Llama 3
Meta 最近 推出了 (在新标签页中打开) 他们新的大型语言模型(LLMs)系列,名为 Llama 3。此次发布包括 8B 和 70B 参数的预训练和指令调优模型。
Llama 3 架构详情
以下是Llama 3提到的技术细节的总结:
- 它使用了一个标准的仅解码器变压器。
- 词汇量为128K个标记。
- 它是在8K标记的序列上进行训练的。
- 它应用了分组查询注意力(GQA)
- 它在超过15T的标记上进行了预训练。
- 它涉及包括SFT、拒绝采样、PPO和DPO组合的训练后过程。
性能
值得注意的是,Llama 3 8B(指令调优)的表现优于Gemma 7B(在新标签页中打开)和Mistral 7B Instruct(在新标签页中打开)。Llama 3 70 在总体上优于Gemini Pro 1.5(在新标签页中打开)和Claude 3 Sonnet(在新标签页中打开),但在与Gemini Pro 1.5相比时,在MATH基准测试中稍显落后。
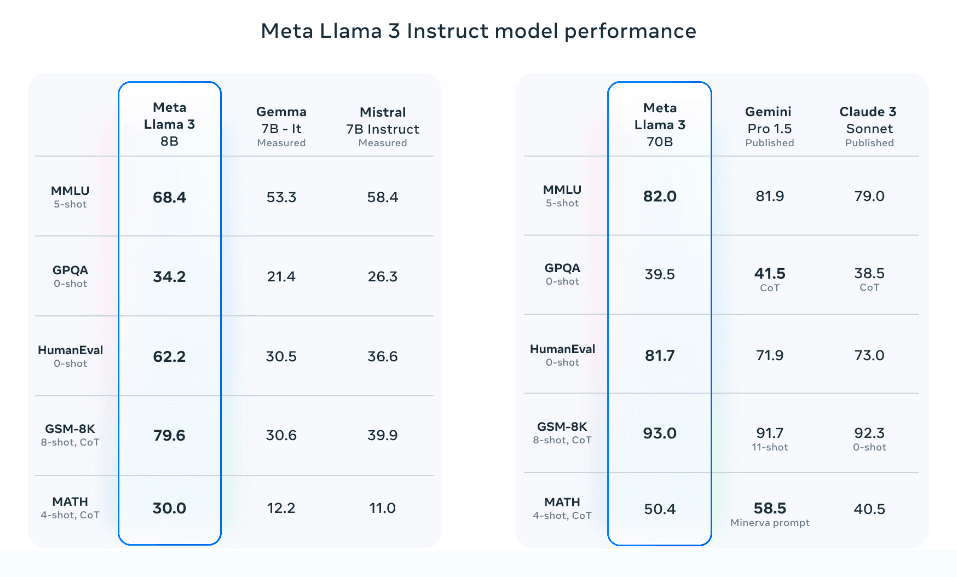 来源:
来源: 预训练模型在多个基准测试中也优于其他模型,如AGIEval(英文)、MMLU和Big-Bench Hard。
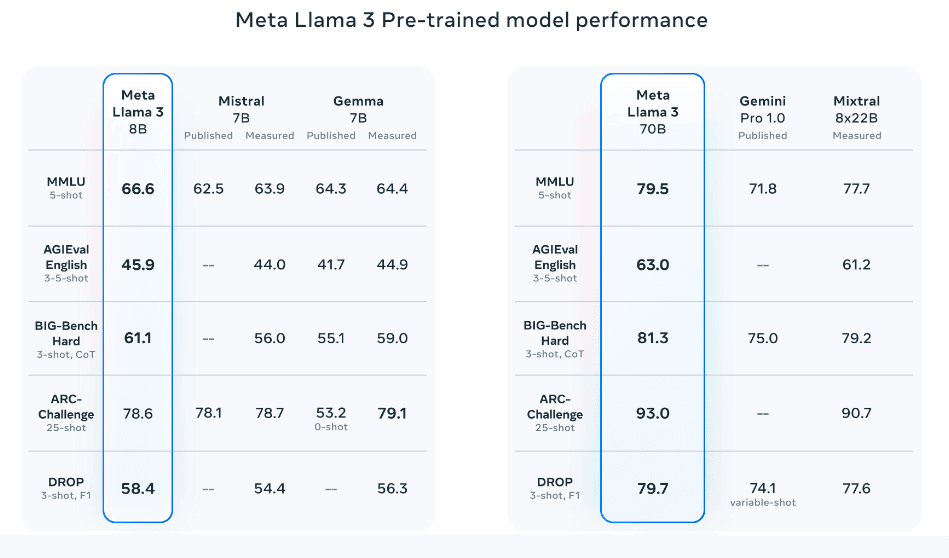 来源:
来源: Llama 3 400B
Meta 还报告称,他们将发布一个 400B 参数的模型,该模型仍在训练中,即将推出!在管道中还有关于多模态支持、多语言能力和更长上下文窗口的努力。截至 2024 年 4 月 15 日,Llama 3 400B 的当前检查点在 MMLU 和 Big-Bench Hard 等常见基准测试中产生以下结果:
 来源:
来源: Llama 3 模型的许可信息可以在模型卡片(在新标签页中打开)上找到。
Llama 3 的扩展评测
以下是Llama 3的详细评测: