Vector 是用于在执行期间存储内存数据的容器格式。
DataChunk 是 Vector 的集合,用于表示 PhysicalProjection 操作符中的列列表。
数据流
DuckDB 使用向量化查询执行模型。 DuckDB 中的所有操作符都经过优化,以处理固定大小的向量。
这个固定大小在代码中通常被称为STANDARD_VECTOR_SIZE。
默认的STANDARD_VECTOR_SIZE是2048个元组。
向量格式
向量在逻辑上表示包含单一类型数据的数组。DuckDB支持不同的向量格式,这使得系统能够以不同的物理表示存储相同的逻辑数据。这允许更压缩的表示,并可能允许在整个系统中进行压缩执行。下面显示了支持的向量格式列表。
Flat Vectors
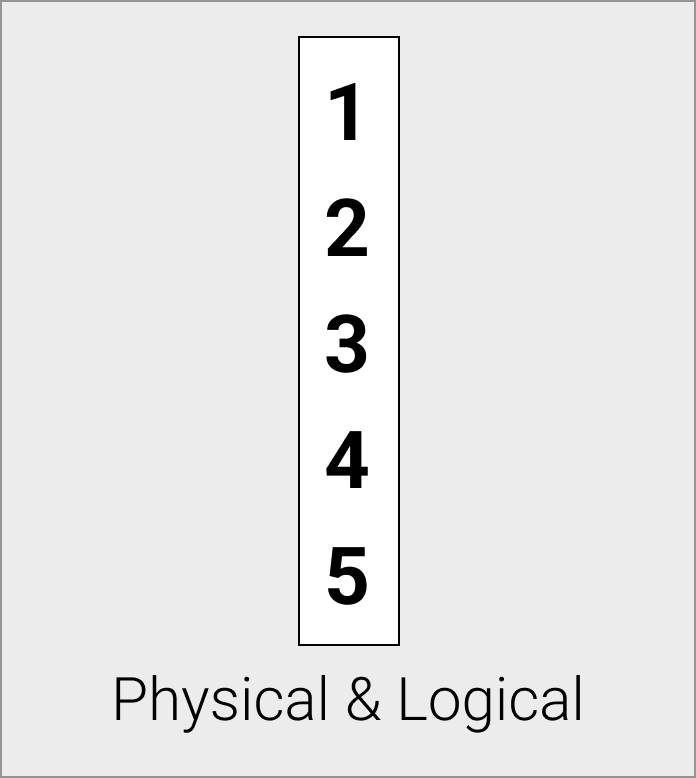
平面向量在物理上存储为一个连续的数组,这是标准的未压缩向量格式。 对于平面向量,逻辑表示和物理表示是相同的。
常量向量
常量向量在物理上存储为单个常量值。
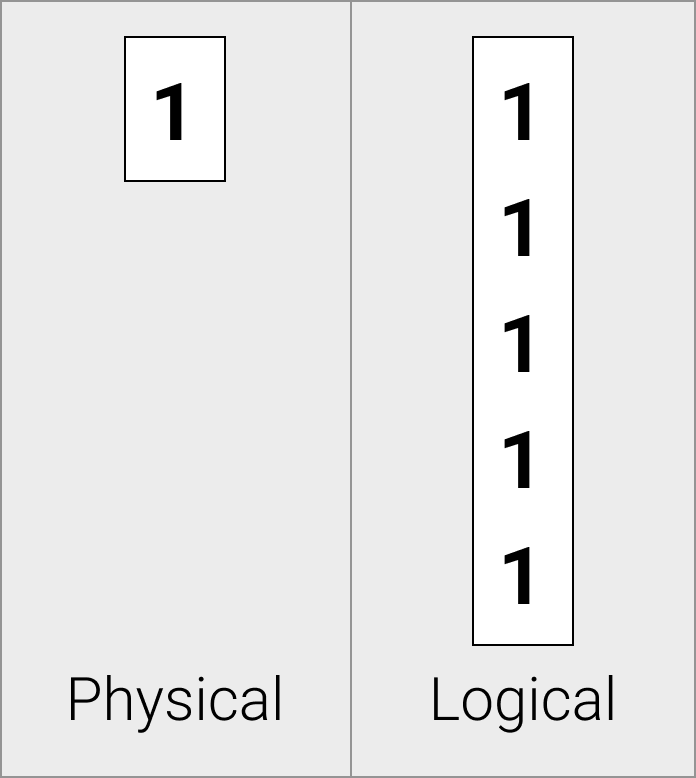
常量向量在数据元素重复时非常有用——例如,在表示函数调用中常量表达式的结果时,常量向量允许我们只存储一次值。
SELECT lst || 'duckdb'
FROM range(1000) tbl(lst);
由于 duckdb 是一个字符串字面量,该字面量的值对于每一行都是相同的。在平面向量中,我们不得不为每一行重复字面量 'duckdb'。常量向量允许我们只存储字面量一次。
