生成RAG的合成数据集
RAG设置的合成数据
不幸的是,在机器学习工程师的生活中,常常缺乏标记数据或数据量非常少。通常,意识到这一点后,项目会开始一个漫长的数据收集和标记过程。只有在几个月后,才能开始开发解决方案。
然而,随着LLM的出现,一些产品的范式发生了变化:现在可以依靠LLM的泛化能力,几乎立即测试一个想法或开发一个AI驱动的功能。如果结果(几乎)如预期那样有效,那么传统的开发过程就可以开始了。

图片来源:The Rise of the AI Engineer, by S. Wang (在新标签页中打开)
新兴方法之一是检索增强生成(RAG)(在新标签页中打开)。它用于知识密集型任务,在这些任务中,你不能仅仅依赖模型的知识。RAG将信息检索组件与文本生成模型结合起来。要了解更多关于这种方法的信息,请参阅指南中的相关部分(在新标签页中打开)。
RAG的关键组件是一个检索模型,它识别相关文档并将其传递给LLM进行进一步处理。检索模型的性能越好,产品或功能的结果就越好。理想情况下,检索模型开箱即用效果良好。然而,其性能在不同语言或特定领域中往往会下降。
想象一下:你需要创建一个基于捷克法律和法律实践的聊天机器人(当然是用捷克语)。或者设计一个为印度市场量身定制的税务助手(OpenAI在GPT-4演示中展示的用例)。你可能会发现,检索模型经常错过最相关的文档,整体表现也不尽如人意,从而限制了系统的质量。
但有一个解决方案。一个新兴趋势涉及使用现有的LLMs来合成数据,用于训练新一代的LLMs/检索器/其他模型。这个过程可以看作是通过基于提示的查询生成将LLMs蒸馏为标准大小的编码器。虽然蒸馏过程计算密集,但它大大降低了推理成本,并可能极大地提高性能,特别是在低资源语言或专业领域。
在本指南中,我们将依赖最新的文本生成模型,如ChatGPT和GPT-4,这些模型可以根据指令生成大量的合成内容。Dai et al. (2022) (在新标签页中打开)提出了一种方法,仅需8个手动标记的示例和大量未标记的数据(如检索文档,例如所有解析的法律),就可以实现接近最先进的性能。这项研究证实,合成生成的数据有助于训练特定任务的检索器,特别是在由于数据稀缺而难以进行监督领域微调的任务中。
特定领域数据集生成
要利用LLM,需要提供一个简短的描述并手动标记一些示例。需要注意的是,不同的检索任务具有不同的搜索意图,这意味着“相关性”的定义也不同。换句话说,对于相同的(查询,文档)对,它们的相关性可能完全基于搜索意图而不同。例如,一个论点检索任务可能寻求支持论点,而其他任务则需要反论点(如ArguAna数据集(在新标签页中打开)中所示)。
考虑下面的例子。虽然为了更容易理解而用英文编写,但请记住,数据可以是任何语言,因为ChatGPT/GPT-4能够高效处理即使是资源较少的语言。
提示:
Task: Identify a counter-argument for the given argument.
Argument #1: {insert passage X1 here}
A concise counter-argument query related to the argument #1: {insert manually prepared query Y1 here}
Argument #2: {insert passage X2 here}
A concise counter-argument query related to the argument #2: {insert manually prepared query Y2 here}
<- paste your examples here ->
Argument N: Even if a fine is made proportional to income, you will not get the equality of impact you desire. This is because the impact is not proportional simply to income, but must take into account a number of other factors. For example, someone supporting a family will face a greater impact than someone who is not, because they have a smaller disposable income. Further, a fine based on income ignores overall wealth (i.e. how much money someone actually has: someone might have a lot of assets but not have a high income). The proposition does not cater for these inequalities, which may well have a much greater skewing effect, and therefore the argument is being applied inconsistently.
A concise counter-argument query related to the argument #N:输出:
punishment house would make fines relative income一般来说,这样的提示可以表示为:
, where and are task-specific document, query descriptions respectively, is a task-specific prompt/instruction for ChatGPT/GPT-4, and is a new document, for which LLM will generate a query.
