反思
Reflexion 是一个通过语言反馈来增强基于语言的代理的框架。根据 Shinn 等人 (2023) (在新标签页中打开) 的说法,“Reflexion 是一种新的‘语言’强化范式,它将策略参数化为代理的记忆编码与选择的 LLM 参数配对。”
在高层次上,Reflexion 将来自环境的反馈(无论是自由形式的语言还是标量)转换为语言反馈,也称为自我反思,这作为上下文提供给下一个情节中的LLM代理。这有助于代理快速有效地从先前的错误中学习,从而在许多高级任务中提高性能。
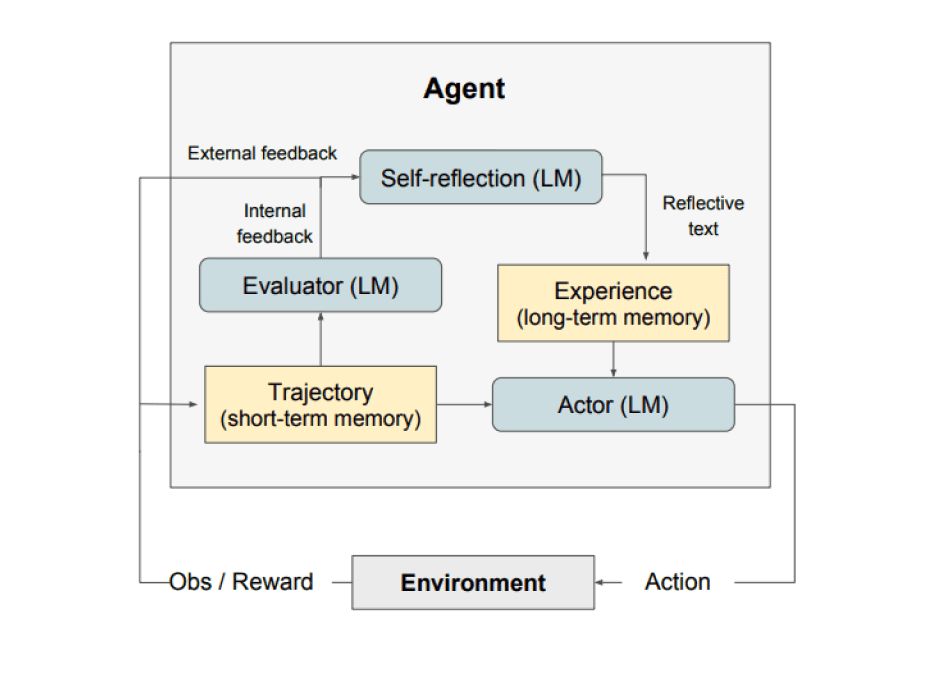
如上图所示,Reflexion 由三个不同的模型组成:
- 一个演员:根据状态观察生成文本和动作。演员在环境中采取行动并接收观察结果,从而产生轨迹。思维链(CoT)(在新标签页中打开)和ReAct(在新标签页中打开)被用作演员模型。还添加了一个记忆组件,为代理提供额外的上下文。
- 评估器:对Actor生成的输出进行评分。具体来说,它接收生成的轨迹(也称为短期记忆)作为输入,并输出奖励分数。根据任务的不同,使用不同的奖励函数(LLMs和基于规则的启发式方法用于决策任务)。
- 自我反思:生成口头强化提示,以帮助演员进行自我改进。这一角色由LLM实现,并为未来的试验提供有价值的反馈。为了生成具体且相关的反馈(这些反馈也会存储在记忆中),自我反思模型利用奖励信号、当前轨迹及其持久记忆。这些经验(存储在长期记忆中)被代理利用,以快速改进决策。
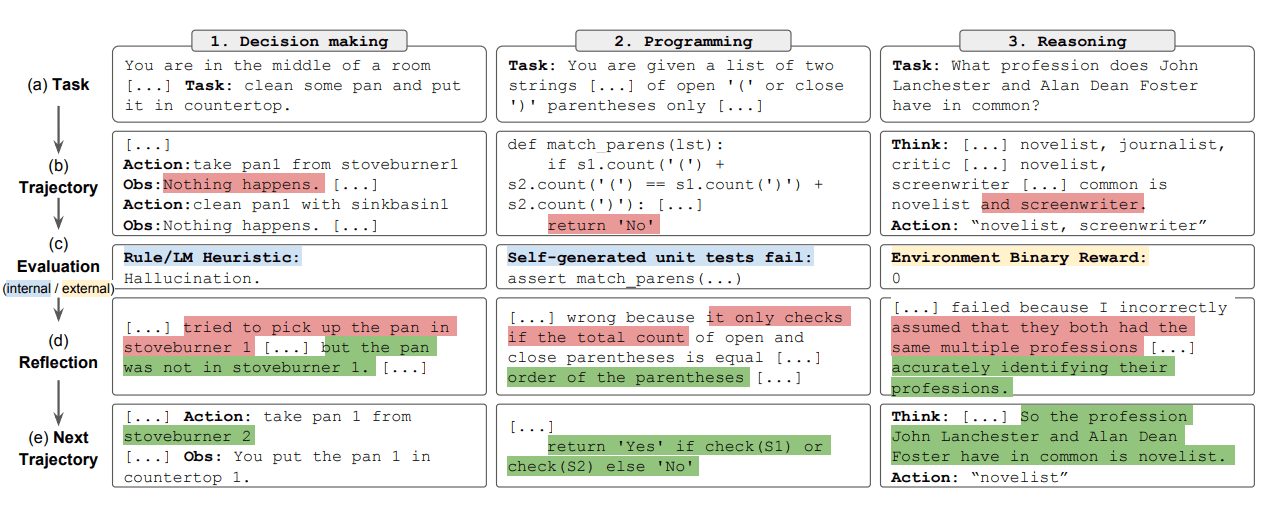
