开始使用Gemini
在本指南中,我们提供了Gemini模型的概述以及如何有效地提示和使用它们。该指南还包括与Gemini模型相关的能力、技巧、应用、限制、论文和其他阅读材料。
双子座简介
Gemini 是 Google Deepmind 最新且功能最强大的 AI 模型。它从一开始就具备多模态能力,并能在文本、图像、视频、音频和代码之间展示出令人印象深刻的跨模态推理能力。
Gemini 有三种尺寸:
- Ultra - 该系列模型中最强大的,适用于高度复杂的任务
- Pro - 被认为是适用于广泛任务的最佳扩展模型
- Nano - 一种高效的模型,适用于设备上内存受限的任务和用例;包括1.8B(Nano-1)和3.25B(Nano-2)参数的模型,这些模型是从大型Gemini模型中蒸馏出来的,并量化为4位。
根据随附的技术报告 (在新标签页中打开),Gemini在32个基准测试中的30个中推进了最先进的技术,涵盖了语言、编码、推理和多模态推理等任务。
这是第一个在MMLU(在新标签页中打开)(一个流行的考试基准)上实现人类专家性能的模型,并在20个多模态基准测试中声称达到了最先进水平。Gemini Ultra在MMLU上达到了90.0%,在MMMU基准测试(在新标签页中打开)上达到了62.4%,该基准测试需要大学水平的学科知识和推理能力。
Gemini模型经过训练,支持32k上下文长度,并基于具有高效注意力机制的Transformer解码器构建(例如,多查询注意力(在新标签页中打开))。它们支持文本输入与音频和视觉输入交错,并可以生成文本和图像输出。
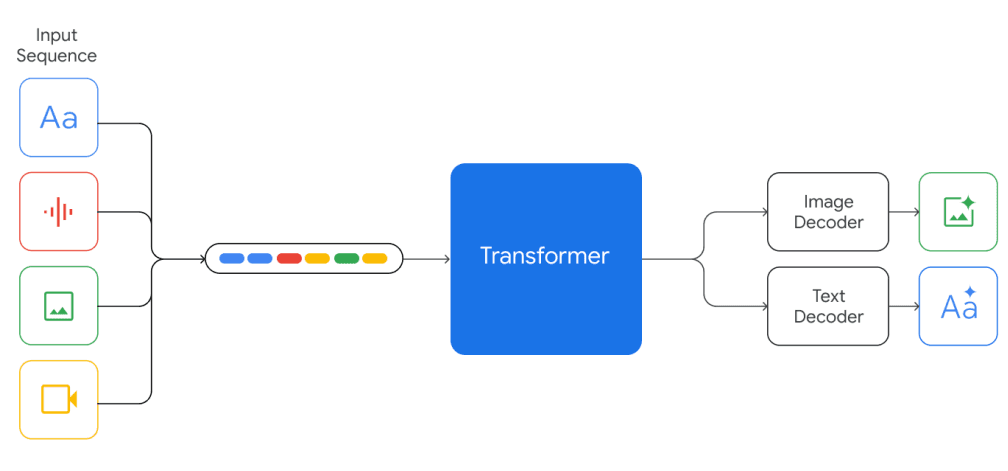
模型在多模态和多语言数据上进行训练,例如网页文档、书籍和代码数据,包括图像、音频和视频数据。模型在所有模态上联合训练,展示了强大的跨模态推理能力,甚至在每个领域都表现出强大的能力。
Gemini 实验结果
Gemini Ultra 在与思维链(CoT)提示(在新标签页中打开)和自一致性(在新标签页中打开)等方法结合时,达到了最高的准确性,这些方法有助于处理模型的不确定性。