在从常量压缩解压缩时,存储也会发出常量向量。
字典向量
字典向量在物理上存储为一个子向量,以及一个包含指向子向量索引的选择向量。
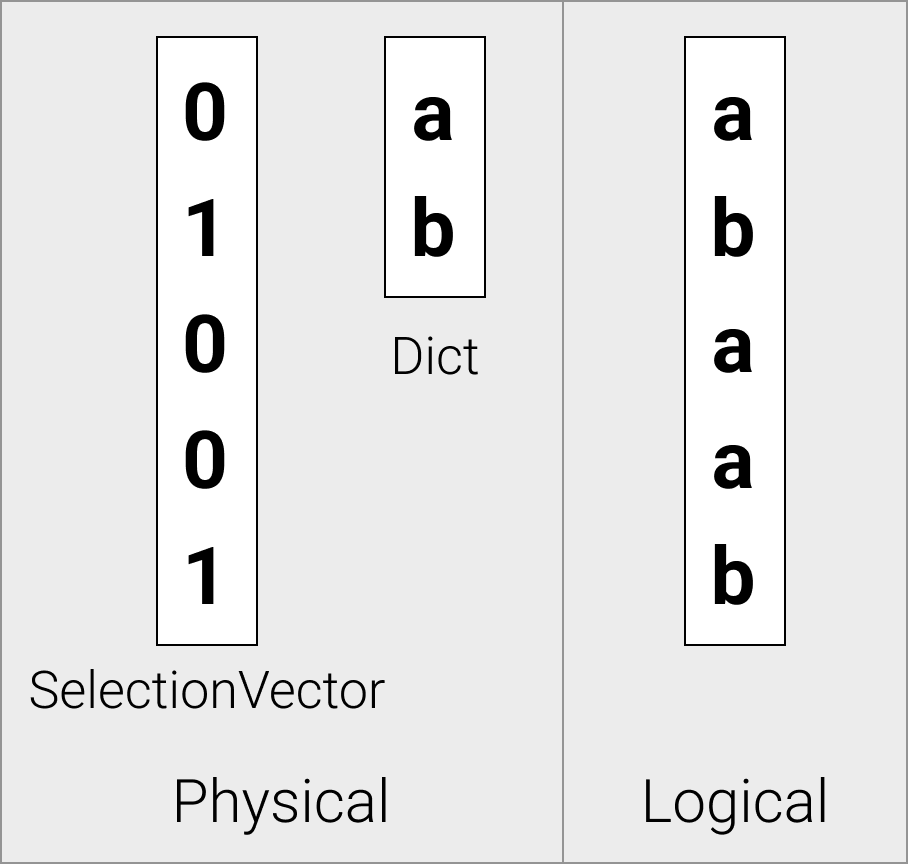
字典向量是在从字典解压缩时由存储发出的
就像常量向量一样,字典向量也是由存储发出的。 在反序列化字典压缩的列段时,我们将其存储在字典向量中,以便在查询执行期间保持数据压缩。
序列向量
序列向量在物理上存储为一个偏移量和一个增量值。
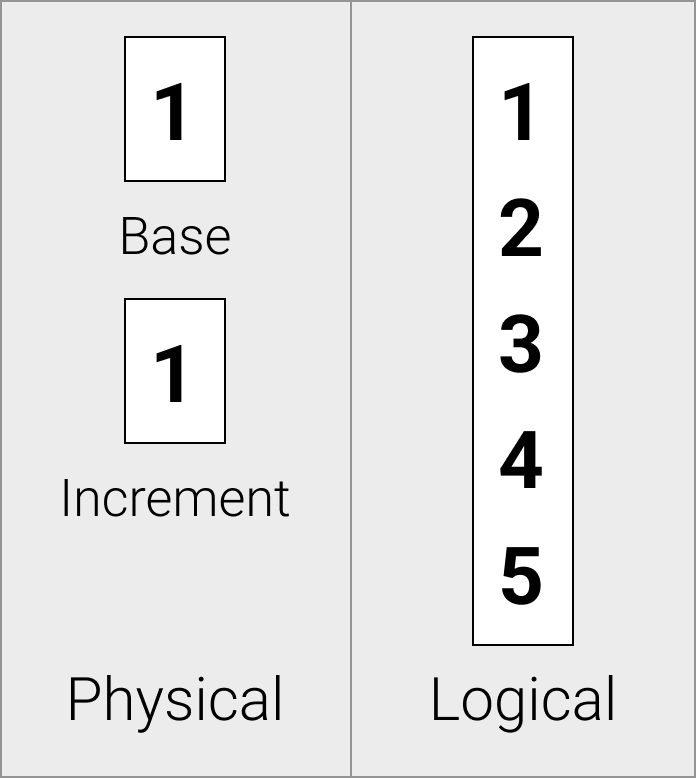
序列向量对于高效存储增量序列非常有用。它们通常用于行标识符。
统一向量格式
不同向量格式的这些属性非常适合优化目的,例如,您可以想象一个场景,其中函数的所有参数都是常量,我们可以只计算一次结果并发出一个常量向量。 但是,由于可能性的组合爆炸,为每个函数的每种向量类型组合编写专门的代码是不可行的。
与其这样做,每当你想通用地使用一个向量而不考虑类型时,可以使用UnifiedVectorFormat。 这种格式本质上充当了向量内容的通用视图。每种类型的向量都可以转换为这种格式。
复杂类型
字符串向量
为了高效地存储字符串,我们使用了我们的string_t类。
struct string_t {
union {
struct {
uint32_t length;
char prefix[4];
char *ptr;
} pointer;
struct {
uint32_t length;
char inlined[12];
} inlined;
