特征选择#
Feature-engine 的特征选择转换器识别预测性能较低的特征,并将其从数据集中删除。Feature-engine 支持的大多数特征选择算法在其他库中尚不可用。这些算法已从数据科学竞赛中收集或用于行业中。
选择机制概述#
Feature-engine 的转换器根据不同的策略选择特征。
第一种策略评估特征的内在特性,如它们的分布。例如,我们可以移除常量或准常量特征。或者我们可以通过使用人口稳定指数来移除在时间上分布不稳定的特征。
第二种策略是确定特征之间的关系。在这些关系中,我们可以移除重复或相关的特征。
我们也可以根据特征与目标的关系来选择特征。为了评估这一点,我们可以用目标均值替换特征值,或者计算信息值。
一些特征选择过程涉及训练机器学习模型。我们可以通过各种算法单独或集体评估特征,如下图所示:
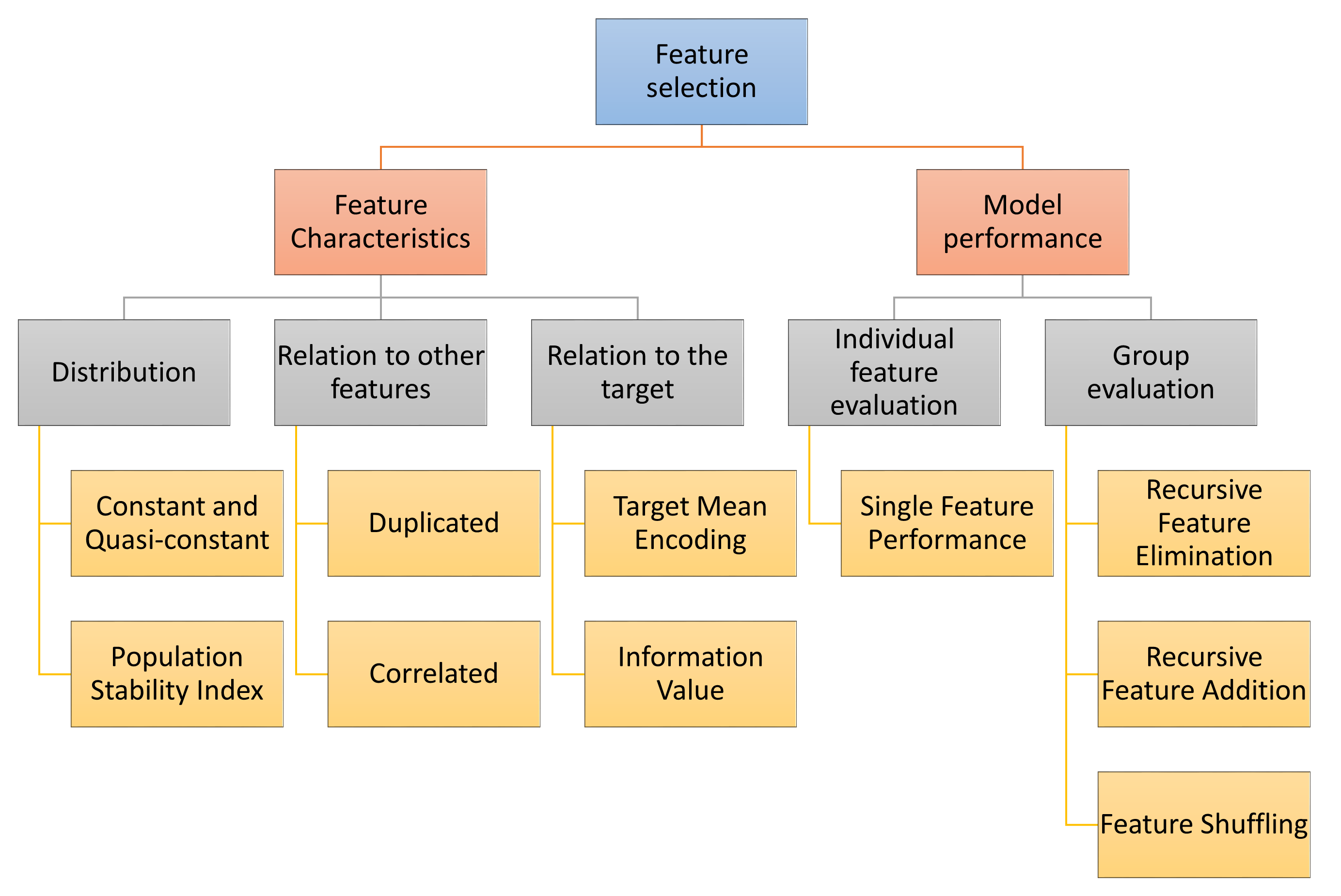
选择机制 - 概述#
基于变量组中特征性能选择特征的算法,通常会用所有特征训练一个模型,然后移除、添加或打乱一个特征并重新评估模型性能。
这些方法通常旨在提高最终机器学习模型的整体性能,以及减少特征空间。
选择器特性概览#
Feature-engine 的一些选择器可以直接处理分类变量和/或允许变量中存在缺失数据。这为您在进入任何特征工程之前快速筛选特征提供了机会。
在以下表格中,我们突出了 Feature-engine 选择器的主要特性:
基于特征特性的选择#
Transformer |
分类变量 |
允许 NA |
描述 |
|---|---|---|---|
√ |
√ |
根据用户决定,丢弃任意功能 |
|
√ |
√ |
删除常量和准常量特征 |
|
√ |
√ |
删除重复的功能 |
|
× |
√ |
删除相关功能 |
|
× |
√ |
从一个相关的特征组中删除不太有用的特征 |
确定重复项或唯一值数量的方法,可以同时处理数值和分类变量,并且也支持缺失数据。
基于相关性的选择程序仅适用于数值变量,但允许缺失数据。
