LiLT
概述
LiLT模型由Jiapeng Wang、Lianwen Jin和Kai Ding在LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding中提出。 LiLT允许将任何预训练的RoBERTa文本编码器与轻量级的布局变换器结合,以实现LayoutLM式的多语言文档理解。
论文的摘要如下:
结构化文档理解因其在智能文档处理中的关键作用,近年来引起了广泛关注并取得了显著进展。然而,大多数现有的相关模型只能处理预训练集合中包含的特定语言(通常是英语)的文档数据,这极为有限。为了解决这个问题,我们提出了一种简单而有效的语言无关布局变换器(LiLT),用于结构化文档理解。LiLT可以在单一语言的结构化文档上进行预训练,然后直接在其他语言上使用相应的现成单语/多语预训练文本模型进行微调。在八种语言上的实验结果表明,LiLT在各种广泛使用的下游基准测试中可以实现竞争甚至优越的性能,这使得语言无关的文档布局结构预训练成为可能。
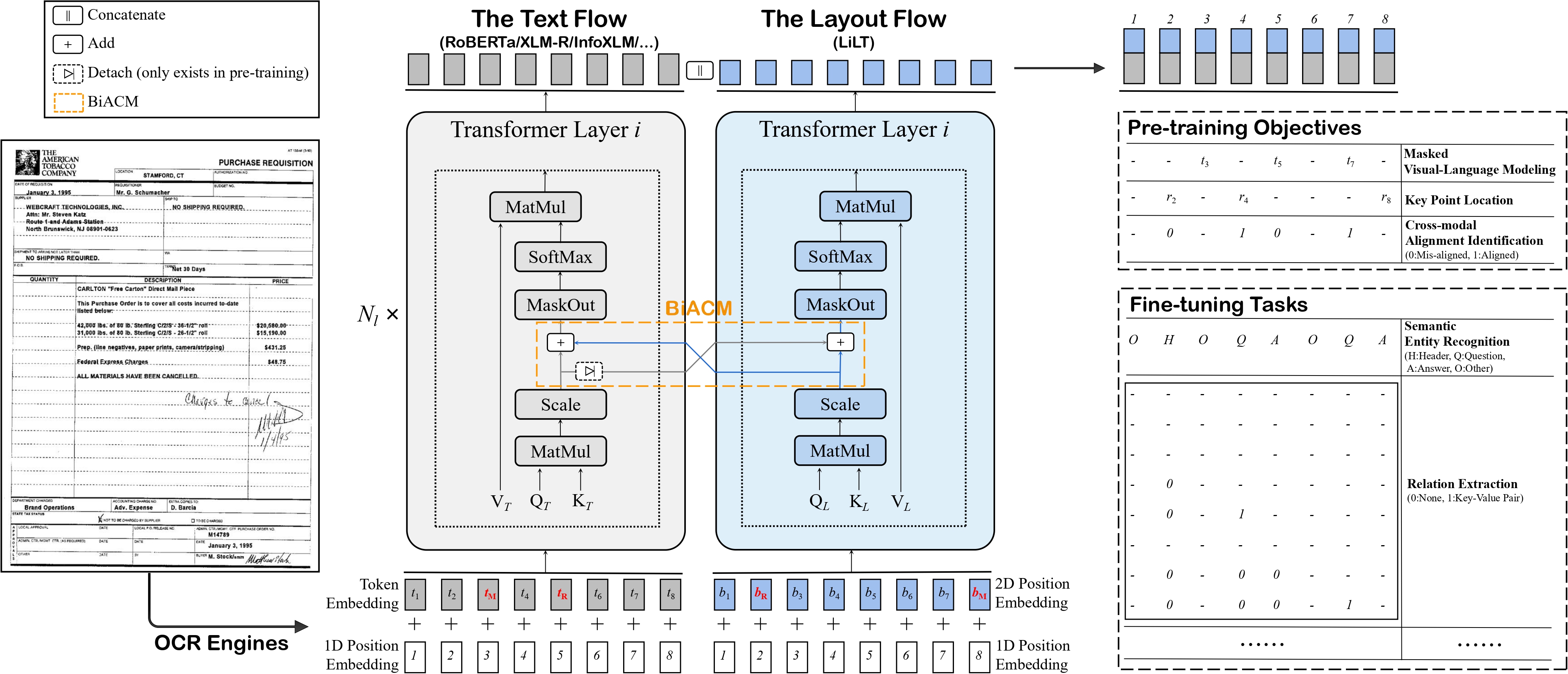 LiLT architecture. Taken from the original paper.
