桥塔
概述
BridgeTower模型由Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan在BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning中提出。该模型的目标是在每个单模态编码器和跨模态编码器之间建立桥梁,以在跨模态编码器的每一层实现全面和详细的交互,从而在各种下游任务上实现显著的性能提升,同时几乎不增加额外的性能和计算成本。
本文已被AAAI’23会议接受。
论文的摘要如下:
近年来,采用双塔架构的视觉-语言(VL)模型在视觉-语言表示学习领域占据了主导地位。 当前的VL模型要么使用轻量级的单模态编码器,并在深度跨模态编码器中同时学习提取、对齐和融合两种模态,要么将深度预训练的单模态编码器的最后一层单模态表示输入到顶层的跨模态编码器中。 这两种方法都可能限制视觉-语言表示学习并影响模型性能。在本文中,我们提出了BRIDGETOWER,它引入了多个桥接层,这些桥接层在单模态编码器的顶层和跨模态编码器的每一层之间建立了连接。 这使得在跨模态编码器中能够有效地进行自下而上的跨模态对齐和融合,从而在不同语义层次的预训练单模态编码器的视觉和文本表示之间建立联系。仅使用4M图像进行预训练,BRIDGETOWER在各种下游视觉-语言任务中实现了最先进的性能。 特别是在VQAv2测试集上,BRIDGETOWER的准确率达到78.73%,比之前的最先进模型METER高出1.09%,且使用相同的预训练数据和几乎可以忽略不计的额外参数和计算成本。 值得注意的是,当进一步扩展模型时,BRIDGETOWER的准确率达到81.15%,超过了在更大规模数据集上预训练的模型。
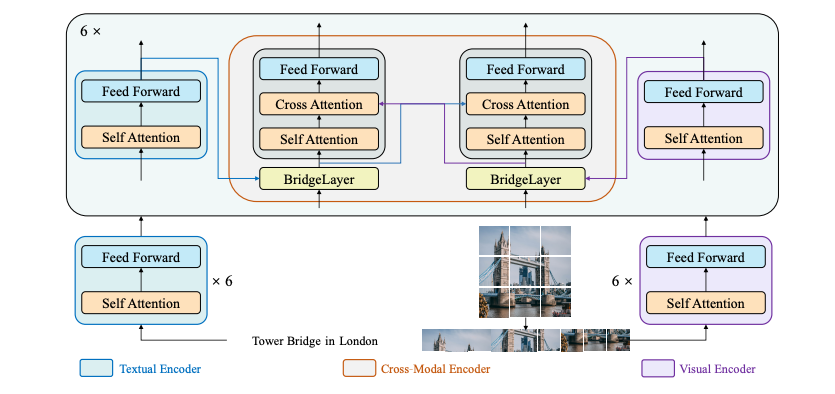 BridgeTower architecture. Taken from the original paper.
BridgeTower architecture. Taken from the original paper. 该模型由Anahita Bhiwandiwalla、Tiep Le和Shaoyen Tseng贡献。原始代码可以在这里找到。
使用技巧和示例
BridgeTower 由一个视觉编码器、一个文本编码器和多个轻量级桥接层的跨模态编码器组成。 该方法的目标是在每个单模态编码器和跨模态编码器之间建立桥梁,以在跨模态编码器的每一层实现全面和详细的交互。 原则上,可以在所提出的架构中应用任何视觉、文本或跨模态编码器。
BridgeTowerProcessor 将 RobertaTokenizer 和 BridgeTowerImageProcessor 包装成一个实例,分别用于编码文本和准备图像。
以下示例展示了如何使用BridgeTowerProcessor和BridgeTowerForContrastiveLearning运行对比学习。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs以下示例展示了如何使用BridgeTowerProcessor和BridgeTowerForImageAndTextRetrieval运行图像-文本检索。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()以下示例展示了如何使用BridgeTowerProcessor和BridgeTowerForMaskedLM运行掩码语言建模。
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.提示:
- BridgeTower 的实现使用 RobertaTokenizer 生成文本嵌入,并使用 OpenAI 的 CLIP/ViT 模型计算视觉嵌入。
- 预训练的bridgeTower-base和bridgetower masked language modeling and image text matching的检查点已发布。
- 请参考表5了解BridgeTower在图像检索和其他下游任务上的表现。
- 此模型的PyTorch版本仅在torch 1.10及更高版本中可用。
BridgeTowerConfig
类 transformers.BridgeTowerConfig
< source >( share_cross_modal_transformer_layers = True hidden_act = 'gelu' hidden_size = 768 initializer_factor = 1 layer_norm_eps = 1e-05 share_link_tower_layers = False link_tower_type = 'add' num_attention_heads = 12 num_hidden_layers = 6 tie_word_embeddings = False init_layernorm_from_vision_encoder = False text_config = None vision_config = None **kwargs )
参数
- share_cross_modal_transformer_layers (
bool, optional, defaults toTrue) — 是否共享跨模态变换器层。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - initializer_factor (
float, 可选, 默认为 1) — 用于初始化所有权重矩阵的因子(应保持为1,内部用于初始化测试)。 - layer_norm_eps (
float, optional, defaults to 1e-05) — 层归一化层使用的epsilon值。 - share_link_tower_layers (
bool, 可选, 默认为False) — 是否共享桥接/链接塔层。 - link_tower_type (
str, 可选, 默认为"add") — 桥梁/链接层的类型。 - num_attention_heads (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - num_hidden_layers (
int, optional, defaults to 6) — Transformer编码器中的隐藏层数量。 - tie_word_embeddings (
bool, optional, defaults toFalse) — 是否绑定输入和输出嵌入. - init_layernorm_from_vision_encoder (
bool, optional, defaults toFalse) — 是否从视觉编码器初始化LayerNorm. - text_config (
dict, 可选) — 用于初始化 BridgeTowerTextConfig 的配置选项字典. - vision_config (
dict, optional) — 用于初始化BridgeTowerVisionConfig的配置选项字典。
这是用于存储BridgeTowerModel配置的配置类。它用于根据指定的参数实例化一个BridgeTower模型,定义模型架构。使用默认值实例化配置将产生与BridgeTower/bridgetower-base架构相似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import BridgeTowerModel, BridgeTowerConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration
>>> configuration = BridgeTowerConfig()
