高效的无限上下文变换器
谷歌的一篇新论文 (在新标签页中打开)将压缩记忆集成到了一个普通的点积注意力层中。
目标是使Transformer LLMs能够有效地处理无限长的输入,同时限制内存占用和计算量。
他们提出了一种新的注意力技术,称为Infini-attention,该技术将压缩记忆模块整合到普通的注意力机制中。
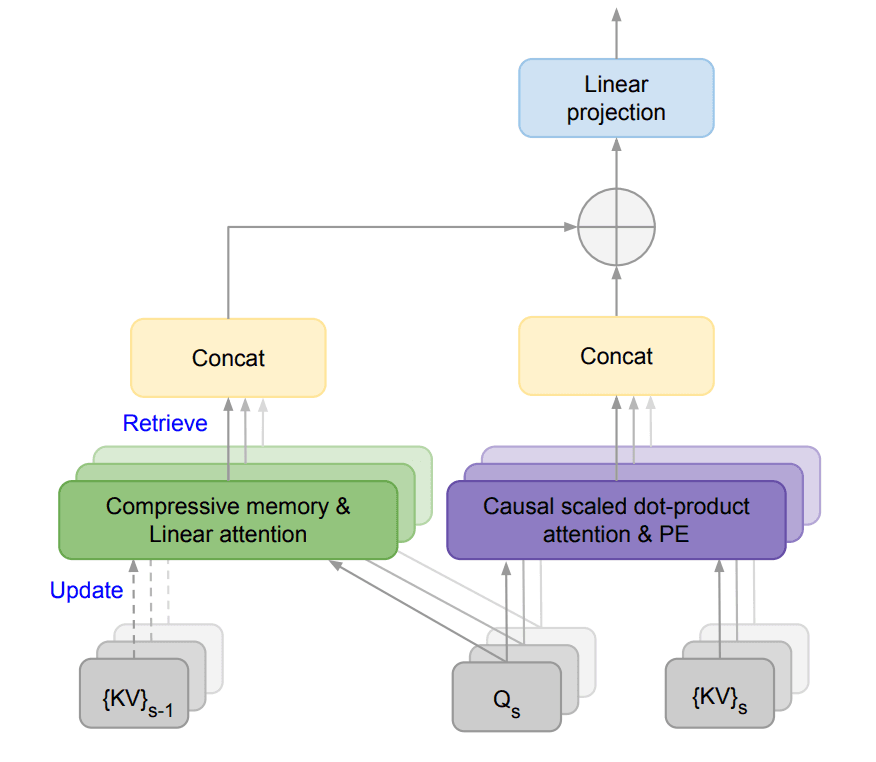
它将掩码局部注意力和长期线性注意力都构建到一个单一的Transformer块中。这使得Infini-Transformer模型能够有效地处理长距离和短距离的上下文依赖关系。
这种方法在长上下文语言建模上优于基线模型,内存压缩比达到114倍!
他们还展示了1B LLM可以自然地扩展到1M的序列长度,并且8B模型在500K长度的书籍摘要任务上取得了新的SoTA结果。
鉴于长上下文LLMs的重要性日益增加,拥有一个有效的记忆系统可能会解锁强大的推理、规划、持续适应能力,以及LLMs中前所未见的能力。