SelectByShuffling#
SelectByShuffling() 选择那些随机值排列会降低模型性能的特征。如果一个特征具有预测性,将其值在各行之间打乱会导致预测结果与实际结果显著偏离。相反,如果该特征不具有预测性,改变其值的顺序对模型的预测几乎没有影响。
程序#
该算法操作如下:
使用所有可用特征训练机器学习模型。
为模型建立一个基准性能指标。
在保持所有其他特征不变的情况下,打乱单个特征的值。
使用步骤1中的模型,通过打乱特征来生成预测。
基于这些新的预测来衡量模型的性能。
如果性能下降超过预定义的阈值,保留该功能。
对每个功能重复步骤3-6,直到所有功能都被评估。
Python 示例#
让我们看看如何使用 SelectByShuffling() 与 Scikit-learn 自带的糖尿病数据集。首先,我们加载数据:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from feature_engine.selection import SelectByShuffling
X, y = load_diabetes(return_X_y=True, as_frame=True)
print(X.head())
在以下输出中,我们看到了糖尿病数据集:
age sex bmi bp s1 s2 s3 \
0 0.038076 0.050680 0.061696 0.021872 -0.044223 -0.034821 -0.043401
1 -0.001882 -0.044642 -0.051474 -0.026328 -0.008449 -0.019163 0.074412
2 0.085299 0.050680 0.044451 -0.005670 -0.045599 -0.034194 -0.032356
3 -0.089063 -0.044642 -0.011595 -0.036656 0.012191 0.024991 -0.036038
4 0.005383 -0.044642 -0.036385 0.021872 0.003935 0.015596 0.008142
s4 s5 s6
0 -0.002592 0.019907 -0.017646
1 -0.039493 -0.068332 -0.092204
2 -0.002592 0.002861 -0.025930
3 0.034309 0.022688 -0.009362
4 -0.002592 -0.031988 -0.046641
现在,我们设置一个机器学习模型。我们将使用线性回归:
linear_model = LinearRegression()
现在,我们设置 SelectByShuffling() 通过打乱来选择特征。我们将使用3折交叉验证来检查 r2 的变化。
参数 threshold 被保留为 None,这意味着如果性能下降大于所有特征引起的平均下降,则会选择特征。
tr = SelectByShuffling(
estimator=linear_model,
scoring="r2",
cv=3,
random_state=0,
)
fit`() 方法识别重要变量——那些值的排列会导致模型性能下降的变量。`transform() 方法随后从数据集中移除这些变量。
Xt = tr.fit_transform(X, y)
SelectByShuffling() 存储了使用所有特征训练的模型的性能在其属性中:
tr.initial_model_performance_
在以下输出中,我们看到了在整个数据集上训练和评估的线性回归的 r2,没有进行洗牌,使用了交叉验证。
0.488702767247119
在以下部分中,我们将探讨 SelectByShuffling() 存储的一些额外有用的数据。
评估特征重要性#
SelectByShuffling() 存储了通过打乱每个特征引起的模型性能变化。
tr.performance_drifts_
在以下输出中,我们可以看到在打乱每个特征后线性回归r2的变化:
{'age': -0.0054698043007869734,
'sex': 0.03325633986510784,
'bmi': 0.184158237207512,
'bp': 0.10089894421748086,
's1': 0.49324432634948095,
's2': 0.21163252880660438,
's3': 0.02006839198785859,
's4': 0.011098050006761673,
's5': 0.4828781996541602,
's6': 0.003963360084439538}
SelectByShuffling() 存储了性能变化的标准差:
tr.performance_drifts_std_
在以下输出中,我们看到了特征洗牌后r2变化的多样性:
{'age': 0.012788500580799392,
'sex': 0.040792331972680645,
'bmi': 0.042212436355346106,
'bp': 0.05397012536801143,
's1': 0.35198797776358015,
's2': 0.167636042355086,
's3': 0.03455158514716544,
's4': 0.007755675852874145,
's5': 0.1449579162698361,
's6': 0.011193022434166025}
我们可以将性能变化与标准差一起绘制,以更好地了解特征洗牌如何影响模型性能:
r = pd.concat([
pd.Series(tr.performance_drifts_),
pd.Series(tr.performance_drifts_std_)
], axis=1
)
r.columns = ['mean', 'std']
r['mean'].plot.bar(yerr=[r['std'], r['std']], subplots=True)
plt.title("Performance drift elicited by shuffling a feature")
plt.ylabel('Mean performance drift')
plt.xlabel('Features')
plt.show()
在下图中,我们看到了通过打乱每个特征所导致的性能变化:
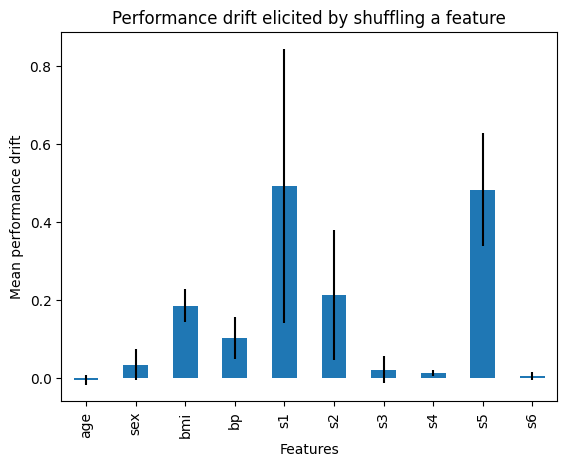
通过此设置,导致平均性能下降大于所有特征的平均性能的特征将被移除。如果由于任何原因,此阈值过于保守或过于宽松,通过分析之前的条形图,您可以更好地了解这些特征如何影响模型的预测,并选择不同的阈值。
检查已淘汰的功能#
SelectByShuffling() 存储了基于某个阈值将被丢弃的特征:
tr.features_to_drop_
以下特性被认为不重要,因为它们的表现漂移大于所有特性的平均表现漂移:
['age', 'sex', 'bp', 's3', 's4', 's6']
如果我们现在打印转换后的数据,我们可以看到上述特征已被移除。
print(Xt.head())
在以下输出中,我们看到了包含所选特征的数据框:
bmi s1 s2 s5
0 0.061696 -0.044223 -0.034821 0.019907
1 -0.051474 -0.008449 -0.019163 -0.068332
2 0.044451 -0.045599 -0.034194 0.002861
3 -0.011595 0.012191 0.024991 0.022688
4 -0.036385 0.003935 0.015596 -0.031988

