


使用向量环境与领域随机化训练A2C¶
注意¶
如果你遇到一个在 multiprocessing/spawn.py 中引发的类似以下注释的 RuntimeError,请将代码从 gym.vector.make= 或 gym.vector.AsyncVectorEnv 到代码末尾的部分用 if__name__ == '__main__' 包裹起来。
在当前进程完成引导阶段之前,已尝试启动一个新进程。
介绍¶
在本教程中,您将学习如何使用矢量化环境来训练一个优势演员-评论家代理。我们将使用A2C,这是A3C算法的同步版本[1]。
矢量化环境 [3] 可以通过允许多个相同环境的实例并行运行(在多个CPU上)来帮助实现更快和更稳健的训练。这可以显著减少方差,从而加快训练速度。
我们将从头开始实现一个优势动作-评价(Advantage Actor-Critic)模型,以了解如何将批量状态输入到网络中以获取动作向量(每个环境一个动作),并在小批量过渡中计算动作和评价的损失。每个小批量包含一个采样阶段的过渡:在 n_envs 个环境中并行执行 n_steps_per_update 步(将两者相乘以获得小批量中的过渡数量)。在每个采样阶段之后,计算损失并执行一次梯度步骤。为了计算优势,我们将使用广义优势估计(Generalized Advantage Estimation, GAE)方法 [2],该方法平衡了优势估计的方差和偏差之间的权衡。
A2C 代理类通过输入状态的特征数量、代理可以采取的动作数量、学习率和并行运行的环境数量进行初始化。定义了参与者和评论家网络,并初始化了它们各自的优化器。网络的前向传递接收一批状态向量,并返回状态值的张量和动作对数概率的张量。select_action 方法返回所选动作的元组、这些动作的对数概率以及每个动作的状态值。此外,它还返回策略分布的熵,该熵稍后从损失中减去(带有权重因子 ent_coef)以鼓励探索。
get_losses 函数计算了演员和评论家网络的损失(使用GAE),这些损失随后通过 update_parameters 函数进行更新。
# Author: Till Zemann
# License: MIT License
from __future__ import annotations
import os
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
from torch import optim
from tqdm import tqdm
import gymnasium as gym
优势行动者-评论家 (A2C)¶
Actor-Critic 结合了基于价值和基于策略的方法的元素。在 A2C 中,代理有两个独立的神经网络:一个评论家网络,用于估计状态价值函数,以及一个演员网络,用于输出所有动作的分类概率分布的对数。评论家网络被训练来最小化预测状态值与代理实际接收到的回报之间的均方误差(这相当于最小化平方优势,因为动作的优势是回报与状态价值之间的差:A(s,a) = Q(s,a) - V(s)。演员网络被训练来通过选择根据评论家网络具有高期望值的动作来最大化期望回报。
本教程的重点将不在于A2C本身的细节。相反,教程将重点介绍如何使用矢量化环境和领域随机化来加速A2C(以及其他强化学习算法)的训练过程。
class A2C(nn.Module):
"""
(Synchronous) Advantage Actor-Critic agent class
Args:
n_features: The number of features of the input state.
n_actions: The number of actions the agent can take.
device: The device to run the computations on (running on a GPU might be quicker for larger Neural Nets,
for this code CPU is totally fine).
critic_lr: The learning rate for the critic network (should usually be larger than the actor_lr).
actor_lr: The learning rate for the actor network.
n_envs: The number of environments that run in parallel (on multiple CPUs) to collect experiences.
