递归特征消除#
RecursiveFeatureElimination 实现了递归特征消除。递归特征消除(RFE)是一个反向特征选择过程。
在 Feature-engine 的 RFE 实现中,一个特征将被保留或移除,基于该特征添加到机器学习模型后对模型性能的影响。这与 Scikit-learn 的 RFE 实现不同,后者根据机器学习模型通过其系数参数或 ‘feature_importances_’ 属性得出的特征重要性来决定特征的保留或移除。
Feature-engine 的 RFE 实现首先在整个变量集上训练一个模型,并存储其性能值。基于同一模型,RecursiveFeatureElimination 通过 coef_ 或 feature_importances_ 属性推导出特征重要性,这取决于它是一个线性模型还是基于树的算法。这些特征重要性值用于按性能递增排序特征,以确定特征将被递归移除的顺序。最不重要的特征首先被移除。
在下一步中,RecursiveFeatureElimination 移除最不重要的特征,并使用剩余的变量训练一个新的机器学习模型。如果这个模型的性能比前一个模型的性能差,那么,该特征被保留(因为移除该特征导致了模型性能的下降),否则,它被移除。
RecursiveFeatureElimination 现在移除第二不重要的特征,训练一个新模型,将其性能与之前的模型进行比较,决定是否移除或保留该特征,并继续处理下一个变量,直到评估数据集中的所有特征。
需要注意的是,在 Feature-engine 的 RFE 实现中,特征重要性仅用于对特征进行排序,从而确定特征被剔除的顺序。但是否保留某个特征是基于特征剔除后模型性能的下降来决定的。
通过递归地消除特征,RFE 试图消除模型中可能存在的依赖性和共线性。
参数#
递归特征消除 有两个参数需要用户在一定程度上任意确定:第一个是将被评估性能的机器学习模型。第二个是性能下降的阈值,需要达到该阈值才能移除一个特征。
RFE 不是与机器学习模型无关的,这意味着特征选择取决于模型,不同的模型可能会有不同的最优特征子集。因此,建议您使用最终打算构建的机器学习模型。
关于阈值,这个参数需要一些手动调整。较高的阈值将返回较少的特征。
Python 示例#
让我们看看如何使用这个转换器与Scikit-learn中的糖尿病数据集。首先,我们加载数据:
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from feature_engine.selection import RecursiveFeatureElimination
# load dataset
X, y = load_diabetes(return_X_y=True, as_frame=True)
print(X.head())
在以下输出中,我们看到了糖尿病数据集:
age sex bmi bp s1 s2 s3 \
0 0.038076 0.050680 0.061696 0.021872 -0.044223 -0.034821 -0.043401
1 -0.001882 -0.044642 -0.051474 -0.026328 -0.008449 -0.019163 0.074412
2 0.085299 0.050680 0.044451 -0.005670 -0.045599 -0.034194 -0.032356
3 -0.089063 -0.044642 -0.011595 -0.036656 0.012191 0.024991 -0.036038
4 0.005383 -0.044642 -0.036385 0.021872 0.003935 0.015596 0.008142
s4 s5 s6
0 -0.002592 0.019907 -0.017646
1 -0.039493 -0.068332 -0.092204
2 -0.002592 0.002861 -0.025930
3 0.034309 0.022688 -0.009362
4 -0.002592 -0.031988 -0.046641
现在,我们设置 RecursiveFeatureElimination 以基于线性回归模型返回的 r2 选择特征,使用 3 折交叉验证。在这种情况下,我们将参数 threshold 保留为默认值 0.01。
# initialize linear regresion estimator
linear_model = LinearRegression()
# initialize feature selector
tr = RecursiveFeatureElimination(estimator=linear_model, scoring="r2", cv=3)
使用 fit() 方法,模型会找到最有用的特征,即那些在移除后导致模型性能下降超过 0.01 的特征。使用 transform() 方法,转换器会从数据集中移除这些特征。
Xt = tr.fit_transform(X, y)
print(Xt.head())
通过线性回归的递归特征消除,确定了六个重要的特征:
sex bmi bp s1 s2 s5
0 0.050680 0.061696 0.021872 -0.044223 -0.034821 0.019907
1 -0.044642 -0.051474 -0.026328 -0.008449 -0.019163 -0.068332
2 0.050680 0.044451 -0.005670 -0.045599 -0.034194 0.002861
3 -0.044642 -0.011595 -0.036656 0.012191 0.024991 0.022688
4 -0.044642 -0.036385 0.021872 0.003935 0.015596 -0.031988
RecursiveFeatureElimination 在其属性中存储了使用所有特征训练的模型的性能:
# get the initial linear model performance, using all features
tr.initial_model_performance_
