DropHighPSIFeatures#
The DropHighPSIFeatures() 查找并移除其分布发生变化的特征,即“不稳定值”,从 pandas 数据框中。分布的稳定性是通过 人口稳定性指数 (PSI) 计算的,所有 PSI 值高于给定阈值的特征都会被移除。
如果训练群体与生产群体显著不同,不稳定特征可能会在模型中引入额外的偏差。移除那些怀疑分布发生变化的特征会导致更稳健的模型,从而带来更好的性能。在信用风险建模领域,消除高PSI特征是常见的做法,通常也是监管机构所要求的。
人口稳定指数 - PSI#
PSI 是衡量一个群体随时间变化的程度,或两个不同群体样本之间分布差异的指标。
为了确定 PSI,连续特征被排序到离散区间中,然后确定每个区间的观测比例,最后将这些值在两组之间进行比较,或者在我们称之为 Feature-engine 的术语中,在基础集和测试集之间进行比较,以获得 PSI。
换句话说,PSI 的计算如下:
定义观测值将被排序的区间。
将特征值排序到这些区间中。
确定每个区间内的观测值比例。
计算PSI。
PSI 的确定方式如下:
其中 basis 和 test 分别是“参考”和“评估”数据集,i 表示区间。
换句话说,PSI 决定了参考数据集(即原始数据集)和测试数据集在每个区间内观测比例的差异。
在PSI方程中,n 是区间的总数。
重要#
在使用PSI时,值得强调以下几点:
PSI 不是对称的;在 PSI 计算中交换基数据框和测试数据框的顺序将导致不同的值。
用于定义分布的箱数对PSI值有影响。
PSI 是适用于数值特征(即,连续或高基数的特征)的合适指标。
对于分类或离散特征,使用卡方检验来评估分布的变化更为合适。
阈值#
可以根据PSI值使用不同的阈值来评估分布偏移的程度。最常用的阈值是:
低于10%时,该变量未经历显著变化。
超过25%,该变量经历了重大转变。
在这两个值之间,变化是中等的。
‘auto’: 阈值将根据基础数据集和目标数据集的大小以及分箱数量来计算。
当为 ‘auto’ 时,阈值使用 B. Yurdakul 提出的卡方近似法计算。
其中 q 是百分位数,B 是箱数,N 是基础数据集的大小,N 是测试数据集的大小。
在我们的实现中,我们使用的是第99.9百分位数。
如上所述,箱数对PSI值有影响,因为箱数越多,越容易发现数据中的差异,反之亦然。同样的情况也适用于数据集大小——数据越多,越难发现差异(如果变化不是剧烈的)。这个公式试图捕捉这些关系,并调整阈值以正确检测特征漂移。
程序#
为了计算PSI,DropHighPSIFeatures() 将输入数据集分为两部分:一个基础数据集(即参考数据)和一个测试集。基础数据集假设包含预期的或原始的特征分布。测试集将根据基础数据集进行评估。
在下一步中,区间边界是根据基数据或参考数据中的特征来确定的。这些区间可以确定为等宽,或等数量的观测值。
接下来,DropHighPSIFeatures() 将每个变量的值分别排序到这些区间中,无论是在基础数据集还是测试数据集中,然后确定每个区间内的观察比例(百分比)。
最后,对于每个特征,PSI 的确定如前一段所述。根据每个特征的 PSI 值,DropHighPSIFeatures() 现在可以选择那些不稳定的特征并根据阈值删除它们。
分割数据#
DropHighPSIFeatures() 允许我们确定特征分布随时间变化的程度,或者两个组之间差异的程度。
如果我们想要评估随时间变化的分布变化,我们可以使用一个日期时间变量作为分割参考,并提供一个日期时间截止点作为分割点。
如果我们想比较两组之间的分布变化,DropHighPSIFeatures() 提供了三种不同的方法来分割输入数据框:
基于观察的比例。
基于唯一观测值的比例。
使用一个截止值。
观察值的比例#
按观察值的比例进行分割将导致一定比例的观察值被分配到参考数据集和测试数据集中。例如,如果我们设置 split_frac=0.75,那么 75% 和 25% 的观察值将分别放入参考数据和测试数据中。
如果我们选择这种方法,我们可以在参数 split_col 中传递一个变量,或者将其保留为 None。
需要注意的是,数据分割不是随机的,而是由 split_col 中指示的参考变量的值引导的。在底层,split_col 中指示的参考变量是有序的,观察值的百分比由 NumPy 的分位数决定。这意味着 split_col 中值较小的观察值将落入参考数据集,而值较大的观察值将进入测试集。
如果你的数据集中的行是按时间排序的,这可能是一个很好的默认选项来将数据框分成两部分并计算PSI。例如,如果你的数据集包含公司产品的每日(或任何其他频率)销售信息,就会出现这种情况。
独特观察的比例#