"""
def __init__(
self,
n_features: int,
n_actions: int,
device: torch.device,
critic_lr: float,
actor_lr: float,
n_envs: int,
) -> None:
"""Initializes the actor and critic networks and their respective optimizers."""
super().__init__()
self.device = device
self.n_envs = n_envs
critic_layers = [
nn.Linear(n_features, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(32, 1), # estimate V(s)
]
actor_layers = [
nn.Linear(n_features, 32),
nn.ReLU(),
nn.Linear(32, 32),
nn.ReLU(),
nn.Linear(
32, n_actions
), # estimate action logits (will be fed into a softmax later)
]
# define actor and critic networks
self.critic = nn.Sequential(*critic_layers).to(self.device)
self.actor = nn.Sequential(*actor_layers).to(self.device)
# define optimizers for actor and critic
self.critic_optim = optim.RMSprop(self.critic.parameters(), lr=critic_lr)
self.actor_optim = optim.RMSprop(self.actor.parameters(), lr=actor_lr)
def forward(self, x: np.ndarray) -> tuple[torch.Tensor, torch.Tensor]:
"""
Forward pass of the networks.
Args:
x: A batched vector of states.
Returns:
state_values: A tensor with the state values, with shape [n_envs,].
action_logits_vec: A tensor with the action logits, with shape [n_envs, n_actions].
"""
x = torch.Tensor(x).to(self.device)
state_values = self.critic(x) # shape: [n_envs,]
action_logits_vec = self.actor(x) # shape: [n_envs, n_actions]
return (state_values, action_logits_vec)
def select_action(
self, x: np.ndarray
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Returns a tuple of the chosen actions and the log-probs of those actions.
Args:
x: A batched vector of states.
Returns:
actions: A tensor with the actions, with shape [n_steps_per_update, n_envs].
action_log_probs: A tensor with the log-probs of the actions, with shape [n_steps_per_update, n_envs].
state_values: A tensor with the state values, with shape [n_steps_per_update, n_envs].
"""
state_values, action_logits = self.forward(x)
action_pd = torch.distributions.Categorical(
logits=action_logits
) # implicitly uses softmax
actions = action_pd.sample()
action_log_probs = action_pd.log_prob(actions)
entropy = action_pd.entropy()
return (actions, action_log_probs, state_values, entropy)
def get_losses(
self,
rewards: torch.Tensor,
action_log_probs: torch.Tensor,
value_preds: torch.Tensor,
entropy: torch.Tensor,
masks: torch.Tensor,
gamma: float,
lam: float,
ent_coef: float,
device: torch.device,
) -> tuple[torch.Tensor, torch.Tensor]:
"""
Computes the loss of a minibatch (transitions collected in one sampling phase) for actor and critic
using Generalized Advantage Estimation (GAE) to compute the advantages (https://arxiv.org/abs/1506.02438).
Args:
rewards: A tensor with the rewards for each time step in the episode, with shape [n_steps_per_update, n_envs].
action_log_probs: A tensor with the log-probs of the actions taken at each time step in the episode, with shape [n_steps_per_update, n_envs].
value_preds: A tensor with the state value predictions for each time step in the episode, with shape [n_steps_per_update, n_envs].
masks: A tensor with the masks for each time step in the episode, with shape [n_steps_per_update, n_envs].
gamma: The discount factor.
lam: The GAE hyperparameter. (lam=1 corresponds to Monte-Carlo sampling with high variance and no bias,
and lam=0 corresponds to normal TD-Learning that has a low variance but is biased
because the estimates are generated by a Neural Net).
device: The device to run the computations on (e.g. CPU or GPU).
Returns:
critic_loss: The critic loss for the minibatch.
actor_loss: The actor loss for the minibatch.
"""
T = len(rewards)
advantages = torch.zeros(T, self.n_envs, device=device)
# compute the advantages using GAE
gae = 0.0
for t in reversed(range(T - 1)):
td_error = (
rewards[t] + gamma * masks[t] * value_preds[t + 1] - value_preds[t]
)
gae = td_error + gamma * lam * masks[t] * gae
advantages[t] = gae
# calculate the loss of the minibatch for actor and critic
critic_loss = advantages.pow(2).mean()
# give a bonus for higher entropy to encourage exploration
actor_loss = (
-(advantages.detach() * action_log_probs).mean() - ent_coef * entropy.mean()
)
return (critic_loss, actor_loss)
def update_parameters(
self, critic_loss: torch.Tensor, actor_loss: torch.Tensor
) -> None:
"""
Updates the parameters of the actor and critic networks.
