大型语言模型的检索增强生成(RAG)
在使用大型语言模型(LLMs)时,存在许多挑战,例如领域知识差距、事实性问题以及幻觉。检索增强生成(RAG)通过使用外部知识(如数据库)增强LLMs,提供了一种缓解其中一些问题的解决方案。RAG在知识密集型场景或需要持续更新知识的特定领域应用中特别有用。与其他方法相比,RAG的一个关键优势是LLM不需要为特定任务应用进行重新训练。RAG最近因其在对话代理中的应用而广受欢迎。
在本摘要中,我们重点介绍了最近一项名为《大型语言模型的检索增强生成:一项调查》(在新标签页中打开)(Gao等,2023)的调查的主要发现和实际见解。特别是,我们关注现有的方法、最先进的RAG、评估、应用以及围绕构成RAG系统的不同组件(检索、生成和增强技术)的技术。
RAG简介
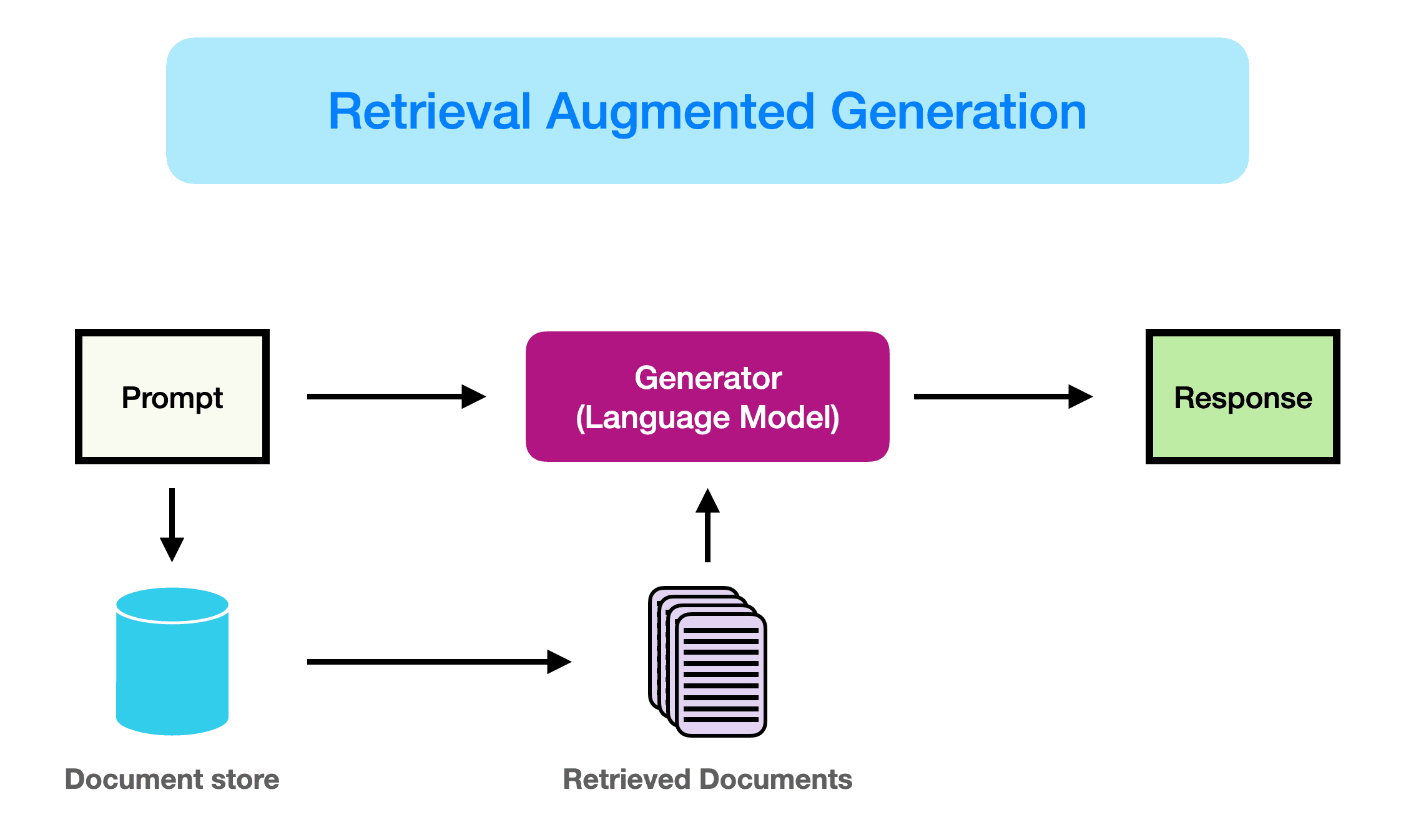
正如这里(在新标签页中打开)更好地介绍的那样,RAG可以定义为:
RAG接收输入并根据给定来源(例如,维基百科)检索一组相关/支持性文档。这些文档作为上下文与原始输入提示连接,并输入到文本生成器中,生成最终输出。这使得RAG能够适应事实可能随时间变化的情况。这非常有用,因为LLM的参数知识是静态的。RAG允许语言模型绕过重新训练,通过基于检索的生成访问最新信息,以生成可靠的输出。
简而言之,在RAG中检索到的证据可以作为提高LLM响应准确性、可控性和相关性的一种方式。这就是为什么RAG可以帮助减少在高度变化的环境中解决问题时的幻觉或性能问题。
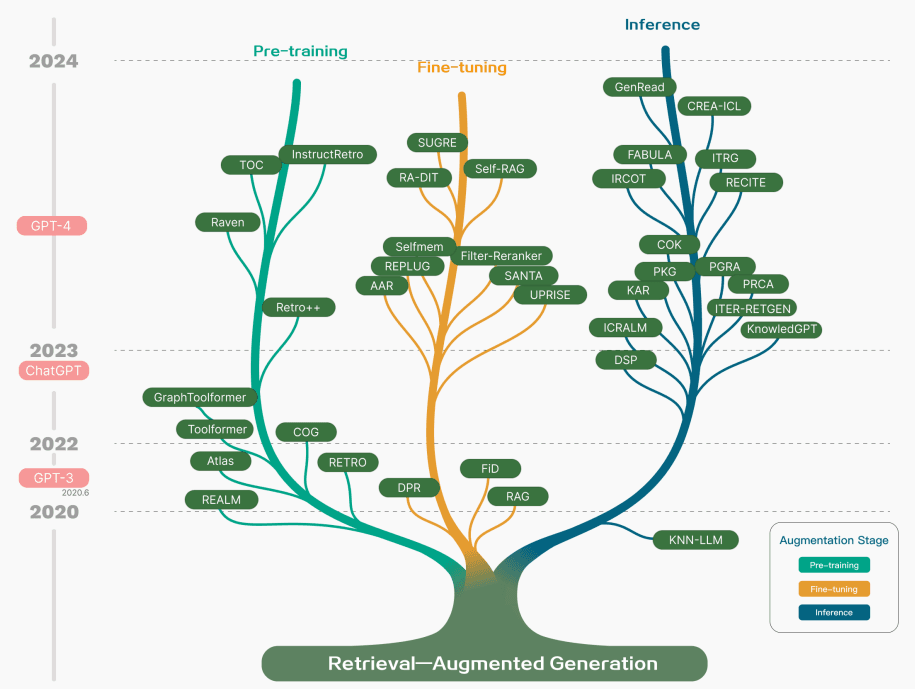
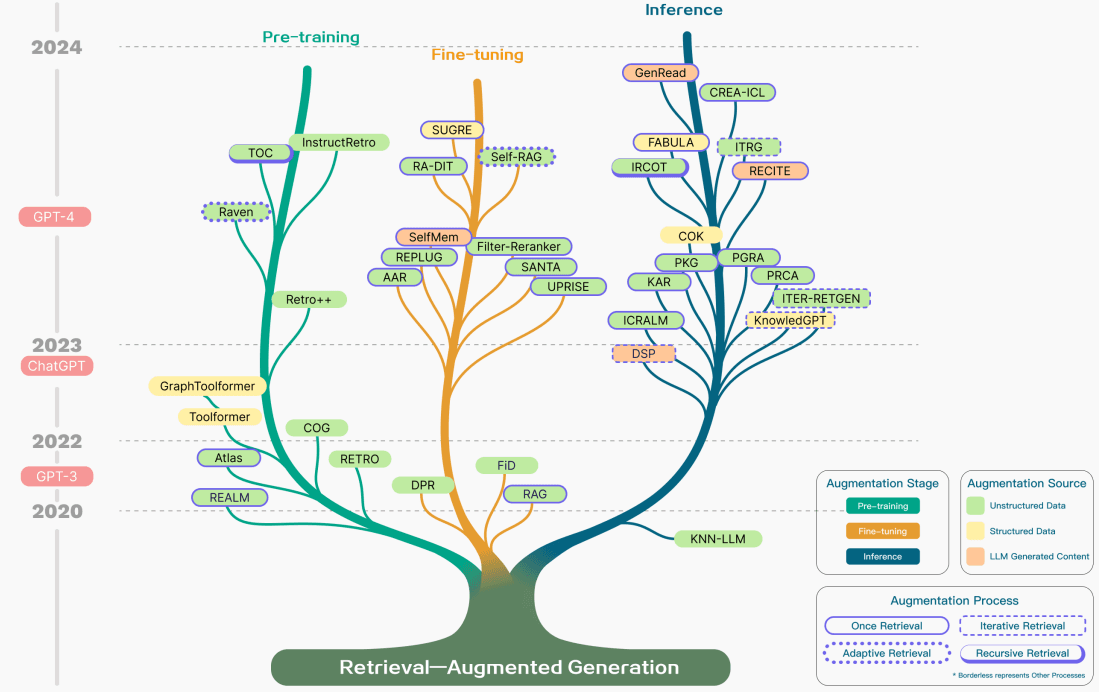
虽然RAG也涉及预训练方法的优化,但当前的方法已经主要转向结合RAG和强大的微调模型(如ChatGPT(在新标签页中打开)和Mixtral(在新标签页中打开))的优势。下图展示了RAG相关研究的演变:
下面是一个典型的RAG应用工作流程:
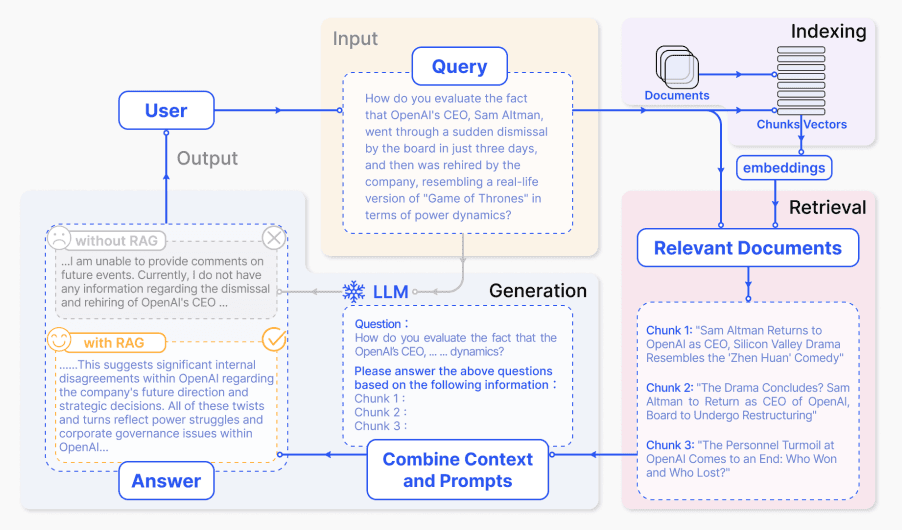
我们可以将不同的步骤/组件解释如下:
- 输入:LLM系统响应的问题被称为输入。如果没有使用RAG,则直接使用LLM来响应问题。
- 索引: 如果使用RAG,则首先通过分块一系列相关文档,生成这些块的嵌入,并将它们索引到向量存储中。在推理时,查询也以类似的方式嵌入。
- 检索:通过将查询与索引向量进行比较来获取相关文档,也称为“相关文档”。
- 生成:相关文档与原始提示结合作为附加上下文。然后将组合的文本和提示传递给模型以生成响应,随后将其准备为系统向用户的最终输出。
