双子座 1.5 专业版
谷歌推出了Gemini 1.5 Pro,这是一个计算高效的多模态专家混合模型。该AI模型专注于诸如回忆和推理长文本内容的能力。Gemini 1.5 Pro能够推理可能包含数百万个标记的长文档,包括数小时的视频和音频。Gemini 1.5 Pro在长文档问答、长视频问答和长上下文自动语音识别方面提升了最先进的性能。Gemini 1.5 Pro在标准基准测试中与Gemini 1.0 Ultra相当或更优,并在至少1000万个标记的情况下实现了接近完美的检索(>99%),与其他长上下文LLM相比,这是一个显著的进步。
作为此次发布的一部分,谷歌还推出了一款新的实验性100万token上下文窗口模型,该模型将在Google AI Studio中提供试用。为了说明这一点,200K是目前任何可用LLM中最大的上下文窗口。通过100万的上下文窗口,Gemini 1.5 Pro旨在解锁各种用例,包括在Google AI Studio中作为提示的大型PDF、代码库甚至长视频的问答。它支持在同一输入序列中混合音频、视觉、文本和代码输入。
架构
Gemini 1.5 Pro 是一个基于稀疏专家混合(MoE)Transformer 的模型,建立在 Gemini 1.0 的多模态能力之上。MoE 的优势在于,模型的总参数可以增长,同时保持激活的参数数量不变。技术报告 (在新标签页中打开) 中没有太多细节,但据报道,Gemini 1.5 Pro 使用的训练计算量显著减少,服务效率更高,并且涉及架构变化,使其能够理解长上下文(最多 1000 万个标记)。该模型在包括不同模态的数据上进行预训练,并使用多模态数据进行指令调优,进一步基于人类偏好数据进行调优。
结果
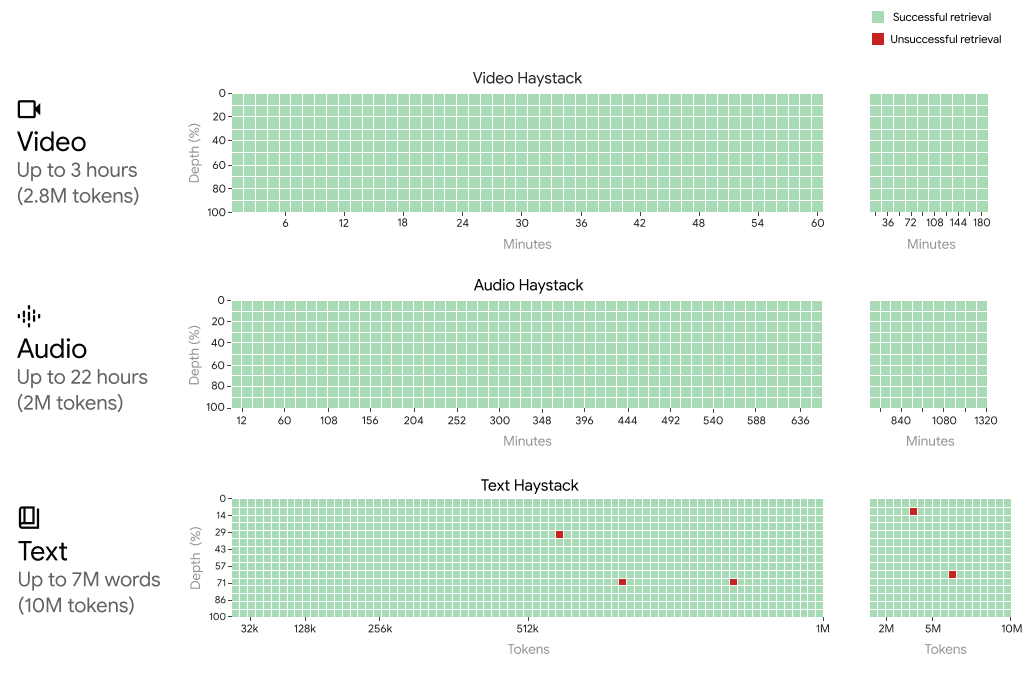
Gemini 1.5 Pro 在所有模态(即文本、视频和音频)中实现了接近完美的“针”召回,最多可达100万个标记。为了更直观地理解Gemini 1.5 Pro的上下文窗口支持,Gemini 1.5 Pro在扩展到以下情况时仍能处理并保持召回性能:
- 约22小时的录音
- 10 x 1440 页的书
- 整个代码库
- 3小时的视频,每秒1帧
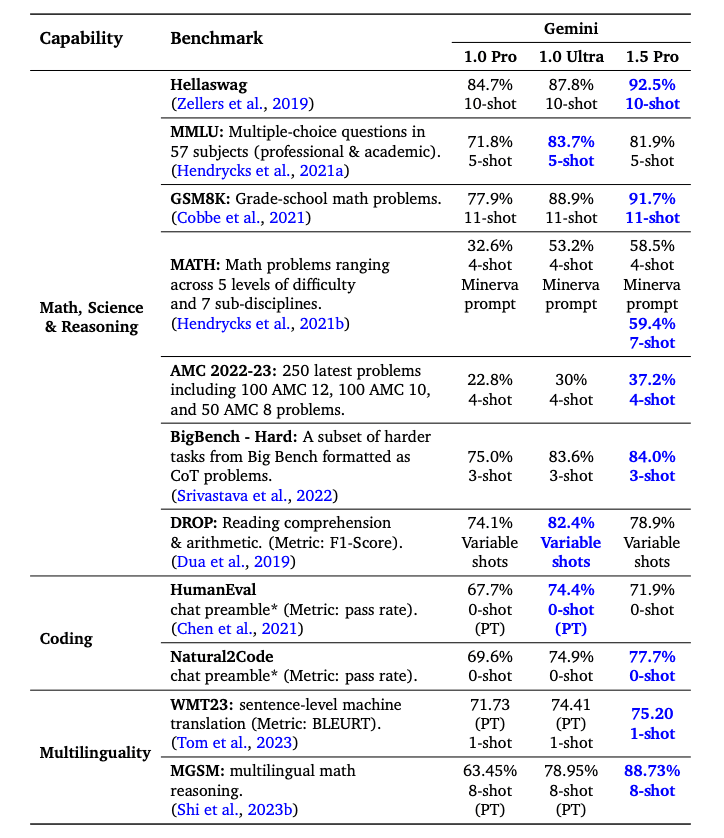
Gemini 1.5 Pro 在大多数基准测试中超越了 Gemini 1.0 Pro,在数学、科学、推理、多语言性、视频理解和代码方面表现出色。以下是一个总结不同 Gemini 模型结果的表格。尽管使用了显著较少的训练计算资源,Gemini 1.5 Pro 在一半的基准测试中也优于 Gemini 1.0 Ultra。
功能
剩余的小节重点介绍了Gemini 1.5 Pro的一系列功能,从分析大量数据到长上下文多模态推理。其中一些功能已在论文、社区以及我们的实验中有所报道。
长文档分析
为了展示Gemini 1.5 Pro处理和分析文档的能力,我们从一个非常基本的问答任务开始。Google AI Studio中的Gemini 1.5 Pro模型支持多达100万个令牌,因此我们能够上传整个PDF文件。下面的示例显示了一个单独的PDF文件已经上传,并附带了一个简单的提示What is the paper about?:
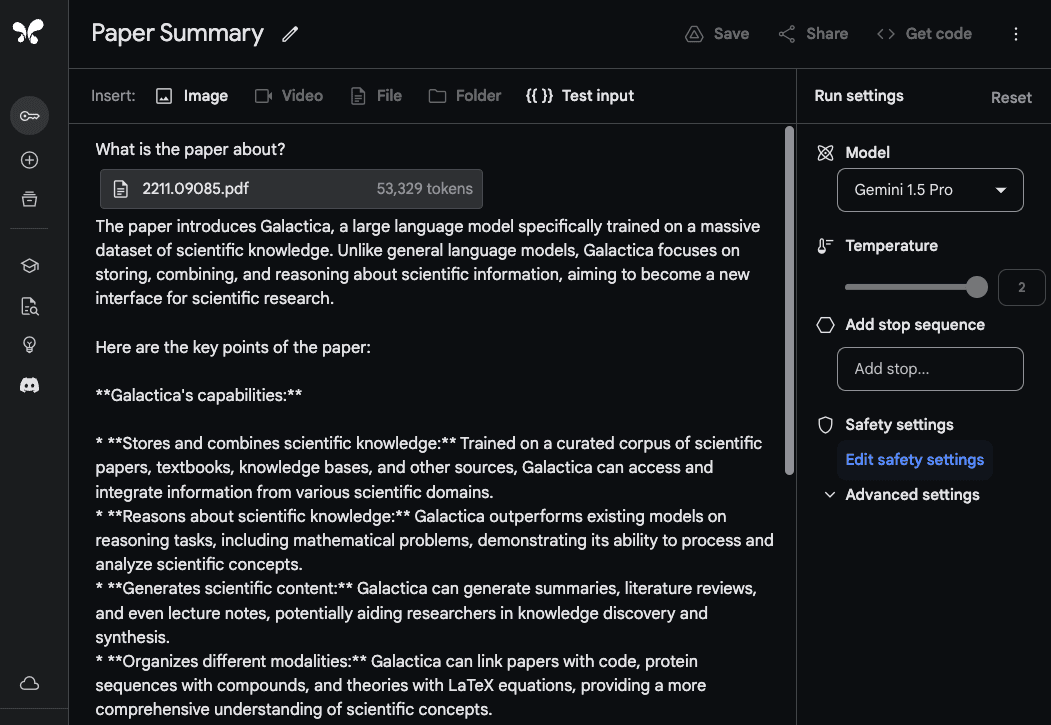
模型的响应准确且简洁,因为它提供了对Galactica论文(在新标签页中打开)的可接受摘要。上面的示例在Google AI Studio中使用了自由形式的提示,但您也可以使用聊天格式与上传的PDF进行交互。如果您有许多问题希望从提供的文档中得到解答,这是一个有用的功能。
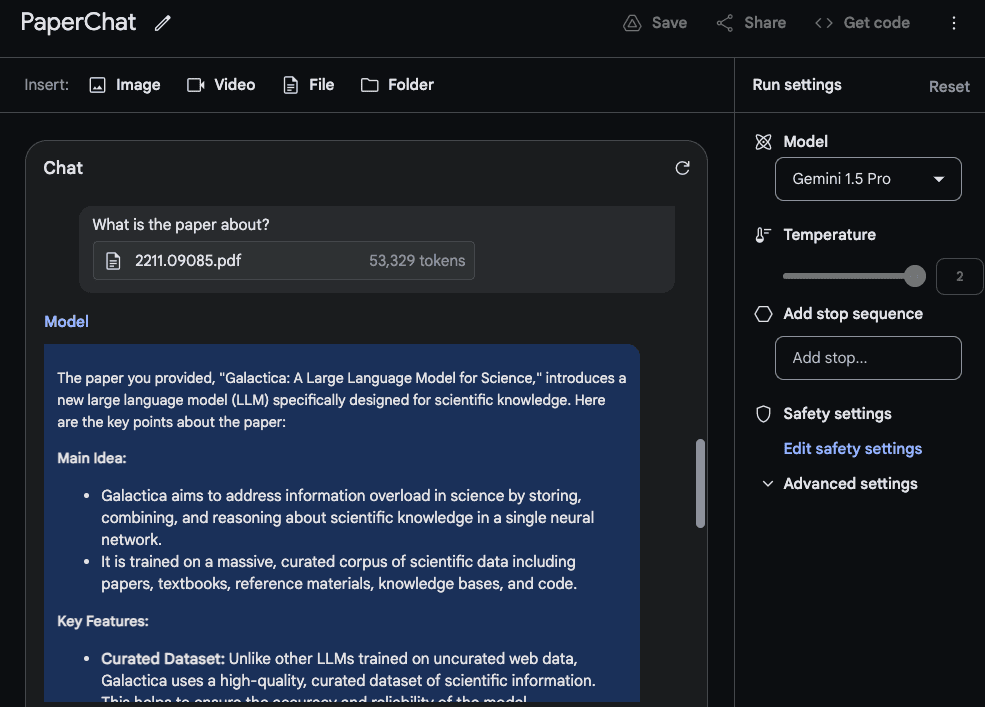
为了利用长上下文窗口,我们现在上传两个PDF文件,并提出一个跨越这两个PDF文件的问题。
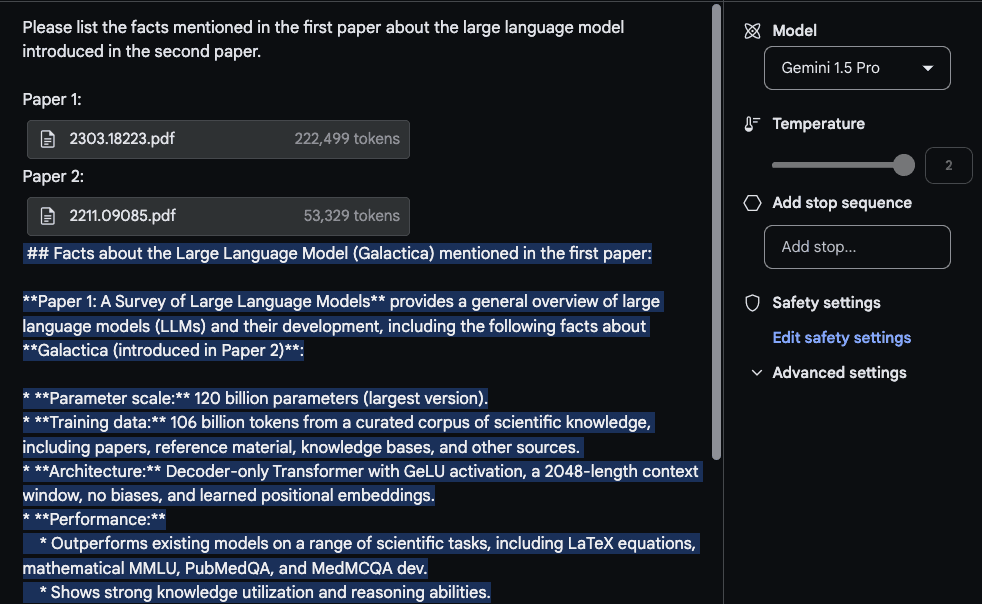