LiLT architecture. Taken from the original paper. 使用提示
- 要将语言独立布局转换器与来自hub的新RoBERTa检查点结合使用,请参考this guide。
该脚本将导致
config.json和pytorch_model.bin文件存储在本地。完成此操作后,可以执行以下操作(假设您已使用HuggingFace帐户登录):
from transformers import LiltModel
model = LiltModel.from_pretrained("path_to_your_files")
model.push_to_hub("name_of_repo_on_the_hub")- 在为模型准备数据时,确保使用与您与Layout Transformer结合的RoBERTa检查点相对应的词汇表。
- 由于lilt-roberta-en-base使用与LayoutLMv3相同的词汇表,因此可以使用LayoutLMv3TokenizerFast为模型准备数据。 对于lilt-roberta-en-base也是如此:可以使用LayoutXLMTokenizerFast为该模型准备数据。
资源
一份官方的Hugging Face和社区(由🌎表示)资源列表,帮助您开始使用LiLT。
- LiLT 的演示笔记本可以在 这里 找到。
文档资源
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
LiltConfig
类 transformers.LiltConfig
< source >( 词汇大小 = 30522 隐藏大小 = 768 隐藏层数 = 12 注意力头数 = 12 中间大小 = 3072 隐藏激活函数 = 'gelu' 隐藏层丢弃概率 = 0.1 注意力概率丢弃概率 = 0.1 最大位置嵌入 = 512 类型词汇大小 = 2 初始化范围 = 0.02 层归一化epsilon = 1e-12 填充标记ID = 0 位置嵌入类型 = 'absolute' 分类器丢弃 = None 通道收缩比率 = 4 最大2D位置嵌入 = 1024 **kwargs )
参数
- vocab_size (
int, optional, defaults to 30522) — LiLT模型的词汇表大小。定义了调用LiltModel时传递的inputs_ids可以表示的不同标记的数量。 - hidden_size (
int, optional, defaults to 768) — 编码器层和池化层的维度。应为24的倍数。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, defaults to 12) — Transformer编码器中每个注意力层的注意力头数量。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 - hidden_act (
str或Callable, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 - hidden_dropout_prob (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, 默认为 0.1) — 注意力概率的丢弃比例。 - max_position_embeddings (
int, optional, 默认为 512) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - type_vocab_size (
int, 可选, 默认为 2) — 调用 LiltModel 时传递的token_type_ids的词汇大小. - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - position_embedding_type (
str, 可选, 默认为"absolute") — 位置嵌入的类型。选择"absolute","relative_key","relative_key_query"中的一个。对于 位置嵌入,使用"absolute"。有关"relative_key"的更多信息,请参阅 Self-Attention with Relative Position Representations (Shaw et al.)。 有关"relative_key_query"的更多信息,请参阅 方法 4 在 Improve Transformer Models with Better Relative Position Embeddings (Huang et al.) 中。 - classifier_dropout (
float, optional) — 分类头的丢弃比率。 - channel_shrink_ratio (
int, optional, 默认为 4) — 与hidden_size相比的缩小比例,用于布局嵌入的通道维度。 - max_2d_position_embeddings (
int, 可选, 默认为 1024) — 2D位置嵌入可能使用的最大值。通常将其设置为较大的值以防万一(例如,1024)。
这是用于存储LiltModel配置的配置类。它用于根据指定的参数实例化一个LiLT模型,定义模型架构。使用默认值实例化配置将产生与LiLT SCUT-DLVCLab/lilt-roberta-en-base架构相似的配置。配置对象继承自PretrainedConfig,可用于控制模型输出。更多信息请阅读PretrainedConfig的文档。
示例:
>>> from transformers import LiltConfig, LiltModel
>>> # Initializing a LiLT SCUT-DLVCLab/lilt-roberta-en-base style configuration
>>> configuration = LiltConfig()
>>> # Randomly initializing a model from the SCUT-DLVCLab/lilt-roberta-en-base style configuration
>>> model = LiltModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configLiltModel
类 transformers.LiltModel
< source >( config add_pooling_layer = True )
参数
- config (LiltConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的LiLT模型转换器输出原始隐藏状态,没有任何特定的头部。 此模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None bbox: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- bbox (
torch.LongTensor形状为(batch_size, sequence_length, 4), 可选) — 每个输入序列标记的边界框。选择范围在[0, config.max_2d_position_embeddings-1]。每个边界框应为 (x0, y0, x1, y1) 格式的归一化版本,其中 (x0, y0) 对应于边界框左上角的位置,(x1, y1) 表示右下角的位置。有关归一化的详细信息,请参见 概述. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(LiltConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size)) — 序列的第一个标记(分类标记)在经过用于辅助预训练任务的层进一步处理后的最后一层隐藏状态。例如,对于BERT系列模型,这返回经过线性层和tanh激活函数处理后的分类标记。线性层的权重是在预训练期间通过下一个句子预测(分类)目标训练的。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力softmax后的注意力权重,用于计算自注意力头中的加权平均值。
LiltModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModel
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModel.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_stateLiltForSequenceClassification
类 transformers.LiltForSequenceClassification
< source >( config )
参数
- config (LiltConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