Args:
critic_loss: The critic loss.
actor_loss: The actor loss.
"""
self.critic_optim.zero_grad()
critic_loss.backward()
self.critic_optim.step()
self.actor_optim.zero_grad()
actor_loss.backward()
self.actor_optim.step()
使用向量化环境¶
当你仅在一个周期内计算两个神经网络的损失时,可能会出现高方差。通过向量化环境,我们可以在并行中使用 n_envs,从而获得线性加速(理论上,我们收集样本的速度可以快 n_envs 倍),这可以用于计算当前策略和批评网络的损失。当我们使用更多样本来计算损失时,方差会降低,从而加快学习速度。
A2C 是一种同步方法,这意味着网络的参数更新是确定性的(在每次采样阶段之后),但我们仍然可以利用异步向量环境来生成多个进程以实现并行环境执行。
创建向量环境的最简单方法是调用 gym.vector.make,它创建同一环境的多个实例:
envs = gym.vector.make("LunarLander-v3", num_envs=3, max_episode_steps=600)
领域随机化¶
如果我们想要为训练随机化环境以获得更健壮的代理(能够处理不同参数化的环境,因此可能具有更高的泛化程度),我们可以手动设置所需的参数或使用伪随机数生成器来生成它们。
手动设置3个具有不同参数的并行’LunarLander-v3’环境:
envs = gym.vector.AsyncVectorEnv(
[
lambda: gym.make(
"LunarLander-v3",
gravity=-10.0,
enable_wind=True,
wind_power=15.0,
turbulence_power=1.5,
max_episode_steps=600,
),
lambda: gym.make(
"LunarLander-v3",
gravity=-9.8,
enable_wind=True,
wind_power=10.0,
turbulence_power=1.3,
max_episode_steps=600,
),
lambda: gym.make(
"LunarLander-v3", gravity=-7.0, enable_wind=False, max_episode_steps=600
),
]
)
随机生成3个并行 ‘LunarLander-v3’ 环境的参数,使用 np.clip 保持在推荐的参数空间内:
envs = gym.vector.AsyncVectorEnv(
[
lambda: gym.make(
"LunarLander-v3",
gravity=np.clip(
np.random.normal(loc=-10.0, scale=1.0), a_min=-11.99, a_max=-0.01
),
enable_wind=np.random.choice([True, False]),
wind_power=np.clip(
np.random.normal(loc=15.0, scale=1.0), a_min=0.01, a_max=19.99
),
turbulence_power=np.clip(
np.random.normal(loc=1.5, scale=0.5), a_min=0.01, a_max=1.99
),
max_episode_steps=600,
)
for i in range(3)
]
)
这里我们使用正态分布,其均值为环境的标准参数化,标准差(尺度)为任意值。根据问题的不同,你可以尝试更高的方差,并使用不同的分布。
如果你在整个训练过程中都在相同的 n_envs 环境中训练,并且 n_envs 是一个相对较小的数字(相对于环境的复杂性),你可能会对所选的特定参数化产生一些过拟合。为了缓解这个问题,你可以选择大量随机参数化的环境,或者每隔几个采样阶段重新创建你的环境,以生成一组新的伪随机参数。
设置¶
# environment hyperparams
n_envs = 10
n_updates = 1000
n_steps_per_update = 128
randomize_domain = False
# agent hyperparams
gamma = 0.999
lam = 0.95 # hyperparameter for GAE
ent_coef = 0.01 # coefficient for the entropy bonus (to encourage exploration)
actor_lr = 0.001
critic_lr = 0.005
# Note: the actor has a slower learning rate so that the value targets become
# more stationary and are theirfore easier to estimate for the critic
# environment setup
if randomize_domain:
envs = gym.vector.AsyncVectorEnv(
[
lambda: gym.make(
"LunarLander-v3",
gravity=np.clip(
np.random.normal(loc=-10.0, scale=1.0), a_min=-11.99, a_max=-0.01