如果我们基于唯一观测值的比例进行分割,重要的是我们要在 split_col 参数中指明我们想要使用哪一列作为参考,以进行有意义的分割。如果我们将其留为 None,DropHighPSIFeatures() 将使用数据框索引作为参考。只有当数据框中的索引具有有意义的值时,这才有意义。
DropHighPSIFeatures() 将首先识别 split_col 变量的唯一值。然后它会将这些值的一定比例放入参考数据集中,其余的放入测试数据集中。比例由参数 split_frac 指示。
在内部,DropHighPSIFeatures() 将排序参考变量的唯一值,然后使用 NumPy 分位数来确定应分配给参考集和测试集的比例。因此,考虑唯一值的顺序在分割中很重要。
当我们有例如唯一的客户标识符和每个客户在数据集中有多行时,这种分割是有意义的。我们希望确保属于同一客户的所有行都被分配到参考数据或测试数据中,但同一客户不能同时出现在两个数据集中。这种分割数据的方式还将确保我们在分割后在任一数据集中都有一定百分比的客户,该百分比在 split_frac 中指示。
因此,如果 split_frac=0.6 且 split_distinct=True,DropHighPSIFeatures() 会将前 60% 的客户发送到参考数据集,并将剩余的 40% 发送到测试集。并且它会确保属于同一客户的行仅位于两个数据集之一中。
使用一个截断值#
我们可以选择传递一个引用变量,用于使用 split_col 分割数据框,并在 cut_off 参数中设置一个截止值。截止值可以是数字、整数或浮点数、日期或值列表。
如果在 split_col 中传递一个 datetime 列,并在 cut_off 中传递一个 datetime 值,我们可以按时间方式分割数据。在指定时间之前收集的观察结果将被发送到参考数据框,其余的将被发送到测试集。
如果我们传递一个值列表到 cut_off,所有值包含在该列表中的观察将被放入参考数据集,其余的则放入测试集。如果我们有一个表示观察来源的投资组合的分类变量,这种分割方式非常有用。例如,如果我们设置 split_col='portfolio' 并且 cut_off=['port_1', 'port_2'],所有属于第一个和第二个投资组合的观察将被发送到参考数据集,而来自其他投资组合的观察将被发送到测试集。
最后,如果我们向 cut_off 传递一个数字,所有在 split_col 中指示的变量值 <= 截断值的观测值将被发送到参考数据集,否则将被发送到测试集。这在日期被定义为整数(例如 20200411)或使用序数客户细分来分割数据框时(1: 零售客户, 2: 私人银行客户, 3: 中小企业, 4: 批发)非常有用。
split_col#
要分割数据集,我们建议您在 split_col 参数中指定要用作参考的列。如果您不指定,分割将基于数据框索引的值进行。如果索引包含有意义的值或仅基于 split_frac 进行分割,这可能是一个好的选项。
示例#
该类的多功能性在于可以通过不同的选项将输入数据框拆分为具有“预期”分布的参考或基础数据集,以及将针对参考数据集进行评估的测试集。
分割数据后,DropHighPSIFeatures() 继续通过计算 PSI 来比较两个数据集中的特征分布。
为了说明如何根据您的数据最佳使用 DropHighPSIFeatures(),我们提供了各种示例,展示了不同的可能性。
基于比例(split_frac)拆分数据#
在这种情况下,DropHighPSIFeatures() 将根据指定的比例将数据集分成两部分。比例在 split_frac 参数中指定。您可以选择 split_col 中的一个变量,或者将其保留为 None。在后一种情况下,将使用数据框索引来分割。
首先,让我们创建一个包含5个随机变量和1个分布有偏移的变量的玩具数据框(在本例中为*var_3*)。
import pandas as pd
import seaborn as sns
from sklearn.datasets import make_classification
from feature_engine.selection import DropHighPSIFeatures
# Create a dataframe with 500 observations and 6 random variables
X, y = make_classification(
n_samples=500,
n_features=6,
random_state=0
)
colnames = ["var_" + str(i) for i in range(6)]
X = pd.DataFrame(X, columns=colnames)
