


训练一个代理¶
本页提供了一个简短的概述,介绍如何为一个 Gymnasium 环境训练一个代理,特别是我们将使用基于表格的 Q-学习来解决 Blackjack v1 环境。有关此教程的完整版本以及更多其他环境和算法的训练教程,请参见 此链接。在阅读本页之前,请先阅读 基本用法。在我们实现任何代码之前,这里是对 Blackjack 和 Q-学习的概述。
二十一点是最受欢迎的赌场纸牌游戏之一,同时也因其在某些条件下可被击败而声名狼藉。这个版本的游戲使用无限牌堆(我们抽牌后会放回),所以在我们的模拟游戏中,记牌将不是一个可行的策略。观察结果是一个元组,包含玩家当前的总和、庄家明牌的值以及一个布尔值,表示玩家是否持有可用的王牌。代理可以选择两种动作之一:站立(0),玩家不再抽牌;或击打(1),玩家将再抽一张牌。要获胜,你的牌总和应大于庄家的总和,但不超过21。如果玩家选择站立或牌总和超过21,游戏结束。完整的文档可以在https://gymnasium.farama.org/environments/toy_text/blackjack找到。
Q-learning 是由 Watkins 在 1989 年提出的一种无模型、离策略的学习算法,适用于具有离散动作空间的环境,并且因其是第一个在特定条件下证明收敛到最优策略的强化学习算法而闻名。
执行一个动作¶
在接收到我们的第一个观察结果后,我们将只使用env.step(action)函数与环境进行交互。此函数将一个动作作为输入并在环境中执行它。因为该动作改变了环境的状态,它返回四个有用的变量给我们。这些是:
next observation: 这是智能体在采取行动后将接收到的观察结果。reward: 这是代理在采取行动后将获得的奖励。terminated: 这是一个布尔变量,表示环境是否已终止,即由于内部条件而结束。truncated: 这是一个布尔变量,也表示剧集是否因早期截断而结束,即达到了时间限制。info: 这是一个字典,可能包含有关环境的附加信息。
next observation、reward、terminated 和 truncated 变量是自解释的,但 info 变量需要一些额外的解释。这个变量包含一个字典,可能包含有关环境的额外信息,但在 Blackjack-v1 环境中你可以忽略它。例如,在 Atari 环境中,info 字典有一个 ale.lives 键,它告诉我们代理还剩下多少条命。如果代理的生命数为 0,那么该集就结束了。
请注意,在训练循环中调用 env.render() 不是一个好主意,因为渲染会大大减慢训练速度。相反,尝试在训练后构建一个额外的循环来评估和展示代理。
构建一个代理¶
让我们构建一个 Q-learning 代理来解决二十一点问题!我们需要一些函数来选择动作和更新代理的动作值。为了确保代理探索环境,一种可能的解决方案是 epsilon-greedy 策略,其中我们以 epsilon 百分比选择一个随机动作,并以 1 - epsilon 选择贪婪动作(当前被认为最佳的动作)。
from collections import defaultdict
import gymnasium as gym
import numpy as np
class BlackjackAgent:
def __init__(
self,
env: gym.Env,
learning_rate: float,
initial_epsilon: float,
epsilon_decay: float,
final_epsilon: float,
discount_factor: float = 0.95,
):
"""Initialize a Reinforcement Learning agent with an empty dictionary
of state-action values (q_values), a learning rate and an epsilon.
Args:
env: The training environment
learning_rate: The learning rate
initial_epsilon: The initial epsilon value
epsilon_decay: The decay for epsilon
final_epsilon: The final epsilon value
discount_factor: The discount factor for computing the Q-value
"""
self.env = env
self.q_values = defaultdict(lambda: np.zeros(env.action_space.n))
self.lr = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.training_error = []
def get_action(self, obs: tuple[int, int, bool]) -> int:
"""
Returns the best action with probability (1 - epsilon)
otherwise a random action with probability epsilon to ensure exploration.