),
enable_wind=np.random.choice([True, False]),
wind_power=np.clip(
np.random.normal(loc=15.0, scale=1.0), a_min=0.01, a_max=19.99
),
turbulence_power=np.clip(
np.random.normal(loc=1.5, scale=0.5), a_min=0.01, a_max=1.99
),
max_episode_steps=600,
)
for i in range(n_envs)
]
)
else:
envs = gym.vector.make("LunarLander-v3", num_envs=n_envs, max_episode_steps=600)
obs_shape = envs.single_observation_space.shape[0]
action_shape = envs.single_action_space.n
# set the device
use_cuda = False
if use_cuda:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
else:
device = torch.device("cpu")
# init the agent
agent = A2C(obs_shape, action_shape, device, critic_lr, actor_lr, n_envs)
训练A2C代理¶
在我们的训练循环中,我们使用 RecordEpisodeStatistics 包装器来记录剧集长度和回报,并且我们还保存损失和熵,以便在代理完成训练后绘制它们。
你可能会注意到,我们不像通常那样在每个回合开始时重置矢量化环境。这是因为每个环境在回合结束时会自动重置(由于随机种子,每个环境完成一个回合所需的时间步数不同)。因此,我们不是在 episodes 中收集数据,而是在每个环境中玩一定数量的步骤(n_steps_per_update)(例如,这可能意味着我们玩20个时间步来完成一个回合,然后使用剩余的时间步开始一个新的回合)。
# create a wrapper environment to save episode returns and episode lengths
envs_wrapper = gym.wrappers.RecordEpisodeStatistics(envs, deque_size=n_envs * n_updates)
critic_losses = []
actor_losses = []
entropies = []
# use tqdm to get a progress bar for training
for sample_phase in tqdm(range(n_updates)):
# we don't have to reset the envs, they just continue playing
# until the episode is over and then reset automatically
# reset lists that collect experiences of an episode (sample phase)
ep_value_preds = torch.zeros(n_steps_per_update, n_envs, device=device)
ep_rewards = torch.zeros(n_steps_per_update, n_envs, device=device)
ep_action_log_probs = torch.zeros(n_steps_per_update, n_envs, device=device)
masks = torch.zeros(n_steps_per_update, n_envs, device=device)
# at the start of training reset all envs to get an initial state
if sample_phase == 0:
states, info = envs_wrapper.reset(seed=42)
# play n steps in our parallel environments to collect data
for step in range(n_steps_per_update):
# select an action A_{t} using S_{t} as input for the agent
actions, action_log_probs, state_value_preds, entropy = agent.select_action(
states
)
# perform the action A_{t} in the environment to get S_{t+1} and R_{t+1}
states, rewards, terminated, truncated, infos = envs_wrapper.step(
actions.cpu().numpy()
)
ep_value_preds[step] = torch.squeeze(state_value_preds)
ep_rewards[step] = torch.tensor(rewards, device=device)
