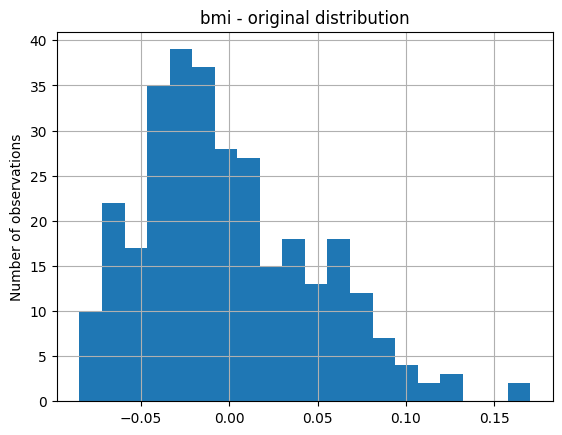
现在让我们绘制转换后的变量:
# transformed variable
train_t["bmi"].hist(bins=20)
plt.title("bmi - transformed distribution")
plt.ylabel("Number of observations")
在下图中,我们看到了 bmi 在转换后的分布:
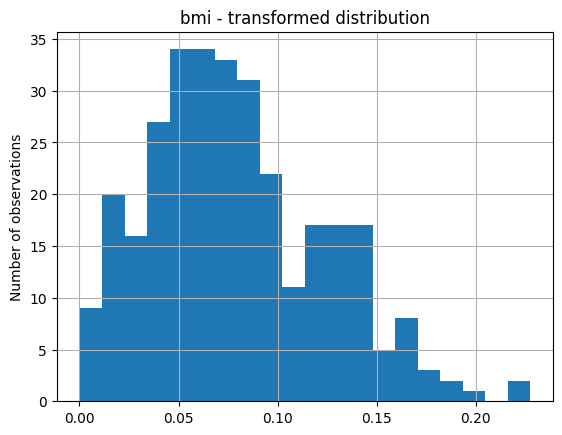
将相同的常量添加到所有变量#
你可以通过设置 LogCpTransformer() 如下所示,将相同的常数添加到所有变量中:
tf = LogCpTransformer(C=5)
tf.fit(X_train)
在这种情况下,所有数值变量都将被转换。我们可以在 variables_ 属性中找到将被转换的变量:
tf.variables_
所有数值变量都被选中进行转换:
['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
你现在可以对所有这些变量应用 transform() 进行转换。
添加不同的用户定义常量#
如果你想为特定变量添加特定值,可以通过设置 LogCpTransformer() 如下进行:
tf = LogCpTransformer(C={"bmi": 2, "s3": 3, "s4": 4})
tf.fit(X_train)
在这种情况下,LogCpTransformer() 只会修改字典中指示的变量:
tf.variables_
字典中的变量将被转换:
['bmi', 's3', 's4']
而常量值将是字典中的那些值:
tf.C_
C_ 与 C 中输入的值一致:
{'bmi': 2, 's3': 3, 's4': 4}
你现在可以对所有这些变量应用 transform() 进行转换。
教程、书籍和课程#
你可以在以下位置找到更多关于 LogCpTransformer() 的详细信息:
关于此方法及其他数据转换方法(如平方根转换、幂转换、Box-Cox 转换)的教程,请查看我们的在线课程:

机器学习的特征工程#
或者阅读我们的书:

Python 特征工程手册#
我们的书籍和课程都适合初学者和更高级的数据科学家。