DropConstantFeatures#
常量特征是那些显示零变异性的变量,换句话说,在所有行中具有相同的值。训练机器学习模型的关键步骤之一是识别并移除这些常量特征。
几乎没有或低变异性的特征很少构成有用的预测因子。因此,在数据科学项目的开始阶段移除这些特征是简化数据集和后续数据预处理流程的好方法。
过滤方法是一种选择算法,它们仅根据特征的特性来选择或移除特征。从这个角度来看,移除常量特征可以被视为选择算法中的过滤组的一部分。
在Python中,我们可以通过使用pandas的 std 或 unique 方法来找到常量特征,然后使用 drop 方法移除它们。
使用 Scikit-learn,我们可以通过 VarianceThreshold 找到并移除常量变量,从而快速减少特征数量。VarianceThreshold 是 sklearn.feature_selection 的 API 的一部分。
然而,VarianceThreshold 只能处理数值变量。因此,我们只能在编码后评估分类变量,这需要一个先前的数据预处理步骤来去除冗余变量。
Feature-engine 引入了 DropConstantFeatures() 来查找并从数据框中移除常量和准常量特征。DropConstantFeatures() 适用于数值、分类或日期时间变量。因此,它比 Scikit-learn 的转换器更具多功能性,因为它允许我们在不需要先进行数据转换的情况下删除所有重复变量。
默认情况下,DropConstantFeatures() 会删除常量变量。我们还可以选择删除准常量特征,这些特征在大多数情况下显示为常量值,并且在极少数行中显示其他值。
因为 DropConstantFeatures() 同样适用于数值和分类变量,它提供了一种直接减少特征子集的方法。
不过,要注意的是,根据上下文,准常量变量可能会有用。
示例
让我们看看如何使用 DropConstantFeatures() 通过使用泰坦尼克号数据集。这个数据集不包含常量或准常量变量,因此为了演示的目的,我们将那些在超过70%的行中显示相同值的特征视为准常量。
我们首先加载数据,并将其分为训练集和测试集:
from sklearn.model_selection import train_test_split
from feature_engine.datasets import load_titanic
from feature_engine.selection import DropConstantFeatures
X, y = load_titanic(
return_X_y_frame=True,
handle_missing=True,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0,
)
现在,我们设置 DropConstantFeatures() 以移除在超过70%的观察中显示相同值的特征。我们通过参数 tol 来实现这一点。该参数的默认值为零,在这种情况下,它将移除常量特征。
# set up the transformer
transformer = DropConstantFeatures(tol=0.7)
通过 fit() 方法,转换器会找到需要丢弃的变量:
# fit the transformer
transformer.fit(X_train)
要删除的变量存储在属性 features_to_drop_ 中。
transformer.features_to_drop_
['parch', 'cabin', 'embarked', 'body']
我们可以检查变量 parch 和 embarked 在超过 70% 的观察中显示相同值,如下所示:
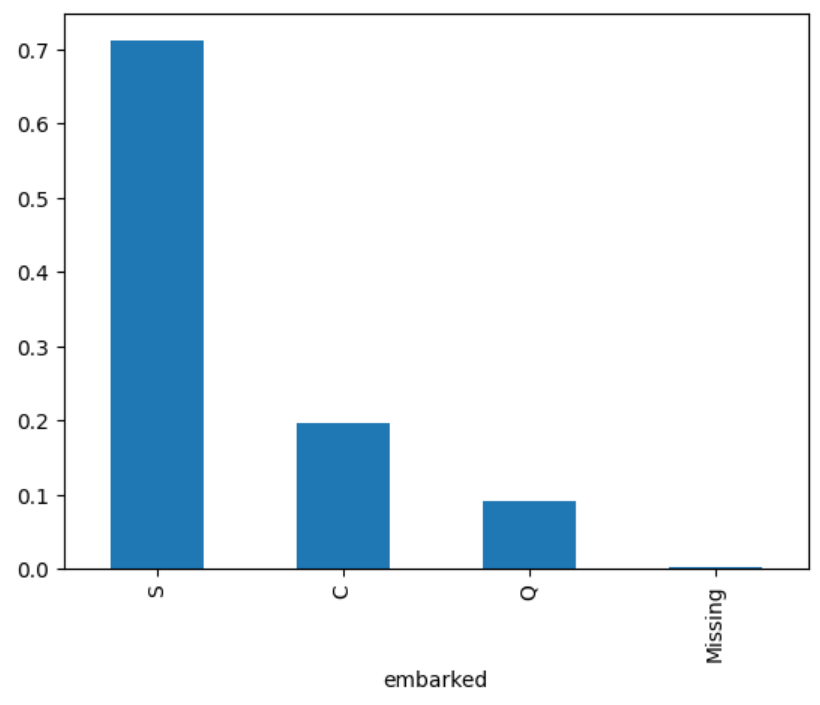
X_train['embarked'].value_counts(normalize = True)
S 0.711790
C 0.195415
Q 0.090611
Missing 0.002183
Name: embarked, dtype: float64
根据之前的结果,71%的乘客在S港登船。
现在让我们评估 parch:
X_train['parch'].value_counts(normalize = True)
0 0.771834
1 0.125546
2 0.086245
3 0.005459
4 0.004367
5 0.003275
6 0.002183
9 0.001092
Name: parch, dtype: float64
基于之前的结果,77% 的乘客没有父母或子女。因此,这些特征被认为是准常量,将在下一步中被移除。
我们也可以如下识别准常量变量:
import pandas
X_train["embarked"].value_counts(normalize=True).plot.bar()
执行完前面的代码后,我们观察到以下图表,超过70%的乘客在S地登船:
通过 transform(),我们从数据集中删除了准常量变量:
train_t = transformer.transform(X_train)
test_t = transformer.transform(X_test)
print(train_t.head())
我们在下面看到生成的数据框:
pclass name sex age sibsp \
501 2 Mellinger, Miss. Madeleine Violet female 13.000000 0
588 2 Wells, Miss. Joan female 4.000000 1
402 2 Duran y More, Miss. Florentina female 30.000000 1
1193 3 Scanlan, Mr. James male 29.881135 0
686 3 Bradley, Miss. Bridget Delia female 22.000000 0
ticket fare boat \
501 250644 19.5000 14
588 29103 23.0000 14
402 SC/PARIS 2148 13.8583 12
1193 36209 7.7250 Missing
686 334914 7.7250 13
home.dest
501 England / Bennington, VT
588 Cornwall / Akron, OH
402 Barcelona, Spain / Havana, Cuba
1193 Missing
686 Kingwilliamstown, Co Cork, Ireland Glens Falls...
与 sklearn 类似,Feature-engine 转换器具有 fit_transform 方法,该方法允许我们在一行代码中方便地查找并移除常量或准常量变量。
与 sklearn 类似,DropConstantFeatures() 也有 get_support() 方法,该方法返回一个向量,其中包含保留特征的 True 值和将被删除特征的 False 值。
transformer.get_support()
[True, True, True, True, True, False, True, True, False, False,
True, False, True]
这种及其他特征选择方法未必能避免过拟合,但它们有助于简化我们的机器学习流程,并创建更具解释性的机器学习模型。
附加资源#
在这个 Kaggle 内核中,我们使用 DropConstantFeatures() 与其他特征选择算法一起,然后训练一个逻辑回归估计器:
有关此功能选择方法及其他方法的更多详细信息,请查看以下资源:

机器学习的特征选择#
或者阅读我们的书:

机器学习中的特征选择#
我们的书籍和课程都适合初学者和更高级的数据科学家。通过购买它们,您正在支持 Feature-engine 的主要开发者 Sole。