ep_action_log_probs[step] = action_log_probs
# add a mask (for the return calculation later);
# for each env the mask is 1 if the episode is ongoing and 0 if it is terminated (not by truncation!)
masks[step] = torch.tensor([not term for term in terminated])
# calculate the losses for actor and critic
critic_loss, actor_loss = agent.get_losses(
ep_rewards,
ep_action_log_probs,
ep_value_preds,
entropy,
masks,
gamma,
lam,
ent_coef,
device,
)
# update the actor and critic networks
agent.update_parameters(critic_loss, actor_loss)
# log the losses and entropy
critic_losses.append(critic_loss.detach().cpu().numpy())
actor_losses.append(actor_loss.detach().cpu().numpy())
entropies.append(entropy.detach().mean().cpu().numpy())
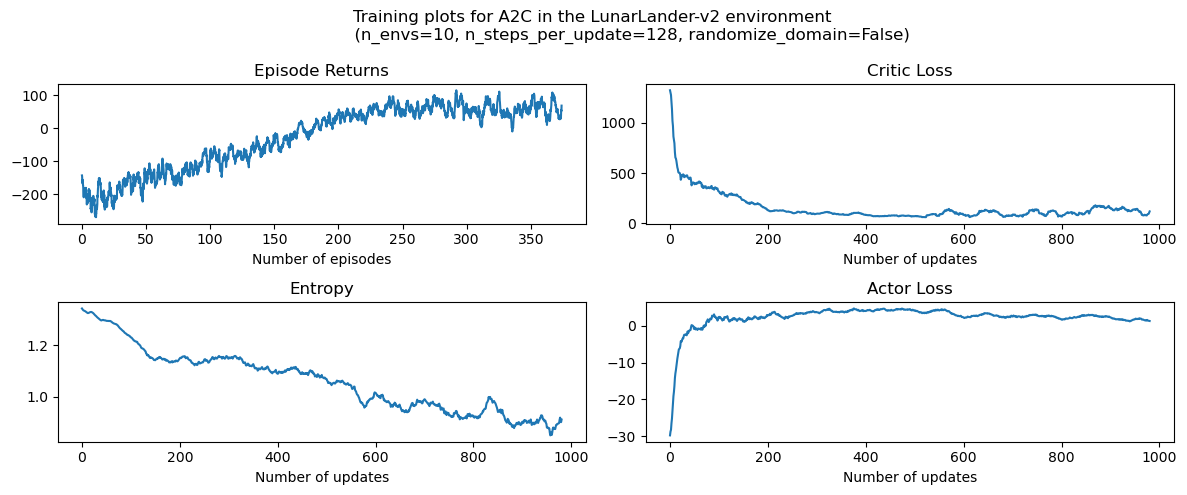
绘图¶
""" plot the results """
# %matplotlib inline
rolling_length = 20
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 5))
fig.suptitle(
f"Training plots for {agent.__class__.__name__} in the LunarLander-v3 environment \n \
(n_envs={n_envs}, n_steps_per_update={n_steps_per_update}, randomize_domain={randomize_domain})"
)
# episode return
axs[0][0].set_title("Episode Returns")
episode_returns_moving_average = (
np.convolve(
np.array(envs_wrapper.return_queue).flatten(),
np.ones(rolling_length),
mode="valid",
)
/ rolling_length
)
axs[0][0].plot(
np.arange(len(episode_returns_moving_average)) / n_envs,
episode_returns_moving_average,
)
axs[0][0].set_xlabel("Number of episodes")
# entropy
axs[1][0].set_title("Entropy")
entropy_moving_average = (
np.convolve(np.array(entropies), np.ones(rolling_length), mode="valid")
/ rolling_length
)
axs[1][0].plot(entropy_moving_average)
axs[1][0].set_xlabel("Number of updates")