响应是合理的,有趣的部分是从第一篇论文中提取的信息,这是一篇关于LLMs的调查论文(在新标签页中打开),来自一个表格。"架构"信息看起来也是正确的。然而,"性能"部分不属于那里,因为它没有在第一篇论文中找到。对于这个任务,重要的是将提示请列出第一篇论文中提到的关于第二篇论文中介绍的大型语言模型的事实。放在顶部,并用诸如Paper 1和Paper 2的标签标记论文。与此实验相关的另一个后续任务是上传一组论文并编写相关的工作部分,以及如何总结它们的说明。另一个有趣的任务是要求模型将较新的LLM论文纳入调查中。
视频理解
Gemini 1.5 Pro 从一开始就接受了多模态能力的训练,并且它还展示了视频理解能力。我们使用Andrej Karpathy 最近关于 LLMs 的讲座(在新标签页中打开)中的一些提示进行了测试。
在这个简短的演示中,我们创建了一个Chat prompt并上传了包含Karpathy讲座的YouTube视频。第一个问题是What is the lecture about?。这里没有什么太花哨的东西,但响应是可以接受的,因为它准确地总结了讲座内容。
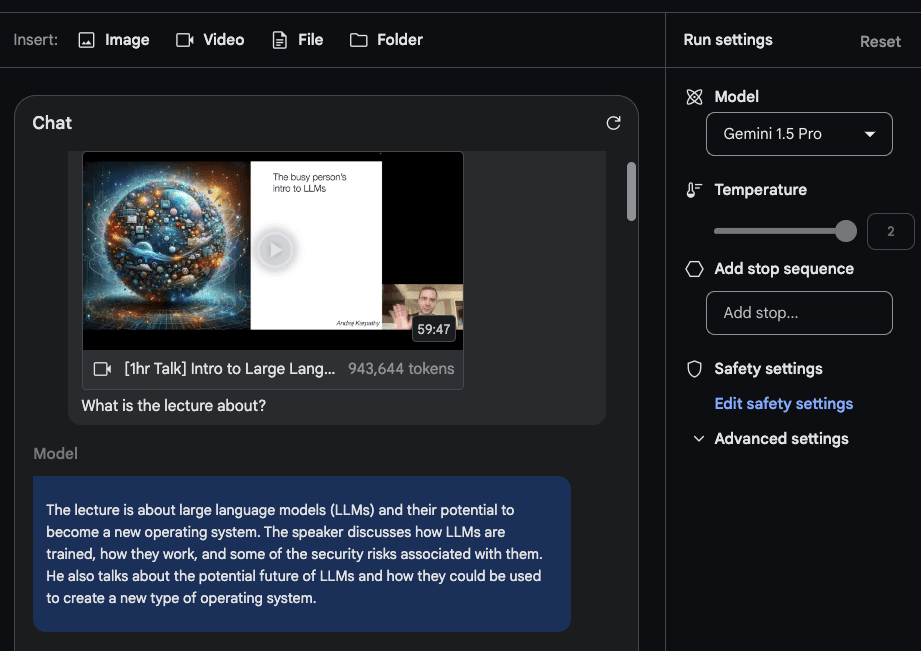
我们提示模型执行的第二个任务是提供讲座的简明大纲(一页长度)。响应如下(为简洁起见进行了编辑):
## Large Language Models: A New Operating System?
Introduction:
- LLMs are trained on massive amounts of text data and can generate human-quality text.
- They are becoming increasingly powerful and are being used for a wide range of tasks, such as writing, translation, and coding.
How LLMs Work:
- LLMs are neural networks that predict the next word in a sequence.