在提供的示例中,由于缺乏对当前事件的了解,直接使用模型无法回答问题。另一方面,当使用RAG时,系统可以提取模型适当回答问题所需的相关信息。
在我们的新AI课程中了解更多关于RAG和高级提示方法的信息。立即加入!(在新标签页中打开)
使用代码 PROMPTING20 可额外享受 20% 的折扣。
RAG 范式
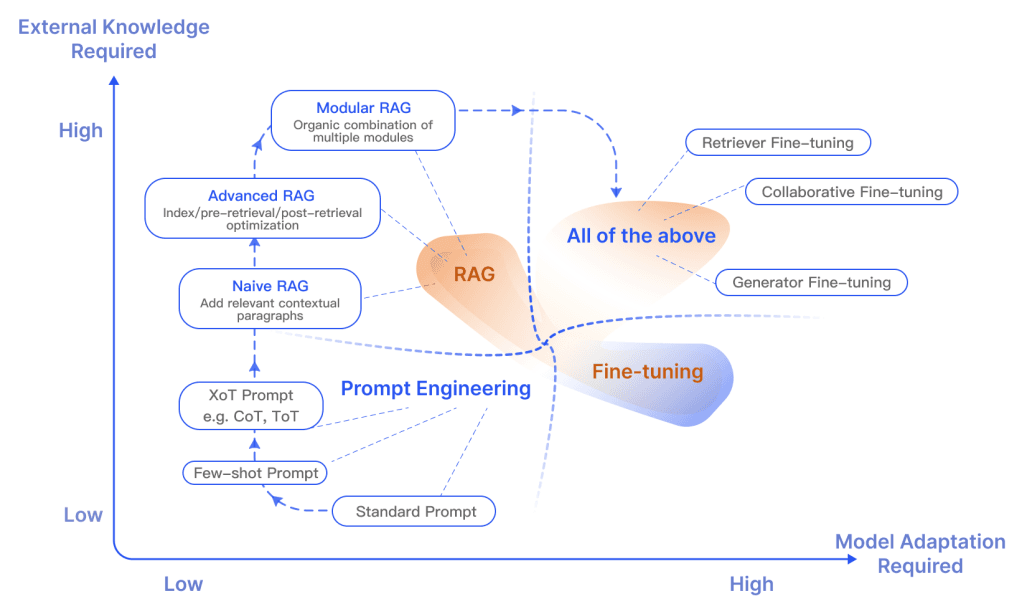
在过去的几年里,RAG系统已经从Naive RAG发展到Advanced RAG和Modular RAG。这种演变是为了解决性能、成本和效率方面的某些限制。
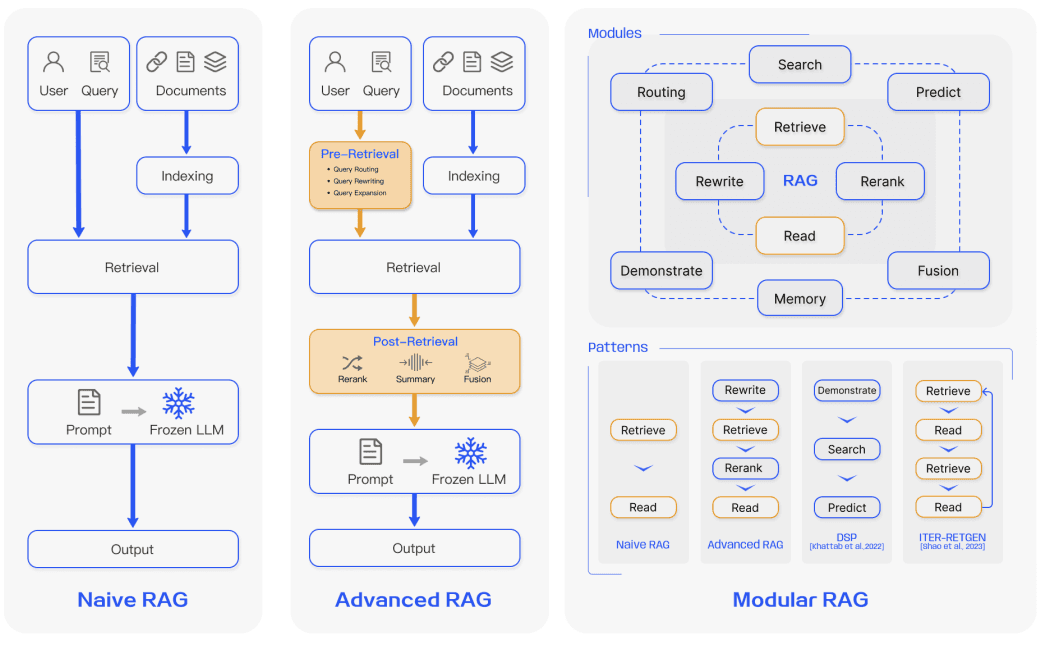
朴素RAG
Naive RAG 遵循上述传统的索引、检索和生成过程。简而言之,用户输入用于查询相关文档,然后这些文档与提示结合并传递给模型以生成最终响应。如果应用程序涉及多轮对话交互,则可以将对话历史集成到提示中。
Naive RAG 存在一些局限性,例如低精度(检索到的块不对齐)和低召回率(未能检索到所有相关块)。此外,LLM 可能会接收到过时的信息,这是 RAG 系统最初应该解决的主要问题之一。这会导致幻觉问题和糟糕且不准确的响应。
当应用增强时,也可能存在冗余和重复的问题。在使用多个检索到的段落时,排名和协调风格/语气也是关键。另一个挑战是确保生成任务不过度依赖增强信息,这可能导致模型只是重复检索到的内容。
高级RAG
高级RAG有助于解决Naive RAG中存在的问题,例如提高检索质量,这可能涉及优化检索前、检索和检索后的过程。
预检索过程涉及优化数据索引,旨在通过五个阶段提高被索引数据的质量:增强数据粒度、优化索引结构、添加元数据、对齐优化和混合检索。
检索阶段可以通过优化嵌入模型本身来进一步改进,这直接影响构成上下文的块的质量。这可以通过微调嵌入以优化检索相关性或采用更好地捕捉上下文理解的动态嵌入(例如,OpenAI的embeddings-ada-02模型)来实现。
优化检索后的重点在于避免上下文窗口限制和处理嘈杂或可能分散注意力的信息。解决这些问题的常见方法是重新排序,这可能涉及将相关上下文重新定位到提示的边缘或重新计算查询与相关文本块之间的语义相似性。提示压缩也可能有助于处理这些问题。
模块化RAG
顾名思义,模块化RAG增强了功能模块,例如结合搜索模块进行相似性检索,并在检索器中进行微调。朴素RAG和高级RAG都是模块化RAG的特殊情况,由固定模块组成。扩展的RAG模块包括搜索、记忆、融合、路由、预测和任务适配器,这些模块解决了不同的问题。这些模块可以重新排列以适应特定的问题背景。因此,模块化RAG受益于更大的多样性和灵活性,因为您可以根据任务需求添加或替换模块,或调整模块之间的流程。
鉴于构建RAG系统的灵活性增加,已经提出了其他重要的优化技术来优化RAG管道,包括:
- 混合搜索探索: 这种方法结合了基于关键词的搜索和语义搜索等多种搜索技术,以检索相关且内容丰富的信息;这在处理不同类型的查询和信息需求时非常有用。
- 递归检索和查询引擎: 涉及一个递归检索过程,可能从小的语义块开始,随后检索更大的块以丰富上下文;这对于平衡效率和上下文丰富的信息非常有用。
- StepBack-prompt: 一种提示技术 (在新标签页中打开),使LLMs能够进行抽象,产生指导推理的概念和原则;当应用于RAG框架时,这会导致更基础扎实的响应,因为LLM从具体实例中脱离出来,并在需要时允许更广泛的推理。
- 子查询: 有不同的查询策略,如树查询或顺序查询块,可用于不同的场景。LlamaIndex 提供了一个子问题查询引擎(在新标签页中打开),允许将查询分解为使用不同相关数据源的几个问题。
- 假设文档嵌入: HyDE (在新标签页中打开) 生成一个假设的答案来回答查询,将其嵌入,并使用它来检索与假设答案相似的文档,而不是直接使用查询。
RAG框架
在本节中,我们总结了RAG系统各组件的主要发展,包括检索、生成和增强。
检索
检索是RAG的一个组件,负责从检索器中检索高度相关的上下文。检索器可以通过多种方式进行增强,包括:
增强语义表示
这个过程涉及直接改进驱动检索器的语义表示。以下是几点考虑:
- 分块: 一个重要的步骤是选择合适的分块策略,这取决于你处理的内容以及你生成响应的应用程序。不同的模型在不同大小的块上也表现出不同的优势。句子转换器在单个句子上表现更好,但text-embedding-ada-002在包含256或512个标记的块上表现更好。其他需要考虑的方面包括用户问题的长度、应用程序和标记限制,但通常需要尝试不同的分块策略以帮助优化你的RAG系统中的检索。
- 微调的嵌入模型: 一旦你确定了一个有效的分块策略,如果你正在处理一个专业领域,可能需要微调嵌入模型。否则,用户查询在你的应用中可能会被完全误解。你可以在广泛的领域知识(即领域知识微调)和特定的下游任务上进行微调。BGE-large-EN由BAAI开发(在新标签页中打开) 是一个值得注意的嵌入模型,可以通过微调来优化检索相关性。
对齐查询和文档
这个过程涉及将用户的查询与文档在语义空间中的查询对齐。当用户的查询可能缺乏语义信息或包含不精确的措辞时,可能需要这样做。以下是一些方法:
- 查询重写: 专注于使用多种技术重写查询,例如 Query2Doc (在新标签页中打开)、ITER-RETGEN (在新标签页中打开) 和 HyDE。
- 嵌入转换:优化查询嵌入的表示,并将它们对齐到一个与任务更紧密相关的潜在空间。
对齐检索器和LLM
此过程涉及将检索器的输出与LLMs的偏好对齐。