# critic loss
axs[0][1].set_title("Critic Loss")
critic_losses_moving_average = (
np.convolve(
np.array(critic_losses).flatten(), np.ones(rolling_length), mode="valid"
)
/ rolling_length
)
axs[0][1].plot(critic_losses_moving_average)
axs[0][1].set_xlabel("Number of updates")
# actor loss
axs[1][1].set_title("Actor Loss")
actor_losses_moving_average = (
np.convolve(np.array(actor_losses).flatten(), np.ones(rolling_length), mode="valid")
/ rolling_length
)
axs[1][1].plot(actor_losses_moving_average)
axs[1][1].set_xlabel("Number of updates")
plt.tight_layout()
plt.show()
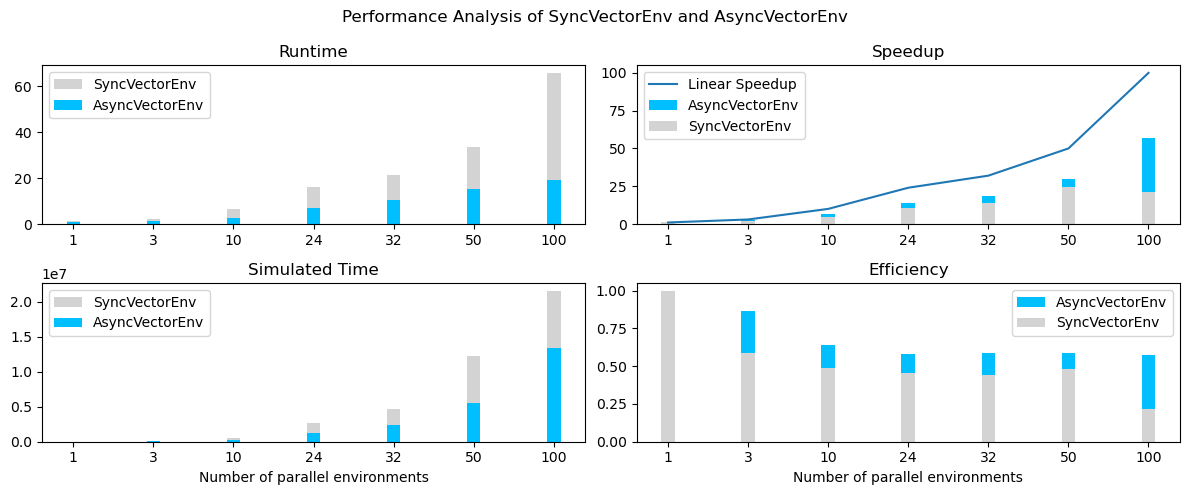
同步和异步向量化环境的性能分析¶
异步环境可以导致更快的训练时间和比同步环境更高的数据收集加速。这是因为异步环境允许多个代理与其环境并行交互,而同步环境则串行运行多个环境。这导致异步环境具有更高的效率和更快的训练时间。
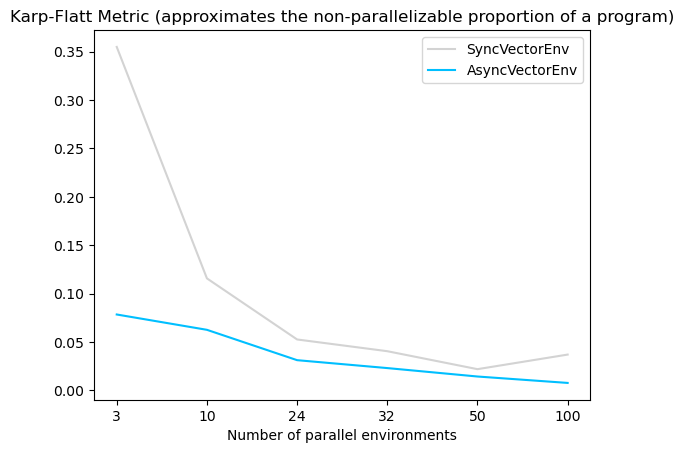
根据Karp-Flatt指标(一个用于并行计算的指标,用于估计在增加并行进程数量时的加速极限,这里指的是环境数量),异步环境的估计最大加速为57,而同步环境的估计最大加速为21。这表明异步环境的训练时间显著快于同步环境(见图表)。
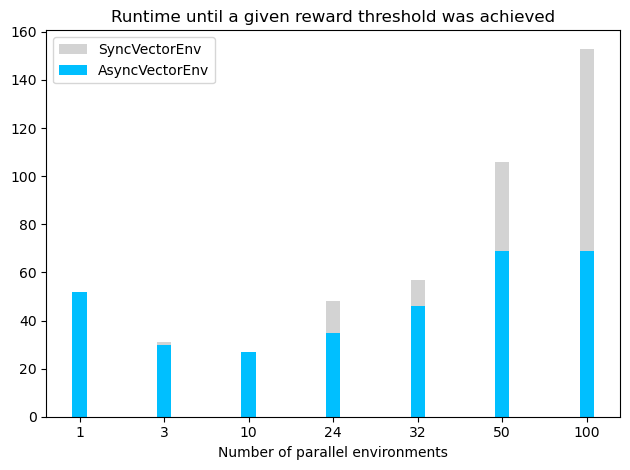
然而,值得注意的是,增加并行向量环境的数量在超过一定数量的环境后会导致训练时间变慢(见下图,其中代理训练直到平均训练回报超过 -120)。训练时间变慢可能是因为在相对较少的环境数量后,环境的梯度已经足够好(特别是如果环境不是很复杂)。在这种情况下,增加环境数量并不会提高学习速度,反而会增加运行时间,可能是因为计算梯度所需的时间增加。对于 LunarLander-v3,表现最佳的配置使用了带有 10 个并行环境的 AsyncVectorEnv,但更复杂的环境可能需要更多的并行环境以达到最佳性能。
保存/加载权重¶
save_weights = False
load_weights = False
actor_weights_path = "weights/actor_weights.h5"
critic_weights_path = "weights/critic_weights.h5"
if not os.path.exists("weights"):
os.mkdir("weights")
""" save network weights """
if save_weights:
torch.save(agent.actor.state_dict(), actor_weights_path)
torch.save(agent.critic.state_dict(), critic_weights_path)
""" load network weights """
if load_weights:
agent = A2C(obs_shape, action_shape, device, critic_lr, actor_lr)
agent.actor.load_state_dict(torch.load(actor_weights_path))