# Add a column with a shift.
X['var_3'][250:] = X['var_3'][250:] + 1
在 DropHighPSIFeatures() 中的默认方法是将输入数据框 X 分成两个大小相等的数据集。你可以通过更改 split_frac 参数中的值来调整比例。
例如,让我们将输入数据框拆分为包含60%观测值的参考数据集和包含40%观测值的测试集。
# Remove the features with high PSI values using a 60-40 split.
transformer = DropHighPSIFeatures(split_frac=0.6)
transformer.fit(X)
split_frac 的值告诉 DropHighPSIFeatures() 按照 60% - 40% 的比例分割 X。fit() 方法执行数据框的分割和 PSI 的计算。
因为我们创建了随机变量,这些特征将具有较低的PSI值(即,没有分布变化)。然而,我们在变量 var_3 中手动添加了分布偏移,因此预计该特定特征的PSI将超过0.25 PSI阈值。
PSI 值可以通过 psi_values_ 属性访问:
transformer.psi_values_
对以下PSI值的分析显示,只有特征3(称为`var_3`)的PSI值高于0.25阈值(默认值),并且将被`transform`方法移除。
{'var_0': 0.07405459925568803,
'var_1': 0.09124093185820083,
'var_2': 0.16985790067687764,
'var_3': 1.342485289730313,
'var_4': 0.0743442762545251,
'var_5': 0.06809060587241555}
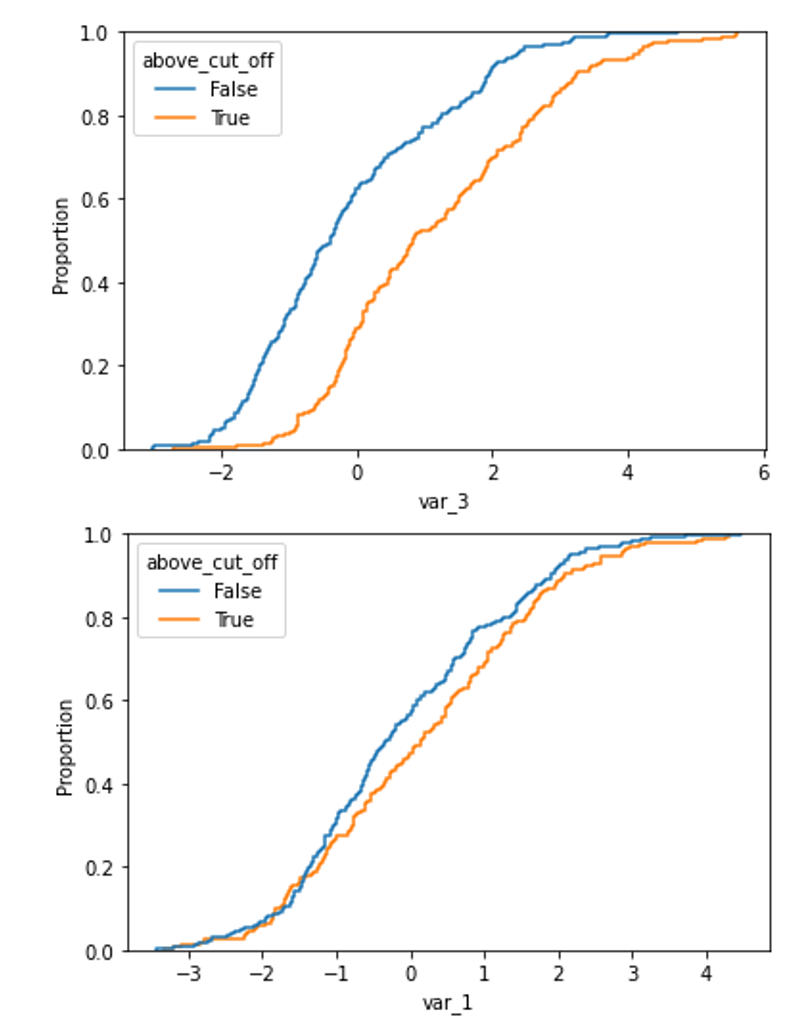
从输出结果中,我们看到 var_0 的 PSI 值大约为 7%。这意味着,在比较数据框的前 300 个和后 200 个观测值时,var_0 特征的分布只有很小的差异。类似的结论也适用于 var_1, var_2, var_4 和 var_5。观察 var_3 的 PSI 值,我们发现它远远超过了 0.25 的阈值。因此,我们可以得出结论,该特征的总体已经发生了变化,明智的做法是不将其包含在用于建模的特征集中。
用于分割数据帧的截止值存储在 cut_off_ 属性中:
transformer.cut_off_
这将产生以下答案
299.4
299.4 的值意味着使用索引从 0 到 299 的观测值来定义基础数据集。这对应于原始数据框(X)的 60%(300 / 500)。299.4 的值可能看起来很奇怪,因为它不是数据框(索引)中的值之一。直观上,我们期望 cut_off 在这种情况下是一个整数。然而,cut_off 是使用分位数计算的,而分位数是使用外推法计算的。
按比例分割将首先对索引或参考列进行排序,然后确定将进入每个数据帧的数据。换句话说,索引的顺序或 split_col 中指示的变量的顺序很重要。具有最低值的观察结果将被发送到基础数据帧,而具有最高值的观察结果将被发送到测试集。
features_to_drop_ 属性提供了在执行 transform 方法时要删除的特征列表。
命令
transformer.features_to_drop_
产生以下结果:
['var_3']
在查看 X_transformed 数据框的列时,可以看出在过程中 var_3 特性被删除了。
X_transformed = transformer.transform(X)
X_transformed.columns
Index(['var_0', 'var_1', 'var_2', 'var_4', 'var_5'], dtype='object')
DropHighPSIFeatures() 还包含一个 fit_transform 方法,该方法结合了 fit 和 transform 方法。
在绘制累积密度函数时,非偏移分布与偏移分布之间的分布差异清晰可见。