- 微调检索器: 使用LLM的反馈信号来优化检索模型。示例包括适应增强检索器(AAR (在新标签页中打开))、REPLUG (在新标签页中打开)和UPRISE (在新标签页中打开)等。
- 适配器: 包含外部适配器以帮助对齐过程。示例包括 PRCA (在新标签页中打开)、RECOMP (在新标签页中打开) 和 PKG (在新标签页中打开)。
生成
RAG系统中的生成器负责将检索到的信息转换为连贯的文本,这些文本将构成模型的最终输出。这个过程涉及多种输入数据,有时需要努力优化语言模型对来自查询和文档的输入数据的适应。这可以通过使用检索后处理和微调来解决:
- 使用冻结的LLM进行后检索: 后检索处理保持LLM不变,而是通过信息压缩和结果重新排序等操作来增强检索结果的质量。信息压缩有助于减少噪音,解决LLM的上下文长度限制,并增强生成效果。重新排序旨在重新排列文档,以将最相关的项目优先放在顶部。
- 微调LLM用于RAG: 为了改进RAG系统,可以进一步优化或微调生成器,以确保生成的文本自然且有效利用检索到的文档。
增强
增强涉及将检索到的段落中的上下文有效地整合到当前生成任务中的过程。在进一步讨论增强过程、增强阶段和增强数据之前,以下是RAG核心组件的分类:
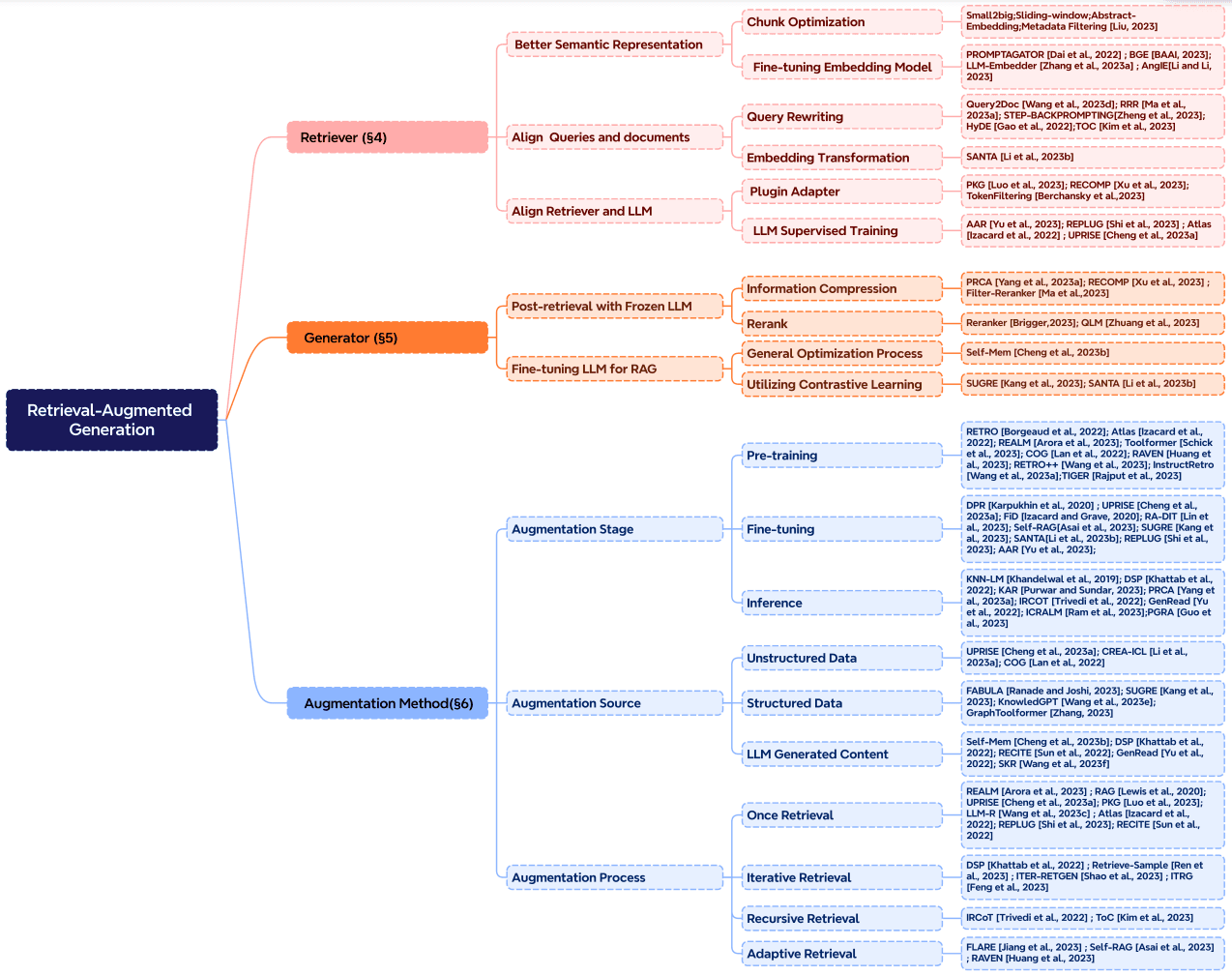
检索增强可以应用于许多不同的阶段,例如预训练、微调和推理。
-
增强阶段: RETRO (在新标签页中打开) 是一个利用检索增强进行大规模从头预训练的系统示例;它使用建立在外部知识之上的额外编码器。微调也可以与RAG结合使用,以帮助开发和改进RAG系统的有效性。在推理阶段,应用了许多技术来有效地整合检索到的内容,以满足特定任务需求,并进一步完善RAG过程。
-
增强来源: RAG模型的有效性在很大程度上受到增强数据源选择的影响。数据可以分为非结构化数据、结构化数据和LLM生成的数据。
-
Augmentation Process: For many problems (e.g., multi-step reasoning), a single retrieval isn't enough so a few methods have been proposed:
- Iterative retrieval enables the model to perform multiple retrieval cycles to enhance the depth and relevance of information. Notable approaches that leverage this method include RETRO (在新标签页中打开) and GAR-meets-RAG (在新标签页中打开).