在以下输出中,我们看到了在整个数据集上训练的线性回归的性能:
0.488702767247119
评估特征重要性#
线性回归的系数用于确定初始特征重要性评分,该评分用于在应用递归消除过程之前对特征进行排序。我们可以如下检查特征重要性:
tr.feature_importances_
在以下输出中,我们看到了从线性模型中得出的特征重要性:
age 41.418041
s6 64.768417
s3 113.965992
s4 182.174834
sex 238.619526
bp 322.091802
s2 436.671584
bmi 522.330165
s5 741.471337
s1 750.023872
dtype: float64
特征重要性是通过交叉验证获得的,因此 递归特征消除 也存储了特征重要性的标准差:
tr.feature_importances_std_
在以下输出中,我们看到了特征重要性的标准差:
age 18.217152
sex 68.354719
bmi 86.030698
bp 57.110383
s1 329.375819
s2 299.756998
s3 72.805496
s4 47.925822
s5 117.829949
s6 42.754774
dtype: float64
选择过程基于移除一个特征是否会降低模型的性能,相比于包含该特征的同一模型。我们可以如下检查性能变化:
# Get the performance drift of each feature
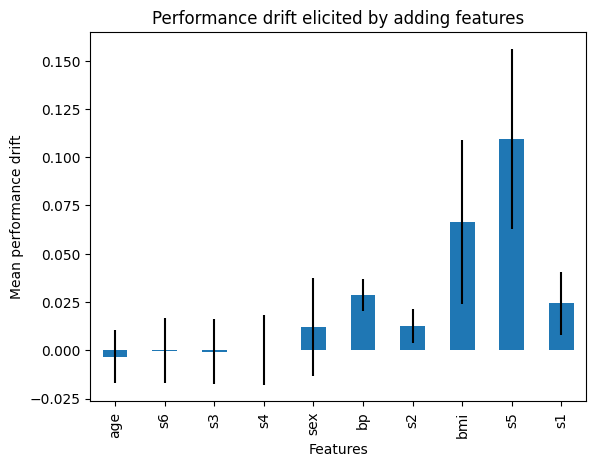
tr.performance_drifts_
在以下输出中,我们看到了通过移除每个特征返回的性能变化:
{'age': -0.0032800993162502845,
's6': -0.00028194870232089997,
's3': -0.0006751427734088544,
's4': 0.00013890056776355575,
'sex': 0.01195652626644067,
'bp': 0.02863360798239445,
's2': 0.012639242239088355,
'bmi': 0.06630359039334816,
's5': 0.10937354113435072,
's1': 0.024318355833473526}
我们还可以检查性能漂移的标准差:
# Get the performance drift of each feature
tr.performance_drifts_std_
在以下输出中,我们看到了通过消除每个特征后返回的性能变化的标准差:
{'age': 0.013642261032787014,
's6': 0.01678934235354838,
's3': 0.01685859860738229,
's4': 0.017977817100713972,
'sex': 0.025202392033518706,
'bp': 0.00841776123355417,
's2': 0.008676750772593812,
'bmi': 0.042463565656018436,
's5': 0.046779680487815146,
's1': 0.01621466049786452}
我们现在可以用标准差绘制性能变化,以识别重要特征:
r = pd.concat([
pd.Series(tr.performance_drifts_),
pd.Series(tr.performance_drifts_std_)
], axis=1
)
r.columns = ['mean', 'std']
r['mean'].plot.bar(yerr=[r['std'], r['std']], subplots=True)
plt.title("Performance drift elicited by adding features")
plt.ylabel('Mean performance drift')
plt.xlabel('Features')
plt.show()
在下图中,我们可以看到从模型中移除每个特征后性能的变化:
为了比较,我们可以将线性回归得出的特征重要性与标准差一起绘制:
r = pd.concat([
tr.feature_importances_,
tr.feature_importances_std_,
], axis=1
)
r.columns = ['mean', 'std']
r['mean'].plot.bar(yerr=[r['std'], r['std']], subplots=True)
plt.title("Feature importance derived from the linear regression")
plt.ylabel('Coefficients value')
plt.xlabel('Features')
plt.show()
在下图中,我们看到了由线性回归系数确定的功能重要性:
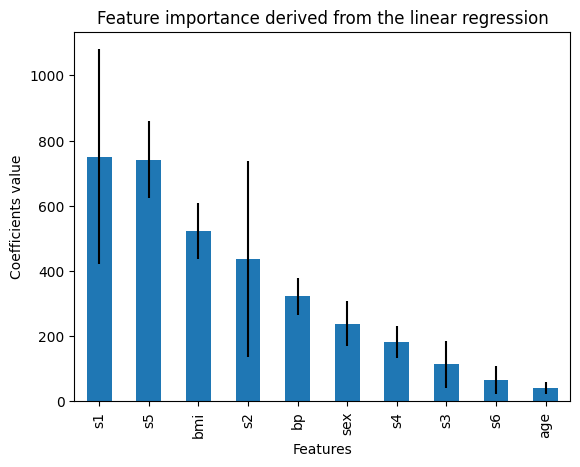
通过比较两个图表中的表现,我们可以开始理解哪些特征是重要的,以及哪些特征可能与其他数据中的变量显示出某种相关性。如果一个特征具有相对较大的系数,但移除它并不会改变模型性能,那么它可能与数据中的另一个变量相关。
查看被淘汰的功能#
RecursiveFeatureElimination 还会存储基于给定阈值将被丢弃的特征。
# the features to remove
tr.features_to_drop_
这些功能未被RFE流程视为重要:
['age', 's3', 's4', 's6']
RecursiveFeatureElimination 也有 get_support() 方法,其工作方式与 Scikit-learn 的特征选择类完全相同:
tr.get_support()
输出中,选中的特性为 True,将被丢弃的特性为 False:
[False, True, True, True, True, True, False, False, True, False]
就是这样!你现在知道如何通过递归地移除特征来选择数据集中的特征了。