- They learn by iteratively adjusting their parameters to make better predictions.
- While we can measure their performance, we don't fully understand how the billions of parameters collaborate to achieve it.
Training LLMs:
- Requires massive amounts of data and computing power.
- Can be thought of as "compressing the internet" into a single file.
- For example, training LLaMA 2 70B required 6,000 GPUs for 12 days and cost ~$2 million.
LLM Security:
- LLM security is a new and rapidly evolving field.
- Some key security risks include:
- Jailbreaking: bypassing safety mechanisms to generate harmful content.
- Prompt injection: injecting malicious code into prompts to control the LLM's output.
- Data poisoning / Backdoor attacks: inserting crafted text into the training data to influence the LLM's behavior.
...摘要非常简洁,代表了讲座的良好概述和关键点。我们没有评估整个输出的准确性,但看到模型输出信息性的内容很有趣,比如"训练LLaMA 2 70B需要6,000个GPU运行12天,成本约为200万美元。"
当具体细节很重要时,请记住模型有时可能会因为各种原因“产生幻觉”或检索到错误的信息。例如,当我们提示模型What are the FLOPs reported for Llama 2 in the lecture?时,它回答The lecture reports that training Llama 2 70B required approximately 1 trillion FLOPs.,这是不准确的。正确的回答应该是~1e24 FLOPs。技术报告中包含了许多实例,这些实例展示了当被问及视频的具体问题时,这些长上下文模型会失败的情况。
下一个任务涉及从视频中提取表格信息。示例展示了提示和响应。我们可以观察到模型生成了一个表格,其中一些细节是正确的,但也有一些是错误的。例如,表格列是正确的,但其中一个行标签是错误的(即Concept Resolution应该是Coref Resolution)。我们用其他表格和其他不同元素(如文本框)测试了一些这些提取任务,并注意到了类似的不一致性。
技术报告中记录的一个有趣例子是模型能够根据特定场景或时间戳从视频中检索详细信息。在第一个例子中,我们提示模型回答特定部分开始的位置。
提示:
At what timestamp does the LLM OS section start?输出:
The LLM OS section starts at 42:17.响应是正确的。
在下一个例子中,我们要求模型解释幻灯片中的图表。
提示:
Can you explain the chart (on the right-hand side) on the self-improvement slide?输出:
The chart shows the performance of AlphaGo Zero over time, as measured by its Elo rating. The Elo rating is a measure of a player's skill in a game, with higher ratings