对于偏移变量:
X['above_cut_off'] = X.index > transformer.cut_off_
sns.ecdfplot(data=X, x='var_3', hue='above_cut_off')
以及一个未移位的变量(例如 var_1)
sns.ecdfplot(data=X, x='var_1', hue='above_cut_off')
案例 2:基于变量(数值 cut_off)拆分数据#
在前面的例子中,我们希望将输入的数据框分成两个数据集,其中参考数据集包含60%的观测值。我们让 DropHighPSIFeatures() 找到实现这一目标的截止点。
我们可以自行提供数值截止点,该截止点决定了哪些观测值将进入参考或基础数据集,哪些将进入测试集。通过使用 cut_off 参数,我们可以定义分割的具体阈值。
一个实际生活中的例子是使用客户ID或合同ID来分割数据框。这些ID通常随着时间的推移而增加,这证明了它们用于评估特征分布变化的合理性。
让我们创建一个代表公司客户特征的玩具数据框。这个数据集包含六个随机变量(在现实生活中,这些变量如年龄或邮政编码),客户的资历(即客户与公司建立关系以来的月数)和客户ID(即用于识别客户的数字(整数))。通常,客户ID随时间增长,这意味着早期客户的客户ID低于晚期客户。
根据变量的定义,我们预期 资历 会随着客户ID的增加而增加,因此在比较早期和晚期客户时会有较高的PSI值。
import pandas as pd
from sklearn.datasets import make_classification
from feature_engine.selection import DropHighPSIFeatures
X, y = make_classification(
n_samples=500,
n_features=6,
random_state=0
)
colnames = ["var_" + str(i) for i in range(6)]
X = pd.DataFrame(X, columns=colnames)
# Let's add a variable for the customer ID
X['customer_id'] = [customer_id for customer_id in range(1, 501)]
# Add a column with the seniority... that is related to the customer ID
X['seniority'] = 100 - X['customer_id'] // 10
transformer = DropHighPSIFeatures(split_col='customer_id', cut_off=250)
transformer.fit(X)
在这种情况下,DropHighPSIFeatures() 将在基础或参考数据集中分配所有 customer_id 值 <= 250 的观察结果。测试数据框包含剩余的观察结果。
方法 fit() 将确定 PSI 值,这些值存储在类中:
transformer.psi_values_
我们看到 DropHighPSIFeatures() 没有为 customer_id 特征提供任何 PSI 值,因为该变量被用作分割数据的参考。
{'var_0': 0.07385590683974477,
'var_1': 0.061155637727757485,
'var_2': 0.1736694458621651,
'var_3': 0.044965387331530465,
'var_4': 0.0904519893659045,
'var_5': 0.027545195437270797,
'seniority': 7.8688986006052035}
transformer.features_to_drop_
给出
['seniority']
执行数据框转换会导致排除 seniority 特征,但不会排除 customer_id。
X_transformed = transformer.transform(X)