基于机器学习模型的选择#
Transformer |
分类变量 |
允许 NA |
描述 |
|---|---|---|---|
× |
× |
基于单特征模型性能选择特征 |
|
|
× |
× |
通过评估模型性能递归地移除特征 |
|
× |
× |
通过评估模型性能递归地添加功能 |
需要从Scikit-learn训练机器学习模型的选择程序要求数值变量且无缺失数据。
金融中常用的选择方法#
Transformer |
分类变量 |
允许 NA |
描述 |
|---|---|---|---|
× |
√ |
删除具有高人口稳定指数的特征 |
|
√ |
x |
删除信息价值低的功能 |
DropHighPSIFeatures() 允许移除分布发生变化的特征。这是通过将输入数据框分成两部分,并比较两部分中每个特征的分布来完成的。用于评估分布变化的指标是人口稳定指数(PSI)。移除不稳定的特征可能会导致更稳健的模型。在信用风险建模等领域,监管机构通常要求最终特征集的PSI低于给定的阈值。
替代特征选择方法#
Transformer |
分类变量 |
允许 NA |
描述 |
|---|---|---|---|
× |
× |
选择特征如果打乱其值会导致模型性能下降 |
|
√ |
× |
使用目标均值作为性能代理,选择高性能特征 |
|
× |
× |
选择重要性高于随机变量的特征 |
该 SelectByTargetMeanPerformance() 使用目标均值作为预测的代理,通过这些值替换类别或变量区间,然后确定一个性能指标。因此,它适用于分类变量和数值变量。在其当前实现中,它不支持缺失数据。
该 ProbeFeatureSelection() 向数据集中引入随机变量,然后创建模型并推导特征重要性。它选择所有重要性大于随机特征平均重要性的变量。
在用户指南的其余部分,您将找到关于每个特征选择过程的更多详细信息。
特征选择算法#
点击下方以了解更多关于如何使用每个变压器的详细信息。

