思维树 (ToT)
对于需要探索或战略前瞻的复杂任务,传统或简单的提示技术是不够的。Yao et el. (2023) (在新标签页中打开) 和 Long (2023) (在新标签页中打开) 最近提出了思维树(ToT)框架,该框架推广了链式思维提示,并鼓励探索作为使用语言模型解决一般问题的中间步骤的思维。
ToT 维护一个思维树,其中思维代表连贯的语言序列,作为解决问题的中间步骤。这种方法使语言模型能够通过深思熟虑的推理过程自我评估在解决问题过程中通过中间思维取得的进展。然后,将语言模型生成和评估思维的能力与搜索算法(例如,广度优先搜索和深度优先搜索)相结合,以通过前瞻和回溯实现思维的系统性探索。
ToT框架如下所示:
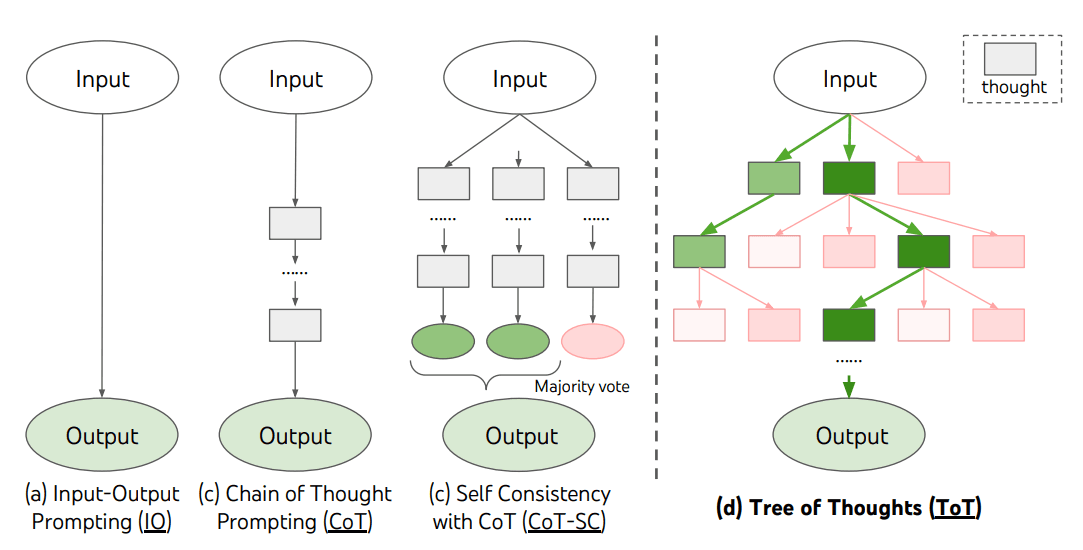
图片来源: Yao et el. (2023) (在新标签页中打开)
使用ToT时,不同的任务需要定义候选者的数量和思考/步骤的数量。例如,如论文中所示,24点游戏被用作一个数学推理任务,需要将思考分解为3个步骤,每个步骤都涉及一个中间方程。在每个步骤中,保留最佳的b=5个候选者。
为了在ToT中执行24点游戏的BFS,LM被提示评估每个候选思路,判断其是否“确定/可能/不可能”达到24。正如作者所述,“目的是推广那些可以在少量前瞻试验中被验证的正确部分解决方案,并基于‘太大/太小’的常识消除不可能的部分解决方案,其余的则保持‘可能’”。每个思路的值被采样3次。该过程如下图所示:
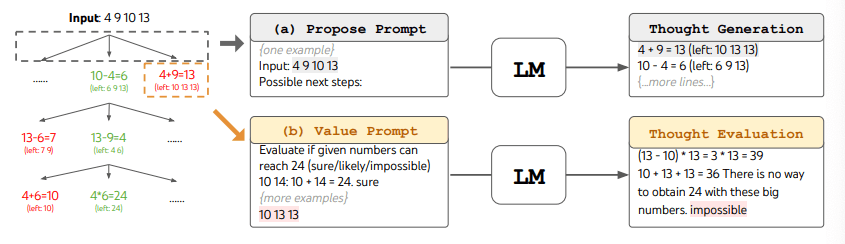
图片来源:Yao et el. (2023) (在新标签页中打开)
从下图报告的结果来看,ToT 显著优于其他提示方法:
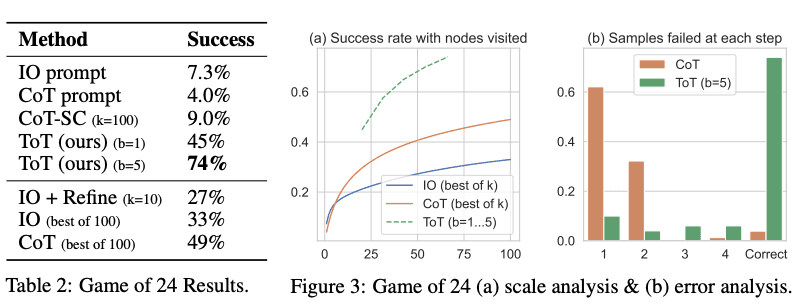
图片来源: Yao et el. (2023) (在新标签页中打开)
代码可在此处这里(在新标签页中打开)和这里(在新标签页中打开)获取
在高层次上,Yao et el. (2023) (在新标签页中打开) 和 Long (2023) (在新标签页中打开) 的主要思想是相似的。两者都通过多轮对话的树搜索增强了LLM解决复杂问题的能力。主要区别之一是 Yao et el. (2023) (在新标签页中打开) 利用了DFS/BFS/beam搜索,而 Long (2023) (在新标签页中打开) 提出的树搜索策略(即何时回溯以及回溯多少层等)是由通过强化学习训练的“ToT控制器”驱动的。DFS/BFS/Beam搜索是通用的解决方案搜索策略,没有针对特定问题的适应性。相比之下,通过RL训练的ToT控制器可能能够从新数据集中学习或通过自我对弈(AlphaGo与暴力搜索)学习,因此基于RL的ToT系统即使使用固定的LLM也可以继续发展和学习新知识。
Hulbert (2023) (在新标签页中打开) 提出了树状思维提示(Tree-of-Thought Prompting),该方法将ToT框架的主要概念应用为一种简单的提示技术,使LLM能够在单个提示中评估中间思维。一个ToT提示的示例如下:
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...Sun (2023) (在新标签页中打开) 通过大规模实验对Tree-of-Thought Prompting进行了基准测试,并介绍了PanelGPT --- 一种通过LLMs之间的Panel讨论进行提示的想法。