LLM 上下文回忆依赖于提示
这篇由Machlab和Battle(2024)(在新标签页中打开)撰写的新论文,通过几个“大海捞针”测试分析了不同LLMs的上下文回忆性能。
这表明各种LLM在不同长度和放置深度下回忆事实的能力不同。研究发现,提示中的微小变化会显著影响模型的回忆性能。
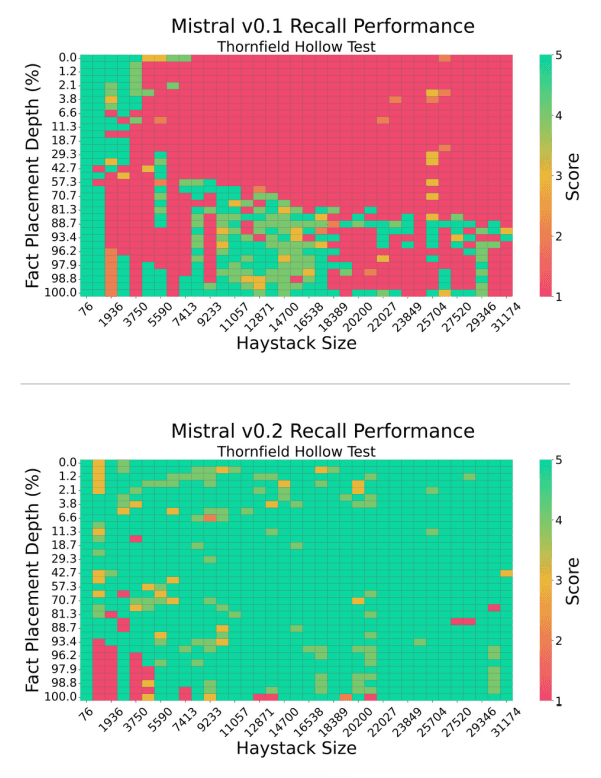 来源: Machlab and Battle (2024) (在新标签页中打开)
来源: Machlab and Battle (2024) (在新标签页中打开)
此外,提示内容与训练数据之间的相互作用可能会降低响应质量。
模型的召回能力可以通过增加规模、增强注意力机制、尝试不同的训练策略以及应用微调来提高。
论文中的重要实用建议:“随着技术的不断发展,持续的评估将进一步指导为个别用例选择LLM,从而在实际应用中最大化其影响力和效率。”
本文的主要收获是精心设计提示的重要性,建立持续评估协议,以及测试不同的模型增强策略以提高召回率和实用性。