从这个提示中,只有最后一个文档 和生成的查询将用于本地模型的进一步训练。当目标检索语料库 可用时,可以应用这种方法,但新任务的带注释的查询-文档对数量有限。
整个管道的概述:
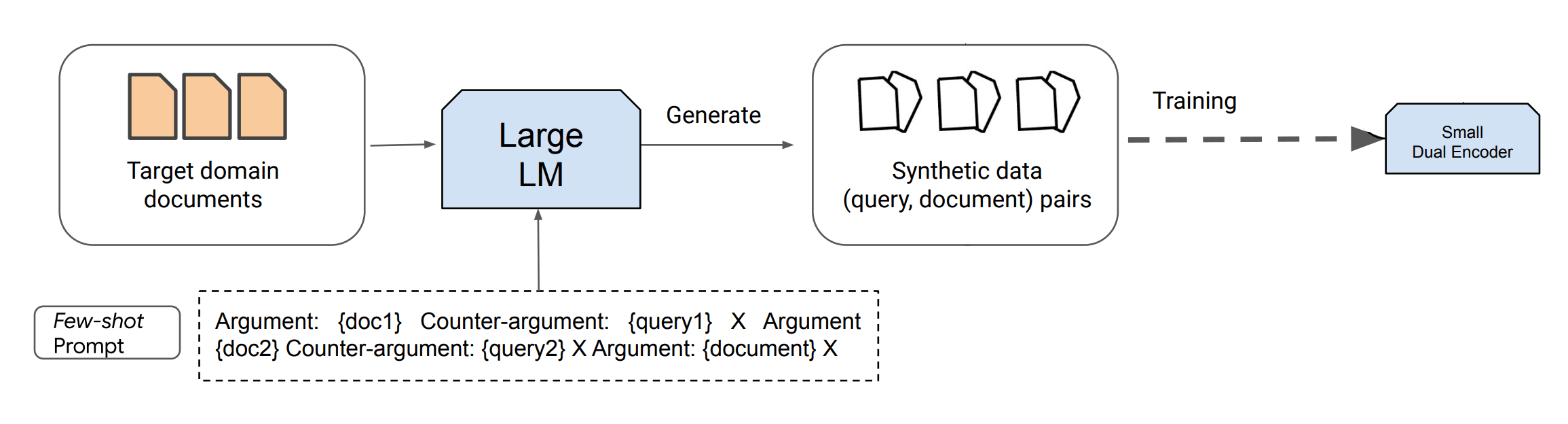
图片来源:Dai et al. (2022) (在新标签页中打开)
负责任地处理示例的手动注释至关重要。最好准备更多(例如20个),并随机选择其中的2-8个用于提示。这增加了生成数据的多样性,而不会在注释上花费大量时间。然而,这些示例应具有代表性,格式正确,甚至详细说明目标查询长度或其语气等细节。示例和指令越精确,合成数据对训练Retriever的效果就越好。低质量的少样本示例可能会对训练模型的最终质量产生负面影响。
在大多数情况下,使用像ChatGPT这样更经济的模型就足够了,因为它在处理非常规领域和非英语语言时表现良好。假设一个包含指令和4-5个示例的提示通常占用700个令牌(假设由于检索器的限制,每段不超过128个令牌),生成部分占用25个令牌。因此,为本地模型微调生成一个包含50,000个文档的合成数据集的成本为:50,000 * (700 * 0.001 * $0.0015 + 25 * 0.001 * $0.002) = 55,其中$0.0015和$0.002是GPT-3.5 Turbo API中每1,000个令牌的成本。甚至可以为同一文档生成2-4个查询示例。然而,通常进一步的训练是值得的,特别是如果你使用的检索器不是用于一般领域(如英语新闻检索),而是用于特定领域(如前面提到的捷克法律)。
50,000这个数字并非随意选取。在Dai等人(2022年)(在新标签页中打开)的研究中,指出这大约是一个模型需要的手动标注数据量,以达到与合成数据训练的模型相当的质量。想象一下,在产品发布前至少需要收集10,000个示例!这将花费不少于一个月的时间,而且劳动力成本肯定会超过一千美元,远高于生成合成数据和训练本地检索模型的成本。现在,通过今天学到的技术,你可以在短短几天内实现两位数的指标增长!
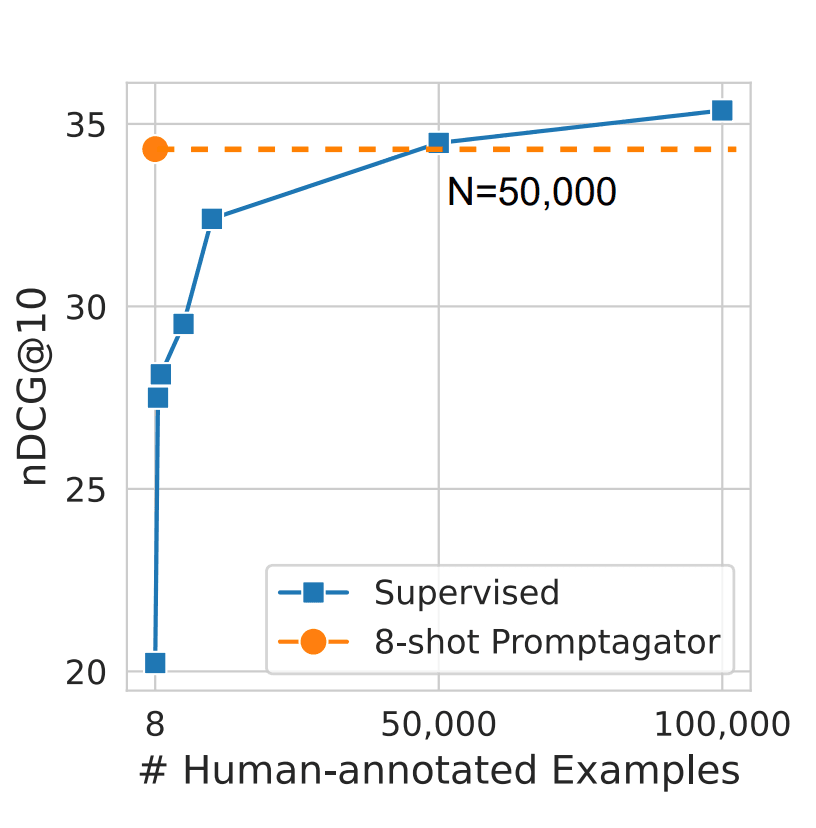
图片来源: Dai et al. (2022) (在新标签页中打开)
以下是来自同一篇论文的提示模板,适用于BeIR基准测试中的一些数据集。
