RandomSampleImputer#
The RandomSampleImputer() 用从变量中提取的随机样本来替换缺失数据。它适用于数值变量和分类变量。可以指定变量列表,或者插补器将自动选择训练集中的所有变量。
注意
用于替换缺失值的随机样本可能在每次执行时有所不同。这可能会影响您的工作结果。因此,建议设置一个种子。
设置种子#
在 RandomSampleImputer() 中,种子可以设置的两种方式:
如果 seed = 'general',那么 random_state 可以是 None 或一个整数。random_state 随后提供了用于插补的种子。所有观测值将一次性使用单一种子进行插补。这等同于 pandas.sample(n, random_state=seed),其中 n 是缺失数据观测值的数量,seed 是你在 random_state 中输入的数字。
如果 seed = 'observation',那么 random_state 应该是一个变量名或变量名列表。种子将根据每个观察值计算,通过在 random_state 中指示的变量值相加或相乘。然后,将使用该种子从训练集中提取一个值,并用它来替换该特定观察值中的 NAN。这相当于如果 seeding_method 设置为 add,则为 pandas.sample(1, random_state=var1+var2),或者如果 seeding_method 设置为 multiply,则为 pandas.sample(1, random_state=var1*var2)。
例如,如果观察显示变量 color: np.nan, height: 152, weight:52,并且我们将插补器设置为:
RandomSampleImputer(random_state=['height', 'weight'],
seed='observation',
seeding_method='add'))
变量 colour 中的 np.nan 将使用 pandas 样本替换,如下所示:
observation.sample(1, random_state=int(152+52))
有关此功能为何重要的更多详情,请参阅课程 机器学习中的特征工程。
你也可以在以下 notebook 中找到更多关于这个插补的详细信息。
注意,如果 random_state 列表中指示的变量不是数值,插补器将返回错误。此外,指示为种子的变量本身不应包含缺失值。
对 GDPR 重要#
当调用 fit() 方法时,此估计器会存储一份训练集的副本。因此,该对象可能会变得相当大。此外,如果您的训练数据集包含个人信息,这可能不符合 GDPR 规定。请检查此行为是否在您的组织内允许。
以下是使用房屋价格数据集的代码示例(有关数据集的更多详细信息,请参阅 此处)。
首先,让我们加载数据并将其分为训练集和测试集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from feature_engine.imputation import RandomSampleImputer
# Load dataset
data = pd.read_csv('houseprice.csv')
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['Id', 'SalePrice'], axis=1),
data['SalePrice'],
test_size=0.3,
random_state=0
)
在这个例子中,我们随机采样每个观察值,使用变量 ‘MSSubClass’ 和变量 ‘YrSold’ 的值作为种子。注意,这个值对于每个观察值可能是不同的。
The RandomSampleImputer() 将填补数据中的所有变量,因为我们保留了参数 variables 的默认值为 None。
# set up the imputer
imputer = RandomSampleImputer(
random_state=['MSSubClass', 'YrSold'],
seed='observation',
seeding_method='add'
)
# fit the imputer
imputer.fit(X_train)
通过 fit() 方法,imputer 存储了 X_train 的一个副本。而在 transform 方法中,它将从这个 X_train 中随机提取值来替换 transform() 方法中指定数据集中的 NA。
# transform the data
train_t = imputer.transform(X_train)
test_t = imputer.transform(X_test)
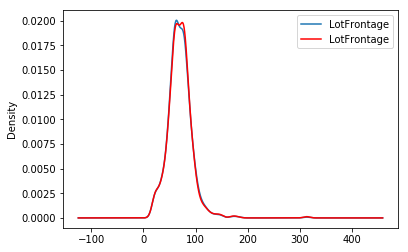
随机采样器的优点在于它保留了原始变量分布:
fig = plt.figure()
ax = fig.add_subplot(111)
X_train['LotFrontage'].plot(kind='kde', ax=ax)
train_t['LotFrontage'].plot(kind='kde', ax=ax, color='red')
lines, labels = ax.get_legend_handles_labels()
ax.legend(lines, labels, loc='best')
附加资源#
在下面的 Jupyter 笔记本中,您将找到有关 RandomSampleImputer() 功能的更多详细信息,包括如何设置不同类型的种子。
所有 Feature-engine 笔记本都可以在 专用仓库 中找到。
最后,关于这种和其他插补技术的信息,也可以在这门在线课程中找到:

机器学习的特征工程#
或者阅读我们的书:

Python 特征工程手册#
我们的书籍和课程都适合初学者和更高级的数据科学家。通过购买它们,您正在支持 Feature-engine 的主要开发者 Sole。