X_transformed.columns
Index(['var_0', 'var_1', 'var_2', 'var_3', 'var_4', 'var_5', 'customer_id'], dtype='object')
案例 3:基于时间分割数据(以日期为截止点)#
DropHighPSIFeatures() 可以处理不同类型的 split_col 变量。以下案例说明了它如何与日期变量一起工作。实际上,我们经常希望确定某个特征的分布是否随时间变化,例如在某个事件之后,如新冠疫情开始时。
这是如何做到的。让我们创建一个包含6个随机数值变量和两个日期变量的玩具数据框。一个将用于指定数据框的分割,而第二个预计会有较高的PSI值。
import pandas as pd
from datetime import date
from sklearn.datasets import make_classification
from feature_engine.selection import DropHighPSIFeatures
X, y = make_classification(
n_samples=1000,
n_features=6,
random_state=0
)
colnames = ["var_" + str(i) for i in range(6)]
X = pd.DataFrame(X, columns=colnames)
# Add two time variables to the dataframe
X['time'] = [date(year, 1, 1) for year in range(1000, 2000)]
X['century'] = X['time'].apply(lambda x: ((x.year - 1) // 100) + 1)
# Let's shuffle the dataframe and reset the index to remove the correlation
# between the index and the time variables.
X = X.sample(frac=1).reset_index(drop=True)
通过提供包含日期的列的名称和截止日期,可以简单地删除两个时间段内PSI值较高的功能。在下面的示例中,PSI计算将比较法国大革命前后的时间段。
transformer = DropHighPSIFeatures(split_col='time', cut_off=date(1789, 7, 14))
transformer.fit(X)
重要: 如果日期变量是 pandas 或 NumPy 的日期时间格式,您可能需要将 cut_off 值传递为 pd.to_datetime(1789-07-14)。
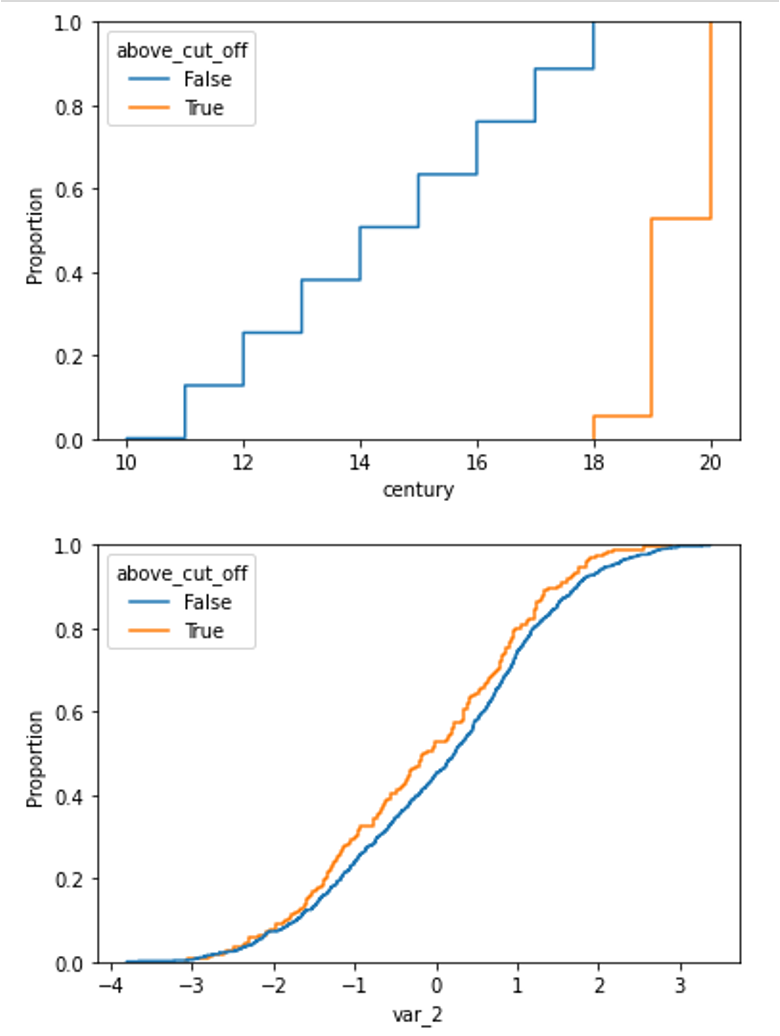
PSI 值显示了 century 变量在不稳定状态,因为其值超过了 0.25 的阈值。
transformer.psi_values_
{'var_0': 0.0181623637463045,
'var_1': 0.10595496570984747,
'var_2': 0.05425659114295842,
'var_3': 0.09720689210928271,
'var_4': 0.07917647542638032,
'var_5': 0.10122468631060424,
'century': 8.272395772368412}
该类已正确识别出要丢弃的特征。
transformer.features_to_drop_
['century']
并且转换方法正确地移除了该功能。
X_transformed = transformer.transform(X)
X_transformed.columns
Index(['var_0', 'var_1', 'var_2', 'var_3', 'var_4', 'var_5', 'time'], dtype='object')