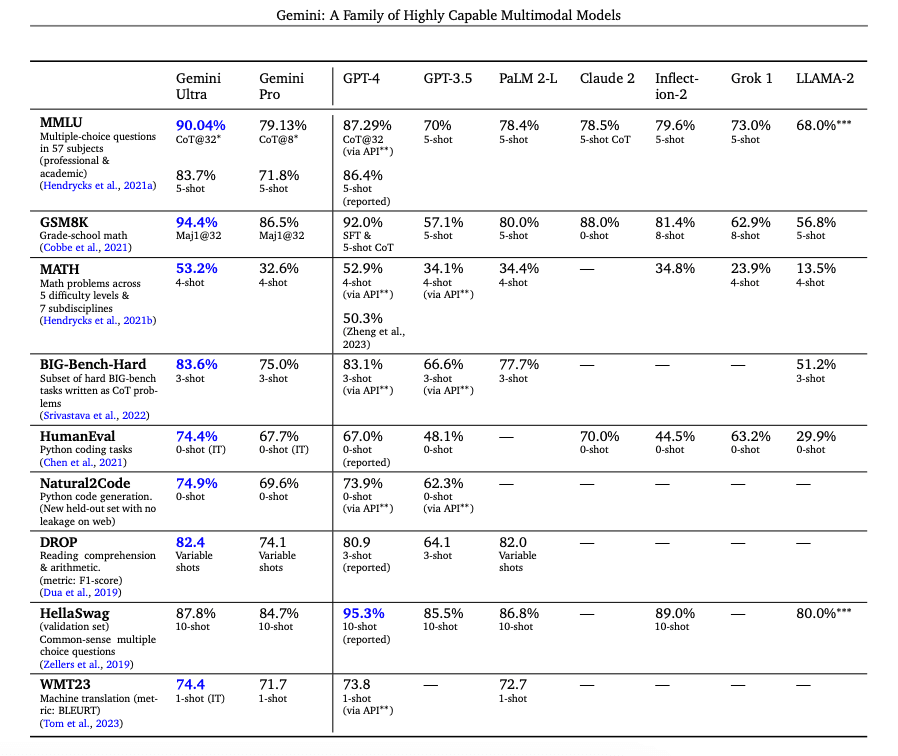
根据技术报告,Gemini Ultra 在 MMLU 上的表现从使用贪婪采样的 84.0% 提高到使用不确定性路由的链式思维方法(涉及 CoT 和多数投票)的 90.0%,使用了 32 个样本,而仅使用 32 个链式思维样本时,其表现略有提升至 85.0%。同样,CoT 和自洽性在 GSM8K 小学数学基准测试中达到了 94.4% 的准确率。此外,Gemini Ultra 正确实现了 74.4% 的 HumanEval (在新标签页中打开) 代码补全问题。下表总结了 Gemini 的结果以及这些模型与其他知名模型的比较。
Gemini Nano 模型在事实性(即与检索相关的任务)、推理、STEM、编码、多模态和多语言任务上也表现出色。
除了标准的多语言能力外,Gemini在多语言数学和摘要基准测试中表现出色,如MGSM (在新标签页中打开)和XLSum (在新标签页中打开)。
Gemini模型在32K的序列长度上进行训练,并且发现在查询上下文长度时,能够以98%的准确率检索到正确的值。这是支持新用例(如文档检索和视频理解)的重要能力。
经过指令调优的Gemini模型在指令遵循、创意写作和安全性等重要能力上始终受到人类评估者的青睐。
Gemini 多模态推理能力
Gemini 是原生多模态训练的,展示了将跨模态能力与语言模型的推理能力相结合的能力。这些能力包括但不限于从表格、图表和图形中提取信息。其他有趣的能力包括从输入中辨别细粒度的细节、跨空间和时间聚合上下文,以及结合不同模态的信息。
Gemini 在图像理解任务中始终优于现有方法,如高级对象识别、细粒度转录、图表理解和多模态推理。一些图像理解和生成能力也可以跨多种全球语言进行转移(例如,使用印地语和罗马尼亚语等语言生成图像描述)。
文本摘要
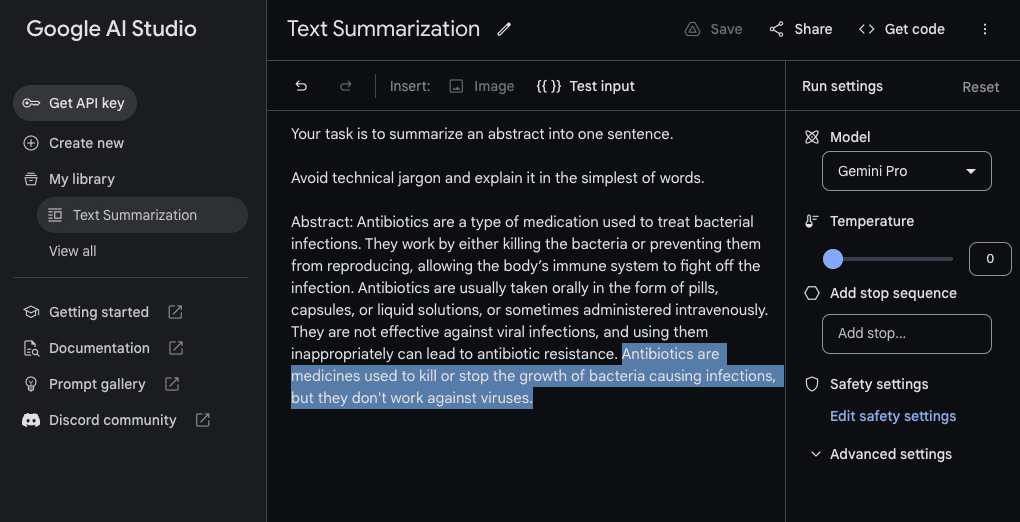
虽然Gemini被训练为一个多模态系统,但它具备许多现代大型语言模型(如GPT-3.5、Claude和Llama)的能力。以下是一个使用Gemini Pro进行简单文本摘要任务的示例。我们在这个示例中使用了Google AI Studio(在新标签页中打开),并将温度值设置为0。
