DuckDB的Python客户端可以直接在Jupyter笔记本中使用,无需额外配置。 然而,可以使用额外的库来简化SQL查询的开发。 本指南将描述如何利用这些额外的库。 有关如何将DuckDB与Python一起使用的更多信息,请参阅Python部分的其他指南。
在这个例子中,我们使用了JupySQL包。
此示例工作流程也可作为Google Colab笔记本使用。
库安装
四个额外的库提升了DuckDB在Jupyter笔记本中的体验。
- jupysql: 将Jupyter代码单元格转换为SQL单元格
- Pandas: 清理表格可视化并与其他分析兼容
- matplotlib: 使用Python进行绘图
- duckdb-engine (DuckDB SQLAlchemy 驱动): 由 SQLAlchemy 用于连接 DuckDB(可选)
如果尚未安装Jupyter Notebook,请从命令行运行这些pip install命令。否则,请参阅上面的Google Colab链接以获取笔记本中的示例:
pip install duckdb
安装 Jupyter Notebook
pip install notebook
或者 JupyterLab:
pip install jupyterlab
安装支持库:
pip install jupysql pandas matplotlib duckdb-engine
库导入和配置
打开一个Jupyter Notebook并导入相关的库。
原生连接DuckDB
要连接到DuckDB,请运行:
import duckdb
import pandas as pd
%load_ext sql
conn = duckdb.connect()
%sql conn --alias duckdb
通过SQLAlchemy使用duckdb_engine连接到DuckDB
或者,您可以使用duckdb_engine通过SQLAlchemy连接到DuckDB。请参阅性能和功能差异。
import duckdb
import pandas as pd
# No need to import duckdb_engine
# jupysql will auto-detect the driver needed based on the connection string!
# Import jupysql Jupyter extension to create SQL cells
%load_ext sql
在jupysql上设置配置,以直接将数据输出到Pandas,并简化打印到笔记本的输出。
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
使用SQLAlchemy风格的连接字符串将jupysql连接到DuckDB。 可以连接到新的内存中的DuckDB、默认连接或文件支持的数据库:
%sql duckdb:///:memory:
%sql duckdb:///:default:
%sql duckdb:///path/to/file.db
如果您提供
duckdb:///:default:作为SQLAlchemy连接字符串,%sql命令和duckdb.sql共享相同的默认连接。
查询 DuckDB
单行SQL查询可以在行首使用%sql来运行。查询结果将显示为Pandas DataFrame。
%sql SELECT 'Off and flying!' AS a_duckdb_column;
通过在单元格的开头放置%%sql,整个Jupyter单元格可以用作SQL单元格。查询结果将显示为Pandas DataFrame。
%%sql
SELECT
schema_name,
function_name
FROM duckdb_functions()
ORDER BY ALL DESC
LIMIT 5;
要将查询结果存储在Python变量中,请使用<<作为赋值运算符。
这可以与%sql和%%sql Jupyter魔法一起使用。
%sql res << SELECT 'Off and flying!' AS a_duckdb_column;
如果设置了%config SqlMagic.autopandas = True选项,变量将是一个Pandas数据框,否则,它是一个可以使用DataFrame()函数转换为Pandas的ResultSet。
查询Pandas数据框
DuckDB 能够查找并查询存储在 Jupyter 笔记本中的任何数据框变量。
input_df = pd.DataFrame.from_dict({"i": [1, 2, 3],
"j": ["one", "two", "three"]})
被查询的数据框可以像FROM子句中的任何其他表一样指定。
%sql output_df << SELECT sum(i) AS total_i FROM input_df;
可视化DuckDB数据
在Python中绘制数据集的最常见方法是使用Pandas加载数据,然后使用matplotlib或seaborn进行绘图。 这种方法需要将所有数据加载到内存中,效率非常低。 JupySQL中的绘图模块在SQL引擎中运行计算。 这将内存管理委托给引擎,并确保中间计算不会持续占用内存,从而高效地绘制大规模数据集。
安装并加载DuckDB httpfs扩展
DuckDB的httpfs扩展允许通过http远程查询Parquet和CSV文件。 这些示例查询包含纽约市历史出租车数据的Parquet文件。 使用Parquet格式允许DuckDB仅将所需的行和列拉入内存,而不是下载整个文件。 DuckDB也可以用于处理本地的Parquet文件,这在查询整个Parquet文件或运行需要文件大部分数据的多个查询时可能更为理想。
%%sql
INSTALL httpfs;
LOAD httpfs;
箱线图 & 直方图
要创建一个箱线图,调用 %sqlplot boxplot,传递表的名称和要绘制的列。
在这种情况下,表的名称是远程存储的Parquet文件的URL。
%sqlplot boxplot --table https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet --column trip_distance
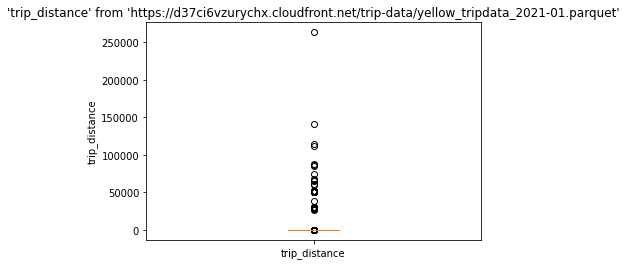
现在,创建一个按第90百分位数过滤的查询。
注意使用--save和--no-execute函数。
这告诉JupySQL存储查询,但跳过执行。它将在下一个绘图调用中被引用。
%%sql --save short_trips --no-execute
SELECT *
FROM 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet'
WHERE trip_distance < 6.3
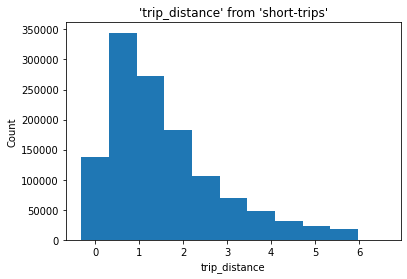
要创建直方图,请调用 %sqlplot histogram 并传递表的名称、要绘制的列以及分箱的数量。
这使用了 --with short-trips,因此 JupySQL 使用之前定义的查询,因此只绘制数据的子集。
%sqlplot histogram --table short_trips --column trip_distance --bins 10 --with short_trips
摘要
您现在可以以一种简单且高性能的方式在SQL和Pandas之间切换!您可以直接通过引擎绘制大规模数据集(避免下载整个文件并将其全部加载到内存中的Pandas)。数据框可以作为SQL中的表读取,SQL结果可以输出到数据框中。祝您分析愉快!