在绘制每个组的累积密度函数时,非移位分布与移位分布之间的分布差异清晰可见。
我们可以这样绘制偏移变量的累积分布图:
X['above_cut_off'] = X.time > pd.to_datetime(transformer.cut_off_)
sns.ecdfplot(data=X, x='century', hue='above_cut_off')
以及非偏移变量的分布,例如 var_2,如下所示:
sns.ecdfplot(data=X, x='var_2', hue='above_cut_off')
下面我们可以比较这两个图表:
案例 4:基于分类变量(类别或列表作为 cut_off)拆分数据#
DropHighPSIFeatures() 也可以根据分类变量拆分原始数据框。然后可以通过两种方式定义截止点:
使用单个字符串。
使用一个值列表。
在第一种情况下,包含分类变量的列按字母顺序排序,分割由截止点决定。我们建议在使用单一类别作为截止点时要非常小心,因为字母顺序排序与截止点结合并不总能提供明显结果。换句话说,为了使这种分割数据的方式有意义,参考变量中类别的字母顺序应具有内在意义。
基于分类变量拆分数据的更好目的是传递一个包含所需参考数据框中变量值的列表。这种情况下的一个实际例子是计算不同客户细分(如’零售’、’中小企业’或’批发’)之间的PSI。在这种情况下,如果我们指定[‘零售’]作为截止点,零售的观测值将被发送到基础数据集,而’中小企业’和’批发’的观测值将被添加到测试集中。
分割传递一个类别值#
让我们展示在这种情况下如何设置转换器。示例数据集包含6个随机变量,一个带有不同类别标签的分类变量和2个与类别相关的特征。
import pandas as pd
import seaborn as sns
from sklearn.datasets import make_classification
from feature_engine.selection import DropHighPSIFeatures
X, y = make_classification(
n_samples=1000,
n_features=6,
random_state=0
)
colnames = ["var_" + str(i) for i in range(6)]
X = pd.DataFrame(X, columns=colnames)
# Add a categorical column
X['group'] = ["A", "B", "C", "D", "E"] * 200
# And two category related features
X['group_means'] = X.group.map({"A": 1, "B": 2, "C": 0, "D": 1.5, "E": 2.5})
X['shifted_feature'] = X['group_means'] + X['var_2']
我们可以定义一个简单的截止值(例如字母C)。在这种情况下,按字母顺序排在C之前的观测值将被分配到参考数据集中。
transformer = DropHighPSIFeatures(split_col='group', cut_off='C')
X_transformed = transformer.fit_transform(X)
PSI 值在 psi_values_ 属性中提供。
transformer.psi_values_
{'var_0': 0.06485778974895254,
'var_1': 0.03605540598761757,
'var_2': 0.040632784917352296,
'var_3': 0.023845405645510645,
'var_4': 0.028007185972248064,
'var_5': 0.07009152672971862,
'group_means': 6.601444547497699,
'shifted_feature': 0.48428009522119164}
从这些值中我们可以看出,最后两个特征应该被移除。我们可以在 features_to_drop_ 属性中得到证实:
transformer.features_to_drop_
['group_means', 'shifted_feature']
并且这些列通过转换方法从原始数据框中移除,在本例中,该方法通过上面几行单元格中的 fit_transform 方法应用。
X_transformed.columns
Index(['var_0', 'var_1', 'var_2', 'var_3', 'var_4', 'var_5', 'group'], dtype='object')
分割传递一个类别列表#
我们可以将一个值列表传递给 cut_off,而不是传递一个类别值。使用相同的数据集,让我们设置 DropHighPSIFeatures() 根据类别变量 group 的列表 [‘A’, ‘C’, ‘E’] 来分割数据框。
在这种情况下,PSI 将通过比较两个数据框来计算:第一个数据框仅包含 group 变量的值 A、C 和 E,第二个数据框仅包含值 B 和 D。
trans = DropHighPSIFeatures(split_col='group', cut_off=['A', 'C', 'E'])
X_no_drift = trans.fit_transform(X)
trans.psi_values_
'var_0': 0.04322345673014104,
'var_1': 0.03534439253617049,
'var_2': 0.05220272785661243,
'var_3': 0.04550964862452317,
'var_4': 0.04492720670343145,
'var_5': 0.044886435640028144,
'group_means': 6.601444547497699,
'shifted_features': 0.3683642099948127}
这里再次,对象将从数据框中移除 group_means 和 shifted_features 列。
trans.features_to_drop_
['group_means', 'shifted_features']
并且这些列通过应用了 fit_transform 方法的转换方法从原始数据框中移除。
X_transformed.columns
Index(['var_0', 'var_1', 'var_2', 'var_3', 'var_4', 'var_5', 'group'], dtype='object')
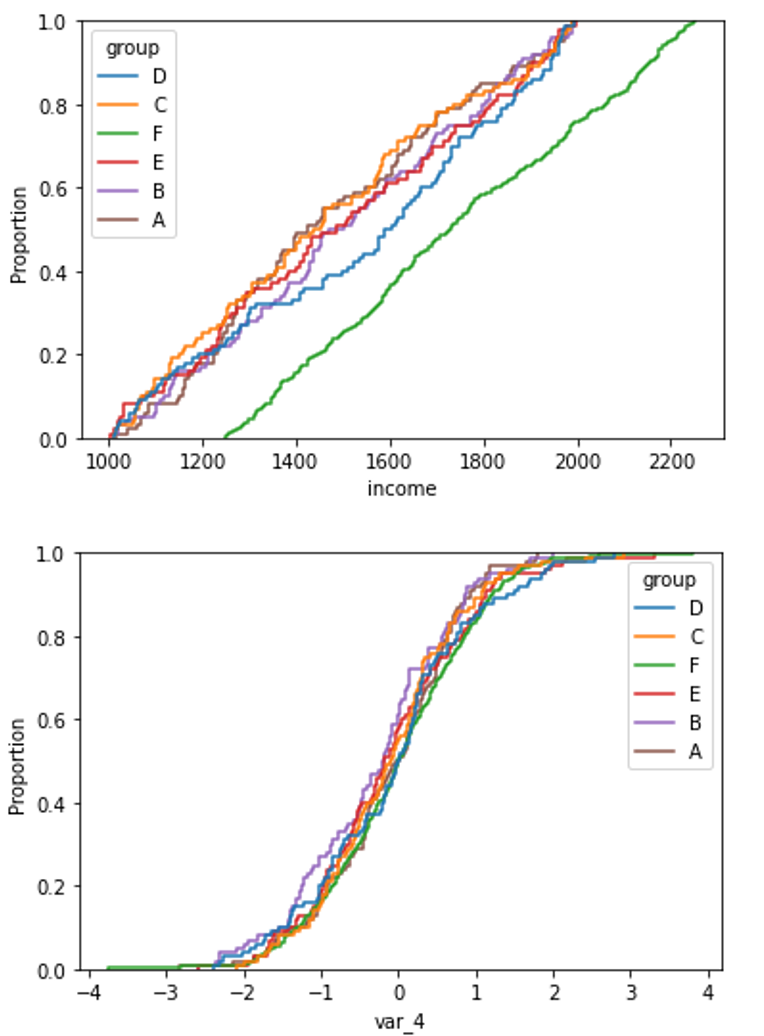
在以下图表中,我们可以比较具有高PSI和低PSI的特征在分类变量的不同类别中的分布。
通过这段代码,我们绘制了一个特征的累积分布图,该特征在不同变量类别中的分布是不同的:
sns.ecdfplot(data=X, x='shifted_feature', hue='group')
通过这段代码,我们绘制了一个特征的累积分布图,该特征在分类变量的不同类别中具有相同的分布:
sns.ecdfplot(data=X, x='var_0', hue='group')
下面我们可以比较这两个特征的图表:

案例 5:基于唯一值拆分数据 (split_distinct)#
前一个示例的一个变体是使用 split_distinct 功能。在这种情况下,分割不是基于 split_col 中的观察次数,而是基于 split_col 中指示的参考变量的不同值的数量。
一个实际生活中的例子是处理不同大小的组,比如客户收入类别(’1000’, ‘2000’, ‘3000’, ‘4000’, …)。split_distinct 允许控制基础和测试数据框中的类别数量,而不管每个类别中的观察数量。
这个案例在为本案例准备的玩具数据中得到了说明。数据集包含6个随机变量和一个收入变量,该收入变量在定义的6个组中的一个组(F组)中较大。
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.datasets import make_classification
