RAG模型的忠实度如何?
这篇由Wu等人(2024)(在新标签页中打开)撰写的新论文旨在量化RAG与LLMs内部先验之间的拉锯战。
它专注于GPT-4和其他大型语言模型在问答分析中的应用。
研究发现,提供正确的检索信息可以修复大部分模型错误(准确率为94%)。
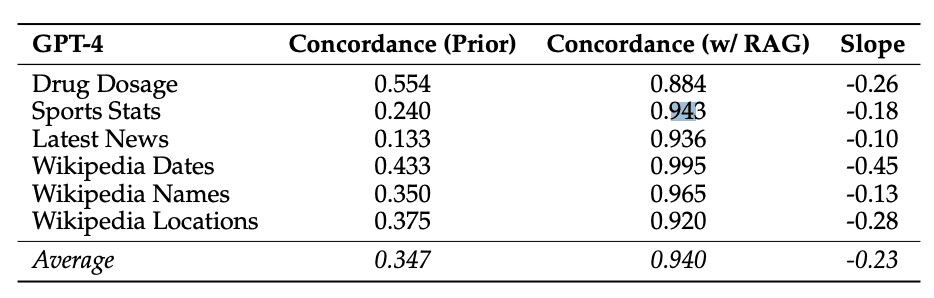 来源: Wu et al. (2024) (在新标签页中打开)
来源: Wu et al. (2024) (在新标签页中打开)
当文档包含更多错误值且LLM的内部先验较弱时,LLM更有可能背诵错误信息。然而,当LLM的先验较强时,它们被发现更具抵抗力。
该论文还报告称,“修改后的信息与模型的先验偏差越大,模型越不可能偏好它。”
许多开发者和公司正在生产环境中使用RAG系统。这项工作强调了在使用LLMs时评估风险的重要性,考虑到可能包含支持、矛盾或完全错误信息的不同类型的上下文信息。