总之,Reflexion过程的关键步骤是 a) 定义任务,b) 生成轨迹,c) 评估,d) 进行反思,以及 e) 生成下一个轨迹。下图展示了Reflexion代理如何学习迭代优化其行为以解决各种任务(如决策、编程和推理)的示例。Reflexion通过引入自我评估、自我反思和记忆组件扩展了ReAct框架。
结果
实验结果表明,Reflexion代理在决策制定AlfWorld任务、HotPotQA中的推理问题以及HumanEval上的Python编程任务中显著提高了性能。
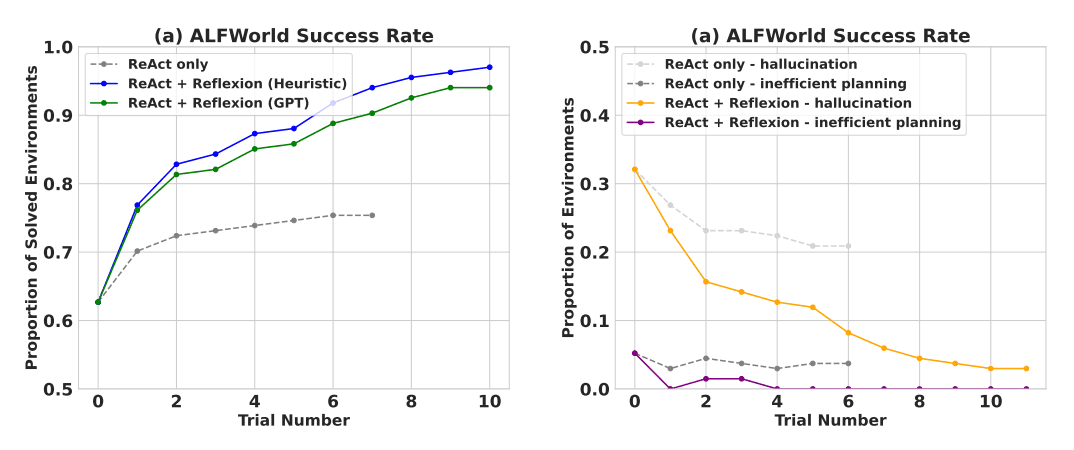
在顺序决策(AlfWorld)任务上进行评估时,ReAct + Reflexion 通过使用启发式和 GPT 的二元分类自评估技术,显著优于 ReAct,完成了 130/134 个任务。
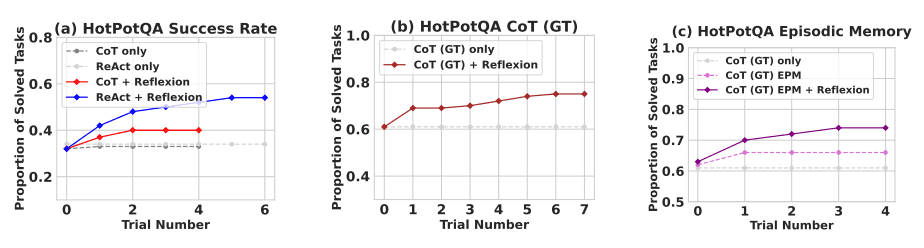
Reflexion 在多个学习步骤中显著优于所有基线方法。仅进行推理时,以及当添加由最近轨迹组成的情景记忆时,Reflexion + CoT 分别优于仅使用 CoT 和使用情景记忆的 CoT。
如下表总结所示,Reflexion 在 MBPP、HumanEval 和 Leetcode Hard 上的 Python 和 Rust 代码编写方面通常优于之前的最先进方法。

何时使用Reflexion?
Reflexion 最适合以下情况:
-
代理需要从试错中学习:Reflexion 旨在通过反思过去的错误并将这些知识融入未来的决策中,帮助代理提高其表现。这使得它非常适合代理需要通过试错学习的任务,例如决策、推理和编程。
-
传统的强化学习方法不切实际:传统的强化学习(RL)方法通常需要大量的训练数据和昂贵的模型微调。Reflexion 提供了一种轻量级的替代方案,不需要微调基础语言模型,从而在数据和计算资源方面更加高效。