agent.critic.load_state_dict(torch.load(critic_weights_path))
agent.actor.eval()
agent.critic.eval()
展示代理¶
""" play a couple of showcase episodes """
n_showcase_episodes = 3
for episode in range(n_showcase_episodes):
print(f"starting episode {episode}...")
# create a new sample environment to get new random parameters
if randomize_domain:
env = gym.make(
"LunarLander-v3",
render_mode="human",
gravity=np.clip(
np.random.normal(loc=-10.0, scale=2.0), a_min=-11.99, a_max=-0.01
),
enable_wind=np.random.choice([True, False]),
wind_power=np.clip(
np.random.normal(loc=15.0, scale=2.0), a_min=0.01, a_max=19.99
),
turbulence_power=np.clip(
np.random.normal(loc=1.5, scale=1.0), a_min=0.01, a_max=1.99
),
max_episode_steps=500,
)
else:
env = gym.make("LunarLander-v3", render_mode="human", max_episode_steps=500)
# get an initial state
state, info = env.reset()
# play one episode
done = False
while not done:
# select an action A_{t} using S_{t} as input for the agent
with torch.no_grad():
action, _, _, _ = agent.select_action(state[None, :])
# perform the action A_{t} in the environment to get S_{t+1} and R_{t+1}
state, reward, terminated, truncated, info = env.step(action.item())
# update if the environment is done
done = terminated or truncated
env.close()
尝试自己玩这个环境¶
# from gymnasium.utils.play import play
#
# play(gym.make('LunarLander-v3', render_mode='rgb_array'),
# keys_to_action={'w': 2, 'a': 1, 'd': 3}, noop=0)
参考文献¶
[1] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, K. Kavukcuoglu. “深度强化学习的异步方法” ICML (2016).
[2] J. Schulman, P. Moritz, S. Levine, M. Jordan 和 P. Abbeel. “使用广义优势估计进行高维连续控制。” ICLR (2016).
[3] Gymnasium 文档: 向量环境。(URL: https://gymnasium.farama.org/api/vector/)