indicating stronger players. The chart shows that AlphaGo Zero's performance improved rapidly over the course of 40 days, eventually surpassing the performance of all other versions of AlphaGo, including the version that defeated the world champion Go player Lee Sedol. This improvement was achieved entirely through self-play, with no human intervention or historical data.模型似乎很好地利用了提供的信息来解释图表中的结果。以下是相应幻灯片的快照:
代码推理
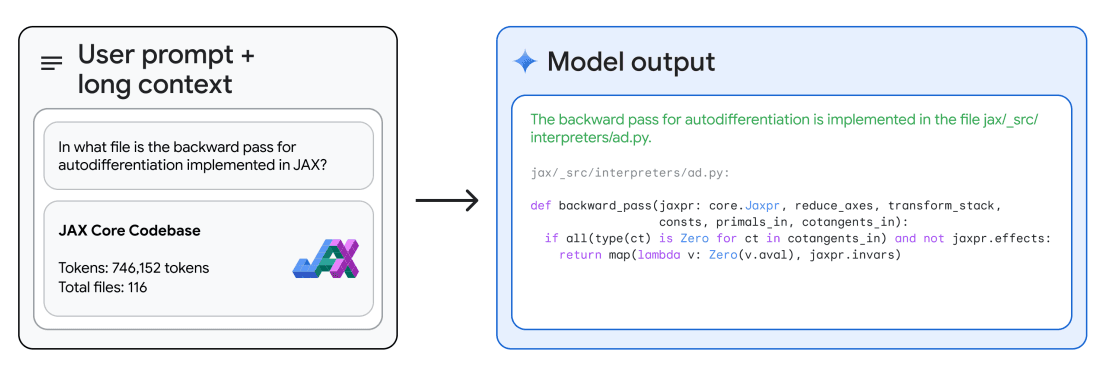
凭借其长上下文推理能力,Gemini 1.5 Pro 能够回答关于代码库的问题。使用 Google AI Studio,Gemini 1.5 Pro 允许最多 100 万个令牌,因此我们可以上传整个代码库,并提出不同的问题或与代码相关的任务。技术报告提供了一个示例,其中模型在上下文中给出了整个 JAX 代码库(约 746K 令牌),并要求识别核心自动微分方法的位置。
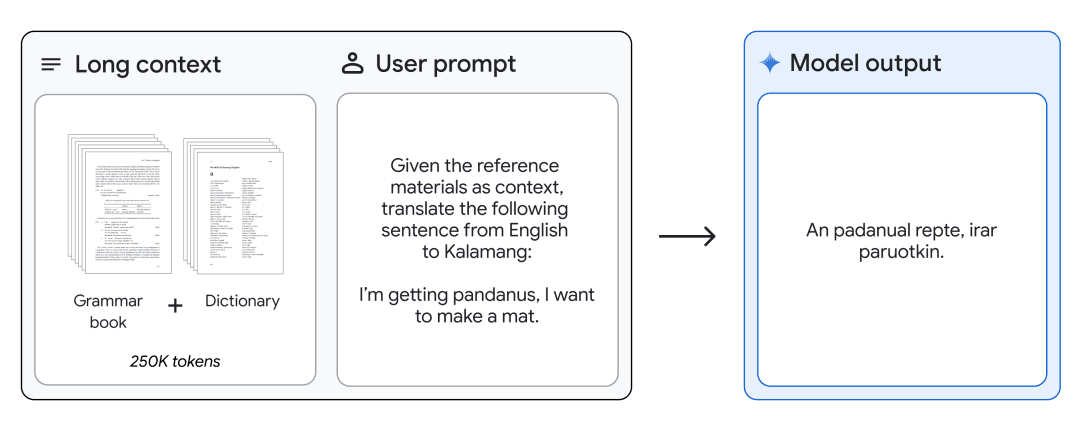
英语到Kalamang翻译
Gemini 1.5 Pro 可以提供一本语法手册(500页的语言学文档、一本词典和约400个平行句子)用于Kalamang语,这是一种全球不到200人使用的语言,并且能够以从相同内容学习的人的水平将英语翻译成Kalamang语。这展示了Gemini 1.5 Pro通过长上下文启用的上下文学习能力。
图表来源:Gemini 1.5: 解锁跨数百万上下文标记的多模态理解 (在新标签页中打开)