- Recursive retrieval recursively iterates on the output of one retrieval step as the input to another retrieval step; this enables delving deeper into relevant information for complex and multi-step queries (e.g., academic research and legal case analysis). Notable approaches that leverage this method include IRCoT (在新标签页中打开) and 澄清树(在新标签页中打开).
- Adaptive retrieval tailors the retrieval process to specific demands by determining optimal moments and content for retrieval. Notable approaches that leverage this method include FLARE (在新标签页中打开) and Self-RAG (在新标签页中打开).
下图详细展示了RAG研究的不同增强方面,包括增强阶段、来源和过程。
RAG 与 微调
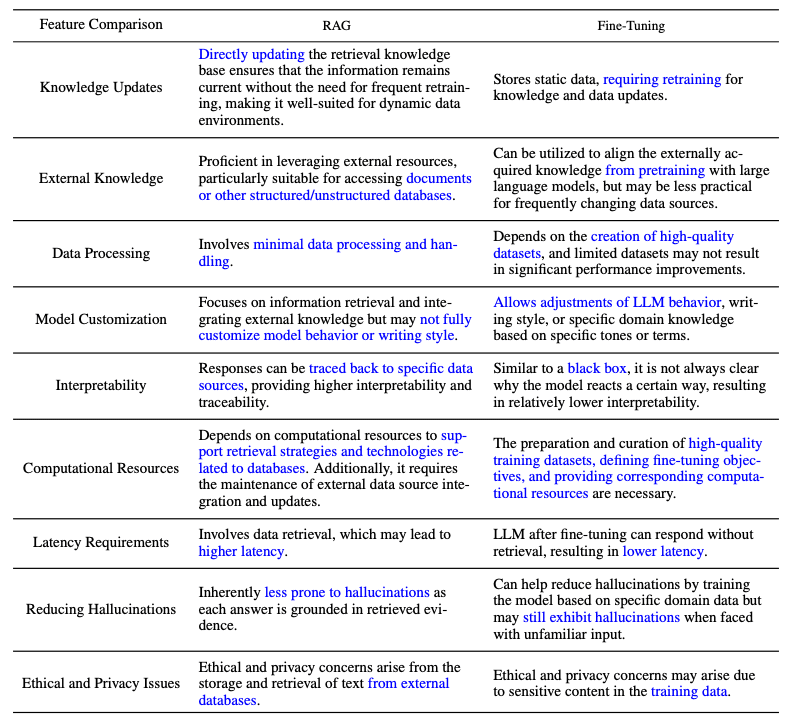
关于RAG和微调之间的区别以及各自适用的场景,有很多公开的讨论。在这两个领域的研究表明,RAG对于整合新知识很有用,而微调则可以通过改进内部知识、输出格式和教授复杂指令跟随来提高模型的性能和效率。这些方法并不相互排斥,可以在一个迭代过程中相互补充,旨在改进LLMs的使用,用于一个复杂知识密集型和可扩展的应用程序,该应用程序需要访问快速发展的知识,并按照特定的格式、语气和风格提供定制化的响应。此外,Prompting Engineering也可以通过利用模型的固有能力来帮助优化结果。下图展示了RAG与其他模型优化方法的不同特点:
以下是调查论文中比较RAG和微调模型特性的表格:
RAG评估
类似于衡量LLM在不同方面的表现,评估在理解和优化RAG模型在各种应用场景中的表现方面起着关键作用。传统上,RAG系统基于下游任务的表现进行评估,使用特定任务的指标如F1和EM。RaLLe (在新标签页中打开)是一个显著的例子,用于评估检索增强的大型语言模型在知识密集型任务中的表现。
RAG评估目标针对检索和生成两个方面,目的是评估检索到的上下文质量和生成的内容质量。为了评估检索质量,使用了推荐系统和信息检索等其他知识密集型领域中使用的指标,如NDCG和命中率。为了评估生成质量,可以评估不同方面,如未标记内容的相关性和有害性,或标记内容的准确性。总体而言,RAG评估可以涉及手动或自动评估方法。
评估RAG框架主要关注三个质量分数和四个能力。质量分数包括衡量上下文相关性(即检索到的上下文的精确性和特异性)、答案忠实度(即答案对检索到的上下文的忠实度)和答案相关性(即答案对提出问题的相关性)。此外,还有四个能力有助于衡量RAG系统的适应性和效率:噪声鲁棒性、负面拒绝、信息整合和反事实鲁棒性。以下是用于评估RAG系统不同方面的指标总结:
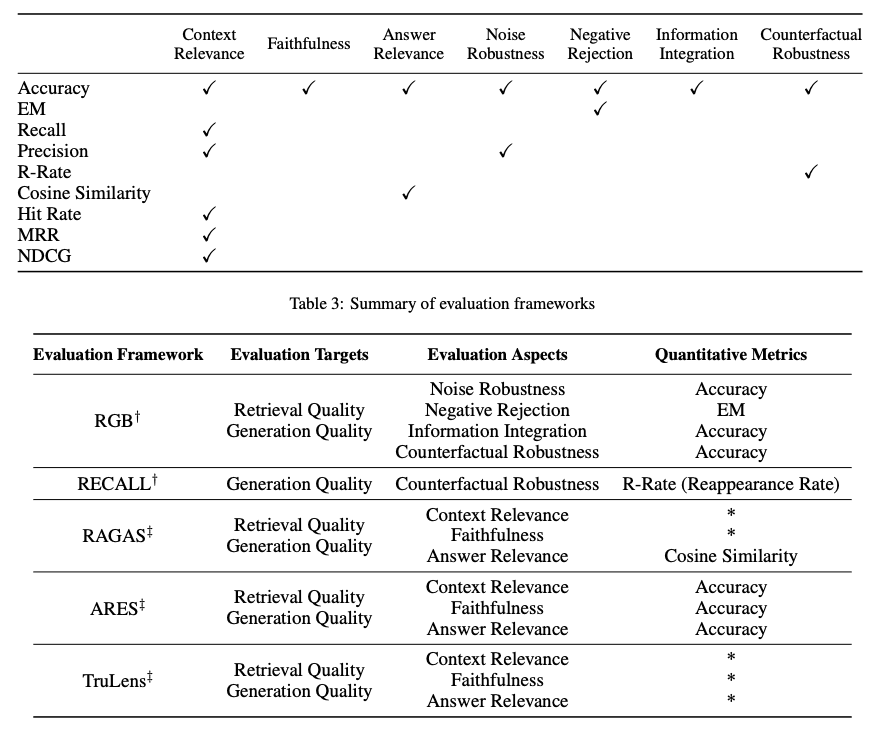
多个基准测试如RGB (在新标签页中打开)和RECALL (在新标签页中打开)被用来评估RAG模型。许多工具如RAGAS (在新标签页中打开)、ARES (在新标签页中打开)和TruLens (在新标签页中打开)已被开发出来,以自动化评估RAG系统的过程。一些系统依赖LLMs来确定上述定义的一些质量分数。
挑战与RAG的未来
在本概述中,我们讨论了RAG研究的几个研究方面以及增强RAG系统检索、增强和生成的不同方法。以下是Gao等人,2023(在新标签页中打开)强调的几个挑战,随着我们继续开发和改进RAG系统:
- 上下文长度: LLMs 继续扩展上下文窗口大小,这对如何调整 RAG 以确保捕获高度相关和重要的上下文提出了挑战。
- 鲁棒性: 处理反事实和对抗性信息对于在RAG中衡量和改进非常重要。
- 混合方法:目前正在进行研究,以更好地理解如何最佳地优化使用RAG和微调模型。
- 扩展LLM角色: 增加LLM的角色和能力以进一步增强RAG系统是高度关注的。
- 扩展法则:对LLM扩展法则及其如何应用于RAG系统的研究仍未被充分理解。
- 生产就绪的RAG:生产级的RAG系统需要在性能、效率、数据安全、隐私等方面达到卓越的工程水平。
- 多模态RAG:尽管围绕RAG系统已经有很多研究努力,但它们主要集中在基于文本的任务上。越来越多的人对扩展RAG系统的模态感兴趣,以支持解决更多领域的问题,如图像、音频和视频、代码等。
- 评估:使用RAG构建复杂应用程序的兴趣需要特别关注开发细致的指标和评估工具,这些工具可以更可靠地评估上下文相关性、创造力、内容多样性、事实性等方面。此外,还需要更好的可解释性研究和RAG工具。
RAG 工具
Some popular comprehensive tools to build RAG systems include LangChain (opens in a new tab), LlamaIndex (opens in a new tab), and DSPy (opens in a new tab). There are also a range of specialized tools that serve different purposes such as Flowise AI (opens in a new tab) that offers a low-code solution for building RAG applications. Other notables technologies include HayStack (opens in a new tab), Meltano (opens in a new tab), Cohere Coral (opens in a new tab), and others. Software and cloud service providers are also including RAG-centric services. For instance, Verba from Weaviate is useful for building personal assistant applications and Amazon's Kendra offers intelligent enterprise search services.
结论
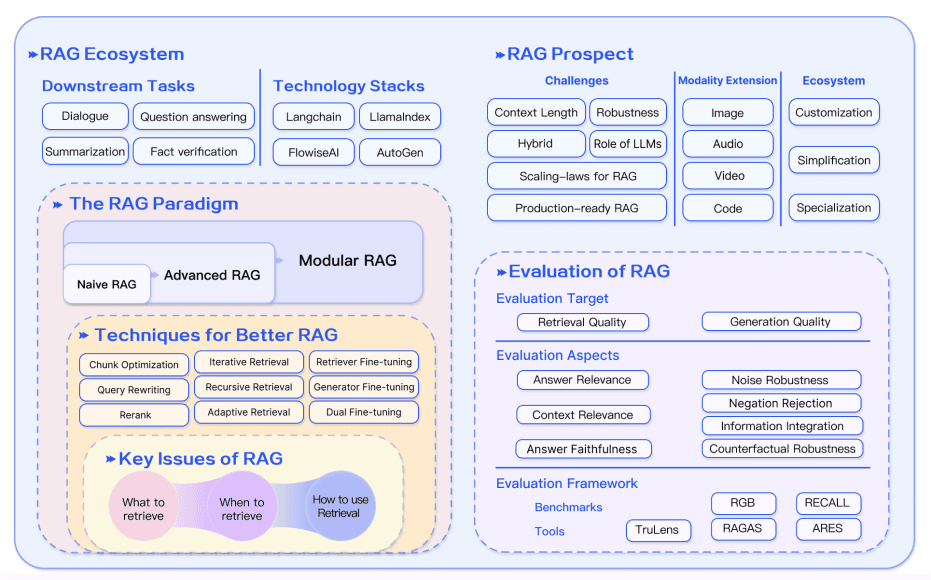