提示:
Your task is to summarize an abstract into one sentence.
Avoid technical jargon and explain it in the simplest of words.
Abstract: Antibiotics are a type of medication used to treat bacterial infections. They work by either killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight off the infection. Antibiotics are usually taken orally in the form of pills, capsules, or liquid solutions, or sometimes administered intravenously. They are not effective against viral infections, and using them inappropriately can lead to antibiotic resistance.Gemini Pro 输出:
Antibiotics are medicines used to kill or stop the growth of bacteria causing infections, but they don't work against viruses.这是任务和模型响应(高亮显示)在Google AI Studio中的截图。
信息提取
这是另一个任务的示例,该任务分析一段文本并提取所需的信息。请记住,这是使用零样本提示,因此结果并不完美,但模型的表现相对较好。
提示:
Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\"model_name\"]. If you don't find model names in the abstract or you are not sure, return [\"NA\"]
Abstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…Gemini Pro 输出:
[\"LLMs\", \"ChatGPT\", \"GPT-4\", \"Chinese LLaMA\", \"Alpaca\"]视觉问答
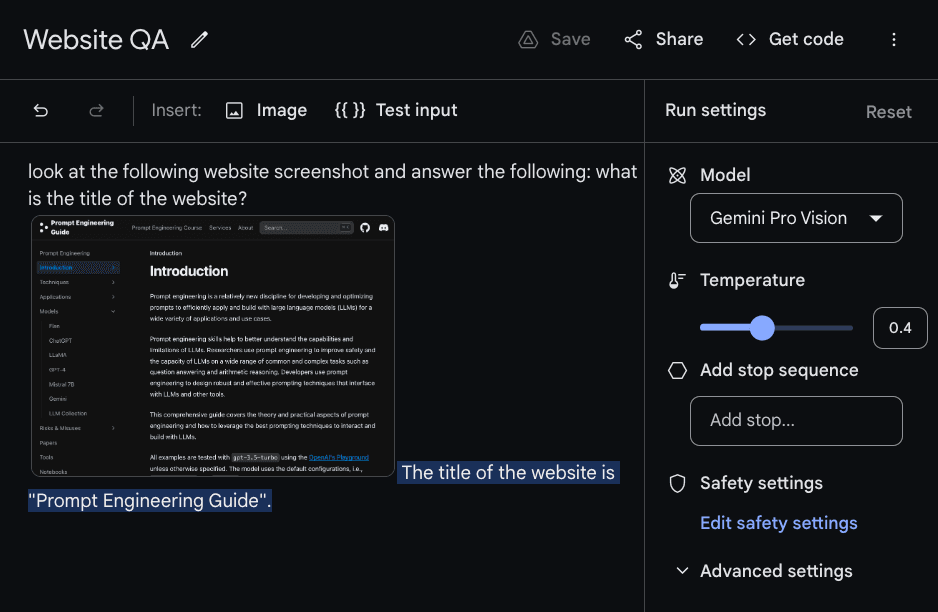
视觉问答涉及向模型提出关于作为输入传递的图像的问题。Gemini模型在理解图表、自然图像、表情包和许多其他类型的图像方面展示了不同的多模态推理能力。在下面的示例中,我们向模型(通过Google AI Studio访问的Gemini Pro Vision)提供了一个文本指令和一个代表本提示工程指南快照的图像。
模型回应“网站的标题是“Prompt Engineering Guide”。”,根据给出的问题,这似乎是正确的答案。
这是另一个不同输入问题的示例。Google AI Studio 允许您通过点击上方的 {{}} 测试输入 选项来测试不同的输入。然后,您可以在下面的表格中添加您正在测试的提示。
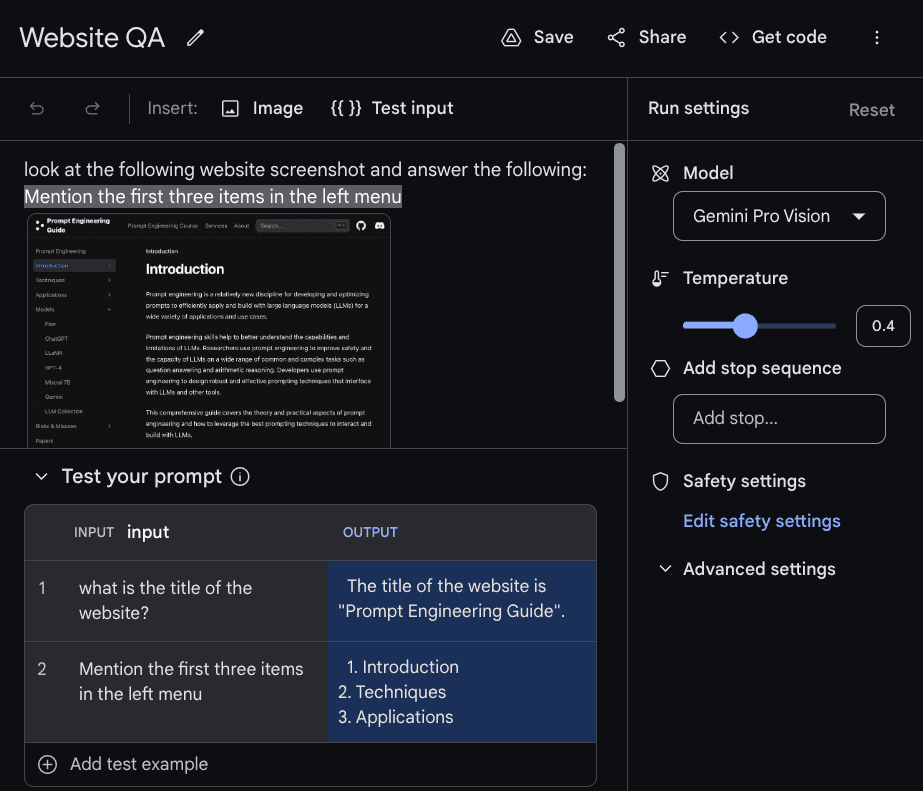
请随意上传您自己的图片并提问进行实验。据报道,Gemini Ultra 在这类任务上表现更好。当模型可用时,我们将进行更多实验。
验证和纠正
Gemini模型展示了令人印象深刻的跨模态推理能力。例如,下图展示了一位老师绘制的物理问题的解决方案(左侧)。然后,Gemini被提示对问题进行推理,并解释学生在解决方案中出错的地方(如果有的话)。模型还被指示解决问题,并在数学部分使用LaTeX。右侧的响应是模型提供的解决方案,详细解释了问题和解决方案。

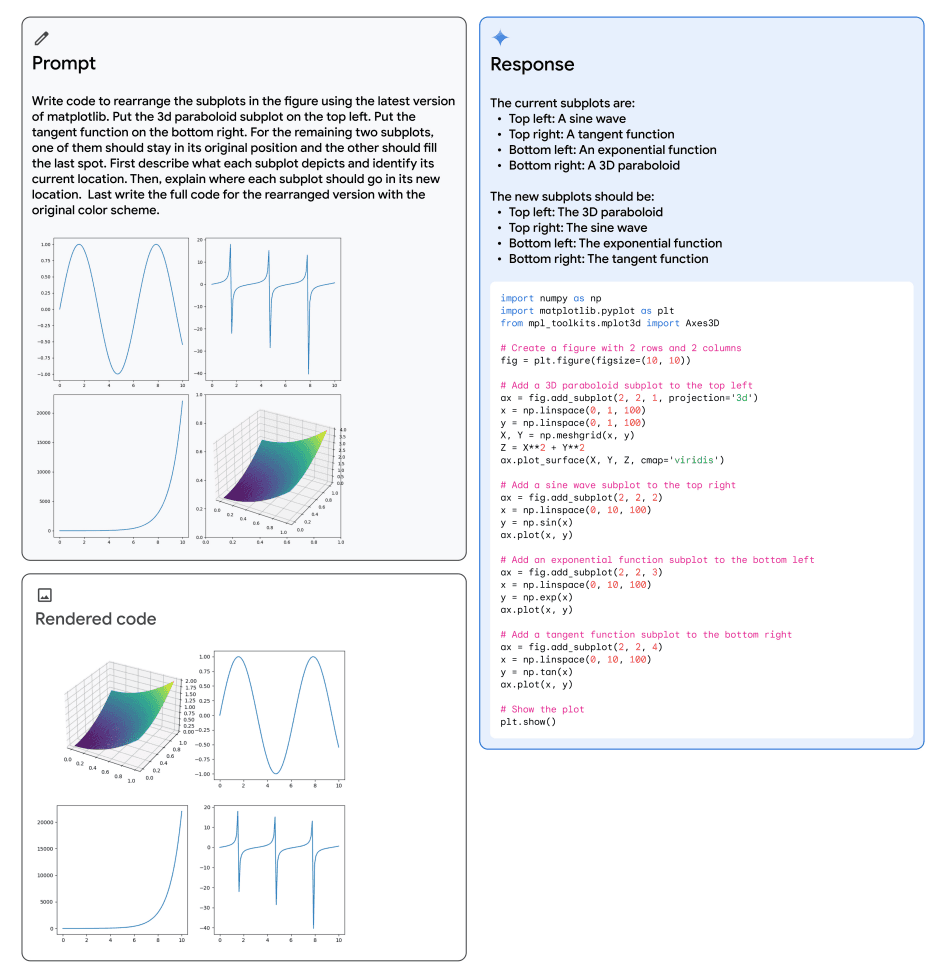
重新排列图形