LiLT模型转换器,顶部带有序列分类/回归头(在池化输出之上的线性层),例如用于GLUE任务。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None bbox: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- bbox (
torch.LongTensor形状为(batch_size, sequence_length, 4), 可选) — 每个输入序列标记的边界框。选择范围在[0, config.max_2d_position_embeddings-1]。每个边界框应为 (x0, y0, x1, y1) 格式的归一化版本,其中 (x0, y0) 对应于边界框左上角的位置,(x1, y1) 表示右下角的位置。有关归一化的详细信息,请参见 概述. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或者一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或者当 config.return_dict=False 时),包含各种
元素,取决于配置(LiltConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类(或者回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或者回归,如果 config.num_labels==1)分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或者当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或者当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LiltForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForSequenceClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> predicted_class_idx = outputs.logits.argmax(-1).item()
>>> predicted_class = model.config.id2label[predicted_class_idx]LiltForTokenClassification
类 transformers.LiltForTokenClassification
< source >( config )
参数
- config (LiltConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Lilt 模型,顶部带有标记分类头(隐藏状态输出顶部的线性层),例如用于命名实体识别(NER)任务。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None bbox: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- bbox (
torch.LongTensor形状为(batch_size, sequence_length, 4), 可选) — 每个输入序列标记的边界框。选择范围在[0, config.max_2d_position_embeddings-1]。每个边界框应为 (x0, y0, x1, y1) 格式的归一化版本,其中 (x0, y0) 对应于边界框左上角的位置,(x1, y1) 表示右下角的位置。有关归一化的详细信息,请参见 概述. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算令牌分类损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。
返回
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(LiltConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.num_labels)) — 分类分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LiltForTokenClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModelForTokenClassification
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForTokenClassification.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> predicted_class_indices = outputs.logits.argmax(-1)LiltForQuestionAnswering
类 transformers.LiltForQuestionAnswering
< source >( config )
参数
- config (LiltConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Lilt 模型顶部带有跨度分类头,用于抽取式问答任务,如 SQuAD(在隐藏状态输出顶部使用线性层来计算 span start logits 和 span end logits)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None bbox: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- bbox (
torch.LongTensor形状为(batch_size, sequence_length, 4), 可选) — 每个输入序列标记的边界框。选择范围在[0, config.max_2d_position_embeddings-1]。每个边界框应为 (x0, y0, x1, y1) 格式的归一化版本,其中 (x0, y0) 对应于边界框左上角的位置,(x1, y1) 表示右下角的位置。有关归一化的详细信息,请参见 概述. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制权,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - start_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度起始位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会被考虑用于计算损失。 - end_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度结束位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置在计算损失时不被考虑。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(LiltConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 总跨度提取损失是起始和结束位置的交叉熵之和。 -
start_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度起始分数(在 SoftMax 之前)。 -
end_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度结束分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
LiltForQuestionAnswering 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, AutoModelForQuestionAnswering
>>> from datasets import load_dataset
>>> tokenizer = AutoTokenizer.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> model = AutoModelForQuestionAnswering.from_pretrained("SCUT-DLVCLab/lilt-roberta-en-base")
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = tokenizer(words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
>>> predicted_answer = tokenizer.decode(predict_answer_tokens)