总之,RAG系统发展迅速,包括开发更先进的范式,这些范式能够实现定制化,并进一步提升RAG在广泛领域中的性能和实用性。对RAG应用的需求巨大,这加速了改进RAG系统不同组件的方法的开发。从混合方法到自检索,这些都是现代RAG模型当前探索的一些研究领域。对更好的评估工具和指标的需求也在不断增加。下图总结了RAG生态系统、增强RAG的技术、挑战以及本概述中涵盖的其他相关方面:
RAG研究见解
以下是一系列研究论文,重点介绍了RAG中的关键见解和最新发展。
| 洞察 | 参考 | 日期 |
|---|---|---|
| 展示了如何通过训练检索增强模拟器来使用检索增强来提炼语言模型助手 | KAUCUS: Knowledge Augmented User Simulators for Training Language Model Assistants (在新标签页中打开) | 2024年3月 |
| 提出了纠正性检索增强生成(CRAG),以提高RAG系统中生成的鲁棒性。核心思想是为检索器实现一个自我纠正组件,并提高检索文档的利用率以增强生成。检索评估器有助于评估给定查询下检索文档的整体质量。使用网络搜索和优化的知识利用操作可以提高自动自我纠正和检索文档的高效利用。 | Corrective Retrieval Augmented Generation (在新标签页中打开) | 2024年1月 |
| 递归地嵌入、聚类和总结文本块,自下而上构建具有不同总结层次的树。在推理时,提出的RAPTOR模型从树中检索,整合不同抽象层次的长文档信息。 | RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (在新标签页中打开) | 2024年1月 |
| 一个通用的程序,通过语言模型和检索器之间的多步交互,有效解决多标签分类问题。 | In-Context Learning for Extreme Multi-Label Classification (在新标签页中打开) | 2024年1月 |
| 从高资源语言中提取语义相似的提示,以提高多语言预训练语言模型在多样化任务中的零样本性能。 | From Classification to Generation: Insights into Crosslingual Retrieval Augmented ICL (在新标签页中打开) | 2023年11月 |
| 提高了RAG在面对嘈杂、不相关文档和处理未知场景时的鲁棒性。它为检索到的文档生成顺序阅读笔记,能够全面评估它们与给定问题的相关性,并整合信息以准备最终答案。 | Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models (在新标签页中打开) | 2023年11月 |
| 消除可能对优化读者答案生成过程不提供关键信息的标记。运行时间最多减少62.2%,而性能仅下降2%。 | 通过标记消除优化检索增强的读者模型 (在新标签页中打开) | 2023年10月 |
| 指令微调一个小型语言模型验证器,以验证知识增强语言模型的输出和知识,使用一个独立的验证器。这有助于解决模型可能无法检索到与给定查询相关的知识,或者模型在生成的文本中可能无法忠实反映检索到的知识的情况。 | Knowledge-Augmented Language Model Verification (在新标签页中打开) | 2023年10月 |
| 基准测试用于分析不同LLM在RAG所需的四项基本能力中的表现,包括噪声鲁棒性、负面拒绝、信息整合和反事实鲁棒性。 | Benchmarking Large Language Models in Retrieval-Augmented Generation (在新标签页中打开) | 2023年10月 |
| 介绍了自我反思检索增强生成(Self-RAG)框架,该框架通过检索和自我反思增强了语言模型的质量和事实性。它利用语言模型自适应地检索段落,并使用反思标记生成和反思检索到的段落及其自身的生成。 | Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection (在新标签页中打开) | 2023年10月 |
| 通过生成增强检索(GAR)迭代改进检索,并通过RAG改进重写,从而提高零样本信息检索的效果。重写-检索阶段提高了召回率,而重新排序阶段提高了精确度。 | GAR-meets-RAG Paradigm for Zero-Shot Information Retrieval (在新标签页中打开) | 2023年10月 |
| 使用基础43B GPT模型预训练一个48B的检索模型,并从1.2万亿个标记中进行检索。该模型进一步进行了指令调优,以展示在广泛的零样本任务上相较于指令调优的GPT有显著改进。 | InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining (在新标签页中打开) | 2023年10月 |
| 通过两个不同的微调步骤为LLM添加检索能力:一个步骤更新预训练的语言模型以更好地使用检索到的信息,另一个步骤更新检索器以返回更相关的结果,如语言模型所偏好的。通过在需要知识利用和上下文意识的任务上进行微调,每个阶段都能带来性能提升。 | RA-DIT: Retrieval-Augmented Dual Instruction Tuning (在新标签页中打开) | 2023年10月 |
| 一种使RAG对无关内容具有鲁棒性的方法。它自动生成数据以微调语言模型,使其能够正确利用检索到的段落,在训练时使用相关和无关上下文的混合。 | Making Retrieval-Augmented Language Models Robust to Irrelevant Context (在新标签页中打开) | 2023年10月 |
| 发现使用简单检索增强生成的4K上下文窗口的LLMs在长上下文任务上通过位置插值实现的性能与16K上下文窗口的微调LLMs相当。 | Retrieval meets Long Context Large Language Models (在新标签页中打开) | 2023年10月 |
| 在上下文集成之前,将检索到的文档压缩为文本摘要,这减少了计算成本,并减轻了语言模型在长检索文档中识别相关信息的负担。 | RECOMP: 通过压缩和选择性增强改进检索增强型语言模型 (在新标签页中打开) | 2023年10月 |
| 一个迭代的检索-生成协作框架,利用参数化和非参数化知识,并通过检索-生成交互帮助找到正确的推理路径。适用于需要多步推理的任务,并整体提高LLMs的推理能力。 | Retrieval-Generation Synergy Augmented Large Language Models (在新标签页中打开) | 2023年10月 |
| 提出了澄清树(ToC)框架,该框架通过利用外部知识的少量提示,递归构建模糊问题的消歧树。然后,它使用该树生成长篇答案。 | Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models (在新标签页中打开) | 2023年10月 |