以下是技术报告中的另一个有趣示例,展示了Gemini的多模态推理能力,用于生成重新排列子图的matplotlib代码。多模态提示显示在左上角,生成的代码在右侧,渲染的代码在左下角。模型利用了几种能力来解决任务,如识别、代码生成、子图位置的抽象推理,以及按照指令将子图重新排列到所需位置。
视频理解
Gemini Ultra 在各种少样本视频字幕任务和零样本视频问答任务中取得了最先进的结果。下面的示例显示,模型接收视频和文本指令作为输入。它能够分析视频并推理情况,以提供适当的答案,或者在这种情况下,提供关于如何改进技术的建议。

图像理解
Gemini Ultra 还可以接受少量提示并生成图像。例如,如下例所示,它可以接受一个图像和文本交错的示例,其中用户提供了两种颜色的信息和图像建议。然后,模型会根据提示中的最终指令,响应它看到的颜色以及一些想法。

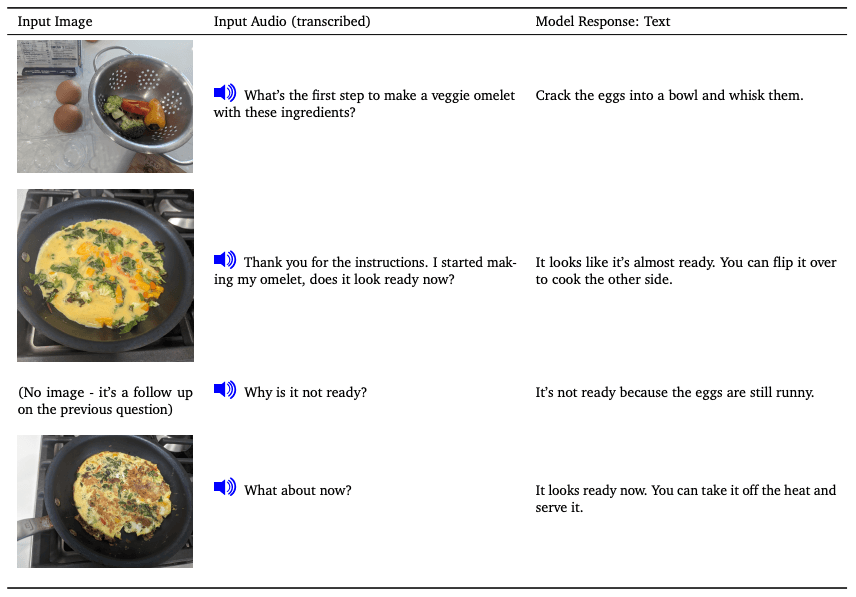
模态组合
Gemini模型还展示了原生处理音频和图像序列的能力。从示例中,你可以观察到模型可以通过一系列音频和图像进行提示。然后,模型能够发送回一个文本响应,该响应考虑了每次交互的上下文。
Gemini 通用编码代理
Gemini 也被用来构建一个名为 AlphaCode 2 (在新标签页中打开) 的通用代理,它将其推理能力与搜索和工具使用相结合,以解决竞争性编程问题。AlphaCode 2 在 Codeforces 竞争性编程平台上的参赛者中排名前 15%。
使用Gemini进行少样本提示
少样本提示是一种提示方法,用于向模型指示您想要的输出类型。这在各种场景中非常有用,例如当您希望输出为特定格式(例如,JSON对象)或风格时。Google AI Studio 也在界面中支持此功能。以下是如何在 Gemini 模型中使用少样本提示的示例。
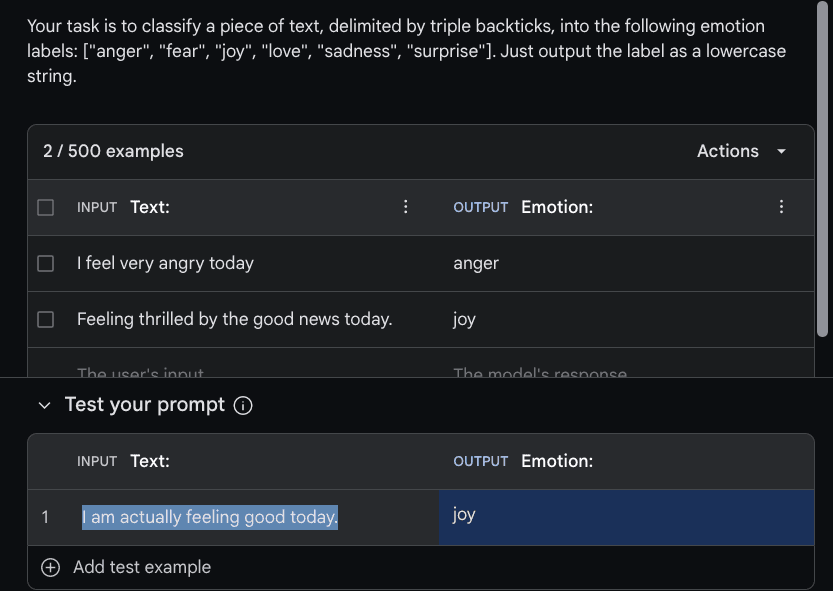