"""
# with probability epsilon return a random action to explore the environment
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
# with probability (1 - epsilon) act greedily (exploit)
else:
return int(np.argmax(self.q_values[obs]))
def update(
self,
obs: tuple[int, int, bool],
action: int,
reward: float,
terminated: bool,
next_obs: tuple[int, int, bool],
):
"""Updates the Q-value of an action."""
future_q_value = (not terminated) * np.max(self.q_values[next_obs])
temporal_difference = (
reward + self.discount_factor * future_q_value - self.q_values[obs][action]
)
self.q_values[obs][action] = (
self.q_values[obs][action] + self.lr * temporal_difference
)
self.training_error.append(temporal_difference)
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)
训练代理¶
为了训练代理,我们将让代理一次玩一个回合(一个完整的游戏称为一个回合),然后在每个回合后更新其Q值。代理需要经历许多回合以充分探索环境。
# hyperparameters
learning_rate = 0.01
n_episodes = 100_000
start_epsilon = 1.0
epsilon_decay = start_epsilon / (n_episodes / 2) # reduce the exploration over time
final_epsilon = 0.1
agent = BlackjackAgent(
learning_rate=learning_rate,
initial_epsilon=start_epsilon,
epsilon_decay=epsilon_decay,
final_epsilon=final_epsilon,
)
信息:当前的超参数设置为快速训练一个不错的代理。如果你想收敛到最优策略,尝试将 n_episodes 增加10倍并降低学习率(例如,降低到0.001)。
from tqdm import tqdm
env = gym.make("Blackjack-v1", sab=False)
env = gym.wrappers.RecordEpisodeStatistics(env, deque_size=n_episodes)
for episode in tqdm(range(n_episodes)):
obs, info = env.reset()
done = False
# play one episode
while not done:
action = agent.get_action(obs)
next_obs, reward, terminated, truncated, info = env.step(action)
# update the agent
agent.update(obs, action, reward, terminated, next_obs)
# update if the environment is done and the current obs
done = terminated or truncated
obs = next_obs
agent.decay_epsilon()
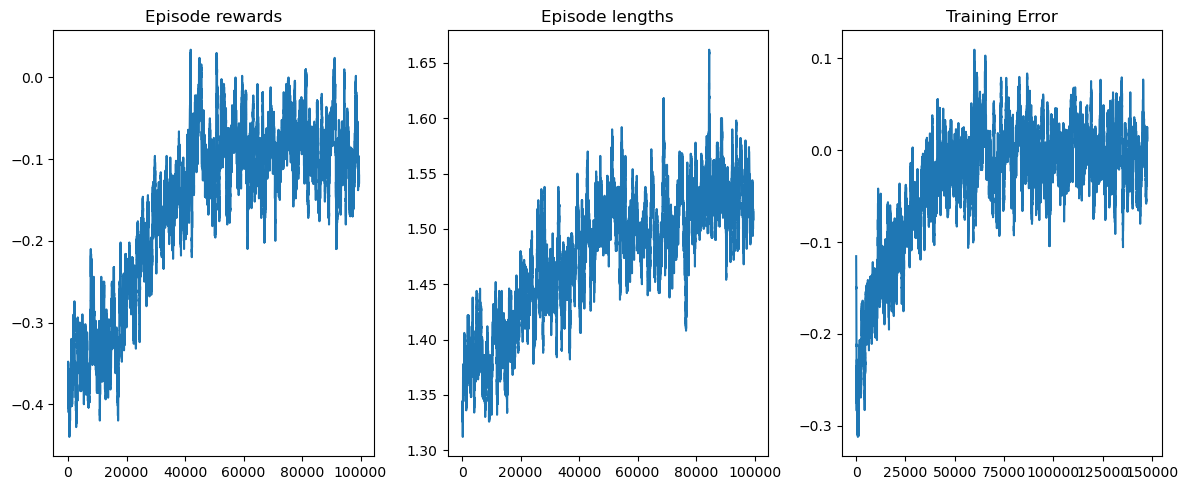
可视化策略¶
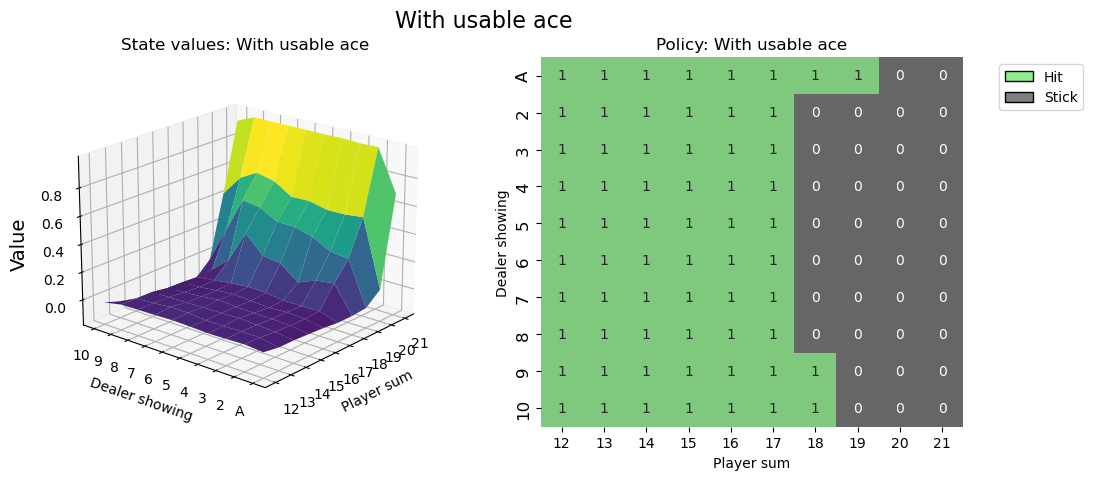
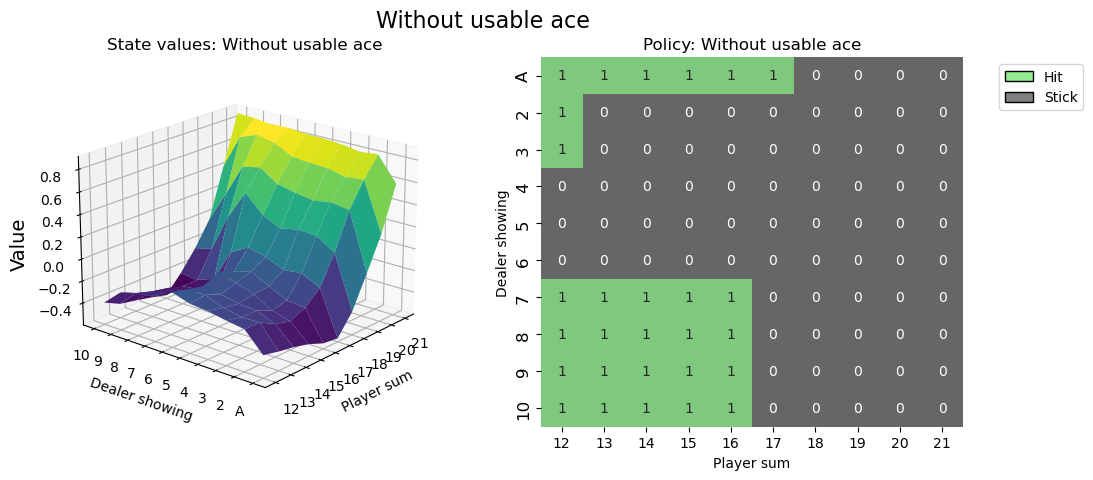
希望本教程帮助你掌握了如何与 Gymnasium 环境交互,并为你解决更多强化学习挑战的旅程奠定了基础。
建议你自己解决这个环境(基于项目的学习非常有效!)。你可以应用你喜欢的离散强化学习算法,或者尝试蒙特卡洛ES(在 Sutton & Barto <http://incompleteideas.net/book/the-book-2nd.html>_ 的第5.3节中有介绍)——这样你可以直接将你的结果与书中的进行比较。
祝你好运!