| 一种方法,让LLM参考它之前遇到的问题,并在遇到新问题时自适应地调用外部资源。 | Self-Knowledge Guided Retrieval Augmentation for Large Language Models (在新标签页中打开) | 2023年10月 |
| 一套可用于评估不同维度的指标(即检索系统识别相关和聚焦上下文段落的能力,LLM以忠实方式利用这些段落的能力,或生成本身的质量),而无需依赖真实的人类注释。 | RAGAS: Automated Evaluation of Retrieval Augmented Generation (在新标签页中打开) | 2023年9月 |
| 提出了一种生成后阅读(GenRead)方法,该方法首先提示大型语言模型根据给定问题生成上下文文档,然后阅读生成的文档以产生最终答案。 | 生成而非检索:大型语言模型是强大的上下文生成器 (在新标签页中打开) | 2023年9月 |
| 展示了如何在RAG系统中利用DiversityRanker和LostInTheMiddleRanker等排序器来选择和利用信息,以优化LLM上下文窗口的利用率。 | Enhancing RAG Pipelines in Haystack: Introducing DiversityRanker and LostInTheMiddleRanker (在新标签页中打开) | 2023年8月 |
| 将大型语言模型(LLMs)与各种知识库(KBs)连接起来,促进知识的检索和存储。检索过程采用思维程序提示,生成以代码格式的搜索语言,用于知识库操作,并提供预定义函数。它还提供了将知识存储在个性化知识库中的能力,以满足个人用户的需求。 | KnowledGPT: Enhancing Large Language Models with Retrieval and Storage Access on Knowledge Bases (在新标签页中打开) | 2023年8月 |
| 提出了一个结合检索增强掩码语言建模和前缀语言建模的模型。然后,它引入了上下文融合学习,通过使模型能够利用更多的上下文示例而不需要额外的训练来增强少样本性能。 | RAVEN: In-Context Learning with Retrieval Augmented Encoder-Decoder Language Models (opens in a new tab) | 2023年8月 |
| RaLLe 是一个开源框架,用于开发、评估和优化用于知识密集型任务的 RAG 系统。 | RaLLe: 一个用于开发和评估检索增强大型语言模型的框架 (在新标签页中打开) | 2023年8月 |
| 发现当改变相关信息的位置时,LLM的性能可能会显著下降,这表明LLM在长输入上下文中并不能稳健地利用信息。 | Lost in the Middle: How Language Models Use Long Contexts (在新标签页中打开) | 2023年7月 |
| 以迭代方式协同检索和生成。模型输出用于显示完成任务所需的内容,为检索更相关的知识提供信息丰富的上下文,从而在下一轮迭代中帮助生成更好的输出。 | Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy (在新标签页中打开) | 2023年5月 |
| 提供了对主动RAG的广义视图,这些方法在生成过程中主动决定何时以及检索什么。然后,提出了前瞻性主动检索增强生成(FLARE),这是一种迭代使用即将到来的句子的预测来预见未来内容的方法,然后将其用作查询以检索相关文档,如果句子中包含低置信度的标记,则重新生成该句子。 | Active Retrieval Augmented Generation (在新标签页中打开) | 2023年5月 |
| 介绍了一个通用的检索插件,该插件利用通用检索器来增强可能事先未知或无法联合微调的目标语言模型。 | 增强适应的检索器作为通用插件提高语言模型的泛化能力 (在新标签页中打开) | 2023年5月 |
| 通过两种预训练策略改进结构化数据的密集检索。首先,它利用结构化和非结构化数据之间的自然对齐进行结构感知预训练。然后,它实施掩码实体预测以进行掩码实体预测并捕捉结构语义。 | Structure-Aware Language Model Pretraining Improves Dense Retrieval on Structured Data (在新标签页中打开) | 2023年5月 |
| 动态整合来自多个领域的异构来源的接地信息,以增强LLMs的事实准确性。引入了一个自适应查询生成器,以处理针对不同知识源定制的查询。该框架逐步修正推理过程,确保先前推理中的不准确之处不会传播到后续步骤。 | Chain-of-Knowledge: Grounding Large Language Models via Dynamic Knowledge Adapting over Heterogeneous Sources (在新标签页中打开) | 2023年5月 |
| 一个框架,用于生成与知识图谱(KG)相关的上下文相关和知识基础的对话。它首先从KG中检索相关的子图,然后通过根据检索到的子图调整其词嵌入来确保事实的一致性。接着,它利用对比学习来确保生成的文本与检索到的子图具有高度相似性。 | Knowledge Graph-Augmented Language Models for Knowledge-Grounded Dialogue Generation (在新标签页中打开) | 2023年5月 |
| 采用一个小型语言模型作为可训练的改写器,以适应黑箱LLM阅读器。改写器通过强化学习使用LLM阅读器的反馈进行训练。结果形成了一个名为Rewrite-Retrieve-Read的新框架,重点是优化查询。 | Query Rewriting for Retrieval-Augmented Large Language Models (在新标签页中打开) | 2023年5月 |
| 迭代地使用检索增强生成器来创建一个无界的内存池,并使用内存选择器选择一个输出作为后续生成轮次的内存。这使得模型能够利用其自身的输出,称为自我记忆,以改进生成。 | Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory (在新标签页中打开) | 2023年5月 |
| 为LLMs配备了一个知识引导模块,以访问相关知识而不改变其参数。它提高了“黑箱”LLMs在一系列需要事实(+7.9%)、表格(+11.9%)、医学(+3.0%)和多模态(+8.1%)知识的领域知识密集型任务上的表现。 | Augmented Large Language Models with Parametric Knowledge Guiding (在新标签页中打开) | 2023年5月 |
| 为LLMs配备了一个通用的读写记忆单元,使它们能够根据需要从文本中提取、存储和回忆知识,以完成任务。 | RET-LLM: Towards a General Read-Write Memory for Large Language Models (在新标签页中打开) | 2023年5月 |
| 采用任务无关的检索器来构建共享的静态索引,并高效地选择候选证据。然后,设计一个提示引导的重新排序器,根据任务特定的相关性为读者重新排序最近的证据。 | Prompt-Guided Retrieval Augmentation for Non-Knowledge-Intensive Tasks (在新标签页中打开) | 2023年5月 |
| 提出了UPRISE(通用提示检索以改进零样本评估),它调整了一个轻量级且多功能的检索器,该检索器自动检索给定零样本任务输入的提示。 | UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation (在新标签页中打开) | 2023年3月 |
| 一种结合了SLM(作为过滤器)和LLM(作为重新排序器)优势的自适应过滤后重新排序范式。 | 大型语言模型不是一个好的少样本信息提取器,但对于困难样本是一个好的重新排序器! (在新标签页中打开) | 2023年3月 |
| 零样本指示一个遵循指令的大型语言模型生成一个假设文档,该文档捕捉相关性模式。然后,Contriever 将文档编码为一个嵌入向量,该向量用于在语料库嵌入空间中识别一个邻域,其中基于向量相似性检索出相似的现实文档。 | Precise Zero-Shot Dense Retrieval without Relevance Labels (在新标签页中打开) | 2022年12月 |
| 提出了Demonstrate-Search-Predict (DSP)框架,用于构建高级程序,这些程序能够引导管道感知的演示,搜索相关段落,并生成基于事实的预测,系统地将问题分解为可以更可靠处理的小型转换。 | Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP (在新标签页中打开) | 2022年12月 |
| 一种多步骤问答的方法,它在思维链(CoT)中交替进行检索和步骤,用CoT指导检索,并反过来使用检索结果来改进CoT。这有助于提高知识密集型多步骤问题的性能。 | Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions (在新标签页中打开) | 2022年12月 |
| 展示了检索增强可以减少对相关预训练信息的依赖,这使得RAG成为捕捉长尾知识的一种有前景的方法。 | 大型语言模型在学习长尾知识方面存在困难 (在新标签页中打开) | 2022年11月 |
| 通过采样从LLMs自己的记忆中背诵一个或多个相关段落,然后生成最终答案。 | Recitation-Augmented Language Models (在新标签页中打开) | 2022年10月 |
| 利用LLMs作为少量示例查询生成器,并基于生成的数据创建特定任务的检索器。 | Promptagator: Few-shot Dense Retrieval From 8 Examples (在新标签页中打开) | 2022年9月 |
| 介绍了Atlas,一个预训练的检索增强语言模型,能够通过极少的训练示例学习知识密集型任务。 | Atlas: Few-shot Learning with Retrieval Augmented Language Models (在新标签页中打开) | 2022年8月 |
| 从训练数据中检索,以在多个NLG和NLU任务上实现增益。 | 训练数据比你想象的更有价值:通过从训练数据中检索的简单有效方法 (在新标签页中打开) | 2022年3月 |
| 通过保存连续数据存储条目之间的指针,并将这些条目聚类成状态,近似于数据存储搜索。结果是一个加权的有限自动机,在推理时,有助于在不影响困惑度的情况下,比kNN-LM节省多达83%的最近邻搜索。 | Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval (在新标签页中打开) | 2022年1月 |
| 通过基于与前面标记的局部相似性,从大型语料库中检索文档块来改进自回归语言模型。它通过从2万亿标记数据库中检索来增强模型。 | Improving language models by retrieving from trillions of tokens (在新标签页中打开) | 2021年12月 |
| 一种新颖的零样本槽填充方法,通过硬负样本和鲁棒训练程序扩展了密集段落检索,用于检索增强生成模型。 | Robust Retrieval Augmented Generation for Zero-shot Slot Filling (opens in a new tab) | 2021年8月 |
| 介绍了RAG模型,其中参数化记忆是一个预训练的seq2seq模型,非参数化记忆是维基百科的密集向量索引,通过预训练的神经检索器访问。它比较了两种RAG公式,一种是在整个生成序列中使用相同的检索段落,另一种是每个标记使用不同的段落。 | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (在新标签页中打开) | 2020年5月 |
| 展示了仅使用密集表示即可实现检索,其中嵌入是通过简单的双编码器框架从少量问题和段落中学习的。 | Dense Passage Retrieval for Open-Domain Question Answering (在新标签页中打开) | 2020年4月 |
参考文献
- KAUCUS: 用于训练语言模型助手的知识增强用户模拟器 (在新标签页中打开)
- 大型语言模型中的幻觉研究:原理、分类、挑战与开放问题 (在新标签页中打开)
- 知识密集型NLP任务的检索增强生成 (在新标签页中打开)
- 检索增强的多模态语言建模 (在新标签页中打开)
- 上下文检索增强语言模型 (在新标签页中打开)
- 无需相关性标签的精确零样本密集检索 (在新标签页中打开)
- 我们是否应该使用检索来预训练自回归语言模型?一项全面研究。 (在新标签页中打开)
- REPLUG: 检索增强的黑箱语言模型 (在新标签页中打开)
- Query2Doc (在新标签页中打开)
- ITER-RETGEN (在新标签页中打开)
- 最大化LLM性能的技术调查 (在新标签页中打开)
- HyDE (在新标签页中打开)
- 高级RAG技术:图解概述 (在新标签页中打开)
- LLM评估RAG应用的最佳实践 (在新标签页中打开)
- 构建生产就绪的RAG应用程序 (在新标签页中打开)
- 评估RAG第一部分:如何评估文档检索 (在新标签页中打开)
- 检索增强生成与互惠排名融合和生成查询的相遇 (在新标签页中打开)