我们有兴趣使用Gemini构建一个简单的情感分类器。第一步是通过点击“创建新”或“+”来创建一个“结构化提示”。少样本提示将结合您的指令(描述任务)和您提供的示例。下图显示了传递给模型的指令(顶部)和示例。您可以设置INPUT文本和OUTPUT文本以具有更具描述性的指示符。下面的示例分别使用“Text:”作为输入和“Emotion:”作为输入和输出指示符。
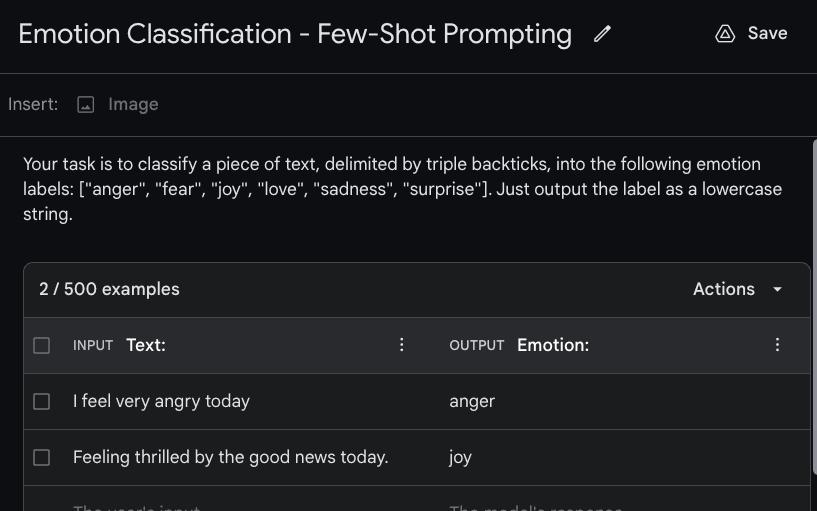
整个组合提示如下:
Your task is to classify a piece of text, delimited by triple backticks, into the following emotion labels: ["anger", "fear", "joy", "love", "sadness", "surprise"]. Just output the label as a lowercase string.
Text: I feel very angry today
Emotion: anger
Text: Feeling thrilled by the good news today.
Emotion: joy
Text: I am actually feeling good today.
Emotion:然后,您可以通过在“测试您的提示”部分下添加输入来测试提示。我们使用“我今天实际上感觉很好。”作为输入示例,点击“运行”后,模型正确输出了“joy”标签。请参见下图中的示例:
库使用
下面是一个简单的示例,展示了如何使用Gemini API提示Gemini Pro模型。您需要安装google-generativeai库并从Google AI Studio获取API密钥。下面的示例是运行与上述部分相同的信息提取任务的代码。
"""
At the command line, only need to run once to install the package via pip:
$ pip install google-generativeai
"""
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# Set up the model
generation_config = {
"temperature": 0,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(model_name="gemini-pro",
generation_config=generation_config,
safety_settings=safety_settings)
prompt_parts = [
"Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\\\"model_name\\\"]. If you don't find model names in the abstract or you are not sure, return [\\\"NA\\\"]\n\nAbstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…",
]
response = model.generate_content(prompt_parts)
print(response.text)输出与之前相同:
[\"LLMs\", \"ChatGPT\", \"GPT-4\", \"Chinese LLaMA\", \"Alpaca\"]参考文献
- 介绍Gemini:我们最大且最强大的人工智能模型 (在新标签页中打开)
- 它是如何制作的:通过多模态提示与Gemini交互 (在新标签页中打开)
- 欢迎来到双子座时代 (在新标签页中打开)
- 提示设计策略 (在新标签页中打开)
- Gemini: 一系列高度能力的多模态模型 - 技术报告 (在新标签页中打开)
- 快速Transformer解码:一个写头就足够了 (在新标签页中打开)
- Google AI Studio 快速入门 (在新标签页中打开)
- 多模态提示 (在新标签页中打开)
- Gemini vs GPT-4V: 通过定性案例对视觉语言模型的初步比较与结合 (在新标签页中打开)
- GPT-4V的挑战者?Gemini在视觉专业领域的早期探索 (在新标签页中打开)