OLMo
在本指南中,我们提供了开放语言模式(OLMo)的概述,包括提示和使用示例。该指南还包括与OLMo相关的技巧、应用、限制、论文和其他阅读材料。
OLMo简介
艾伦人工智能研究所发布 (在新标签页中打开)了一个名为OLMo的新开放语言模型和框架。这一努力旨在提供对数据、训练代码、模型、评估代码的完全访问,以共同加速语言模型的研究。
他们的首次发布包括四个7B参数规模的变体和一个1B规模的模型,所有这些模型都至少在2T个标记上进行了训练。这标志着多次发布中的第一次,其中还包括即将推出的65B OLMo模型。
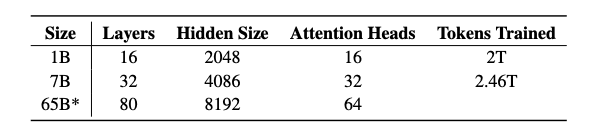
发布内容包括:
- 完整的训练数据,包括生成数据的代码(在新标签页中打开)
- 完整的模型权重,训练代码 (在新标签页中打开),日志,指标和推理代码
- 每个模型有多个检查点
- 评估代码 (在新标签页中打开)
- 微调代码
所有代码、权重和中间检查点均在Apache 2.0许可证(在新标签页中打开)下发布。
OLMo-7B
OLMo-7B 和 OLMo-1B 模型都采用了仅解码器的变压器架构。它遵循了其他模型如 PaLM 和 Llama 的改进:
- 无偏差
- 一个非参数层归一化
- SwiGLU激活函数
- 旋转位置嵌入 (RoPE)
- 词汇量为50,280
Dolma 数据集
此版本还包括发布一个名为Dolma(在新标签页中打开)的预训练数据集——一个多样化的、多来源的语料库,包含来自7个不同数据源的50亿份文档中的3万亿个标记。Dolma的创建涉及语言过滤、质量过滤、内容过滤、去重、多源混合和标记化等步骤。
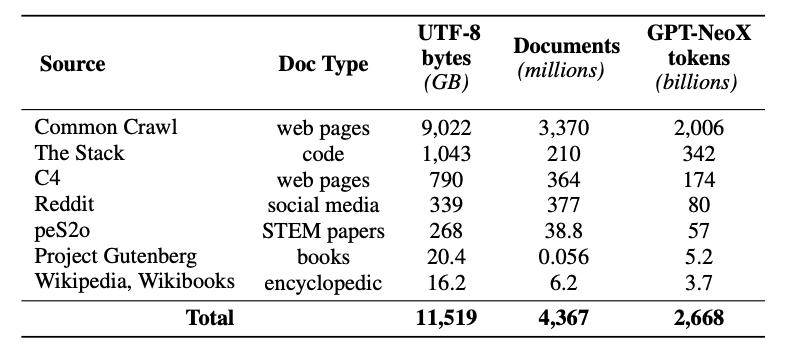
训练数据集包括来自Dolma的2T-token样本。在每个文档的末尾附加一个特殊的EOS标记后,这些标记被连接在一起。训练实例包括连续的2048个标记的组,这些组也被打乱。
更多训练细节和训练模型的硬件规格可以在论文中找到。
结果
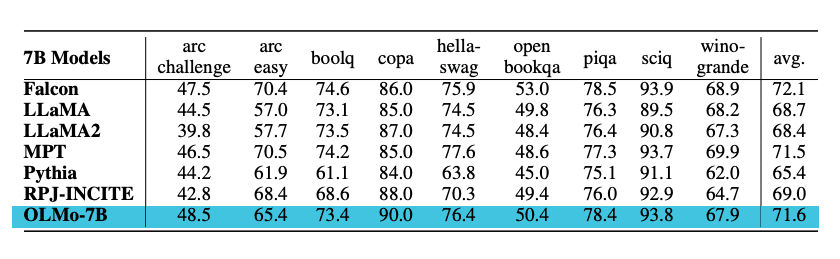
模型在下游任务上使用Catwalk(在新标签页中打开)进行评估。OLMo模型与Falcon和Llama 2等其他几个公开可用的模型进行了比较。具体来说,模型在一组旨在衡量模型常识推理能力的任务上进行了评估。下游评估套件包括piqa和hellaswag等数据集。作者使用排名分类(即,完成情况按可能性排名)进行零样本评估,并报告了准确率。OLMo-7B在2个最终任务上优于所有其他模型,并在8/9个最终任务上保持前三名。请参见下图中的结果摘要。
OLMo提示指南
即将推出...
图表来源:OLMo: Accelerating the Science of Language Models (在新标签页中打开)