} value;
};
短字符串(<= 12 bytes)被内联到结构中,而较大的字符串则存储在辅助字符串缓冲区中,并使用指针指向数据。长度在整个函数中使用,以避免调用strlen并不断检查空指针。前缀用于比较作为早期退出(当前缀不匹配时,我们知道字符串不相等,不需要追踪任何指针)。
列表向量
列表向量存储为一系列列表条目以及一个子向量。子向量包含列表中存在的值,而列表条目则指定每个单独列表的构建方式。
struct list_entry_t {
idx_t offset;
idx_t length;
};
偏移量指的是子向量中的起始行,长度用于跟踪该行的列表大小。
列表向量可以递归存储。对于嵌套的列表向量,列表向量的子元素又是一个列表向量。
例如,考虑这个类型为 BIGINT[][] 的 Vector 的模拟表示:
{
"type": "list",
"data": "list_entry_t",
"child": {
"type": "list",
"data": "list_entry_t",
"child": {
"type": "bigint",
"data": "int64_t"
}
}
}
结构向量
结构向量存储一系列子向量。子向量的数量和类型由结构的模式定义。
映射向量
内部映射向量存储为 LIST[STRUCT(key KEY_TYPE, value VALUE_TYPE)]。
联合向量
在内部,UNION 使用与 STRUCT 相同的结构。
第一个“子”始终由 UNION 的标签向量占用,该向量为每一行记录该行适用的 UNION 类型。