-
需要细致的反馈:Reflexion 使用口头反馈,这比传统强化学习中使用的标量奖励更加细致和具体。这使得代理能够更好地理解其错误,并在后续试验中做出更有针对性的改进。
-
可解释性和显式记忆很重要:与传统RL方法相比,Reflexion提供了一种更可解释和显式的情景记忆形式。代理的自我反思存储在其记忆中,使得分析和理解其学习过程更加容易。
反思在以下任务中是有效的:
- 顺序决策: Reflexion 代理在 AlfWorld 任务中提高了性能,这些任务涉及在各种环境中导航并完成多步骤目标。
- 推理: Reflexion 提高了代理在 HotPotQA 上的表现,这是一个需要跨多个文档进行推理的问答数据集。
- 编程: Reflexion 代理在 HumanEval 和 MBPP 等基准测试中编写更好的代码,在某些情况下实现了最先进的结果。
以下是Reflexion的一些限制:
- 依赖自我评估能力:Reflexion依赖于代理准确评估其表现并生成有用的自我反思的能力。这可能具有挑战性,特别是对于复杂任务,但预计随着模型能力的不断提高,Reflexion会随着时间的推移变得更好。
- 长期记忆限制:Reflexion 使用了一个具有最大容量的滑动窗口,但对于更复杂的任务,使用向量嵌入或 SQL 数据库等高级结构可能更为有利。
- 代码生成限制: 在指定准确的输入输出映射时,测试驱动开发存在一些限制(例如,非确定性的生成器函数和受硬件影响的函数输出)。
图表来源:Reflexion: Language Agents with Verbal Reinforcement Learning (在新标签页中打开)