from feature_engine.selection import DropHighPSIFeatures
X, y = make_classification(
n_samples=1000,
n_features=6,
random_state=0
)
colnames = ["var_" + str(i) for i in range(6)]
X = pd.DataFrame(X, columns=colnames)
# Add a categorical column
X['group'] = ["A", "B", "C", "D", "E"] * 100 + ["F"] * 500
# And an income variable that is category dependent.
np.random.seed(0)
X['income'] = np.random.uniform(1000, 2000, 500).tolist() +
np.random.uniform(1250, 2250, 500).tolist()
# Shuffle the dataframe to make the dataset more real life case.
X = X.sample(frac=1).reset_index(drop=True)
group 列包含 (A, B, C, D, E) 组的 500 个观测值和 (F) 组的 500 个观测值。
当我们在初始化 DropHighPSIFeatures 对象时传递 split_distinct=True,用于计算 PSI 的两个数据框将在 group 列中包含相同数量的 唯一 值(即,一个数据框将包含与组 A、B 和 C 相关的 300 行,而另一个数据框将包含与组 D、E 和 F 相关的 700 行)。
transformer = DropHighPSIFeatures(split_col='group', split_distinct=True)
transformer.fit(X)
transformer.psi_values_
这将产生以下PSI值:
{'var_0': 0.014825303242393804,
'var_1': 0.03818316821350485,
'var_2': 0.029635981271458896,
'var_3': 0.021700399485890084,
'var_4': 0.061194837255216114,
'var_5': 0.04119583769297253,
'income': 0.46191580731264914}
我们在这里可以找到将要被移除的特性,收入:
transformer.features_to_drop_
['income']
调用 transform() 方法时,前一个特征将从数据集中移除。
X_transformed = transformer.transform(X)
X_transformed.columns
Index(['var_0', 'var_1', 'var_2', 'var_3', 'var_4', 'var_5', 'group'], dtype='object')
在绘制每个组的累积密度函数时,非移位分布与移位分布之间的分布差异清晰可见。
对于偏移变量(收入):
sns.ecdfplot(data=X, x='income', hue='group')
以及一个未移位的变量(例如 var_4)
sns.ecdfplot(data=X, x="var_4", hue="group")
其他资源#
在这个笔记本中,我们展示了如何在一个真实数据集上使用 DropHighPSIFeatures ,并提供了关于用于确定PSI的基础和参考子数据帧的更多细节。
所有笔记本都可以在 专用仓库 中找到。
有关此功能选择方法及其他方法的更多详细信息,请查看以下资源:

机器学习的特征选择#
或者阅读我们的书:

机器学习中的特征选择#
我们的书籍和课程都适合初学者和更高级的数据科学家。通过购买它们,您正在支持 Feature-engine 的主要开发者 Sole。