>>> # Initializing a model from the BridgeTower/bridgetower-base style configuration
>>> model = BridgeTowerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configfrom_text_vision_configs
< source >( text_config: BridgeTowerTextConfig vision_config: BridgeTowerVisionConfig **kwargs )
从BridgeTower文本模型配置实例化一个BridgeTowerConfig(或派生类)。返回: BridgeTowerConfig: 配置对象的实例
BridgeTowerTextConfig
类 transformers.BridgeTowerTextConfig
< source >( vocab_size = 50265 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 initializer_factor = 1 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 514 type_vocab_size = 1 layer_norm_eps = 1e-05 pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 position_embedding_type = 'absolute' use_cache = True **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50265) — 模型的文本部分的词汇量。定义了调用 BridgeTowerModel 时传递的inputs_ids可以表示的不同标记的数量。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, defaults to 12) — Transformer编码器中的隐藏层数量。 - num_attention_heads (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(通常称为前馈)层的维度。 - hidden_act (
str或Callable, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 - hidden_dropout_prob (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — 注意力概率的丢弃比例。 - max_position_embeddings (
int, optional, 默认为 514) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - type_vocab_size (
int, optional, 默认为 2) —token_type_ids的词汇大小. - initializer_factor (
float, 可选, 默认为 1) — 用于初始化所有权重矩阵的因子(应保持为1,内部用于初始化测试)。 - layer_norm_eps (
float, optional, defaults to 1e-05) — 层归一化层使用的epsilon值。 - position_embedding_type (
str, optional, 默认为"absolute") — 位置嵌入的类型。选择"absolute","relative_key","relative_key_query"中的一个。对于 位置嵌入,使用"absolute"。有关"relative_key"的更多信息,请参阅 Self-Attention with Relative Position Representations (Shaw et al.)。 有关"relative_key_query"的更多信息,请参阅 Improve Transformer Models with Better Relative Position Embeddings (Huang et al.) 中的 Method 4。 - is_decoder (
bool, 可选, 默认为False) — 模型是否用作解码器。如果为False,则模型用作编码器。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。仅在config.is_decoder=True时相关。
这是用于存储BridgeTowerModel文本配置的配置类。这里的默认值是从RoBERTa复制的。使用默认值实例化配置将产生与BridegTower/bridgetower-base架构相似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
BridgeTowerVisionConfig
类 transformers.BridgeTowerVisionConfig
< source >( hidden_size = 768 num_hidden_layers = 12 num_channels = 3 patch_size = 16 image_size = 288 initializer_factor = 1 layer_norm_eps = 1e-05 stop_gradient = False share_layernorm = True remove_last_layer = False **kwargs )
参数
- hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — 视觉编码器模型中的隐藏层数量。 - patch_size (
int, optional, defaults to 16) — 每个补丁的大小(分辨率)。 - image_size (
int, optional, defaults to 288) — 每张图像的大小(分辨率)。 - initializer_factor (
float, 可选, 默认为 1) — 用于初始化所有权重矩阵的因子(应保持为1,内部用于初始化测试)。 - layer_norm_eps (
float, optional, defaults to 1e-05) — 层归一化层使用的epsilon值。 - stop_gradient (
bool, optional, defaults toFalse) — 是否停止梯度用于训练. - share_layernorm (
bool, 可选, 默认为True) — LayerNorm层是否共享. - remove_last_layer (
bool, 可选, 默认为False) — 是否从视觉编码器中移除最后一层。
这是用于存储BridgeTowerModel视觉配置的配置类。使用默认值实例化配置将产生与bridgetower-base BridgeTower/bridgetower-base架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
BridgeTowerImageProcessor
类 transformers.BridgeTowerImageProcessor
< source >( do_resize: bool = True size: typing.Dict[str, int] = None size_divisor: int = 32 resample: Resampling =
参数
- do_resize (
bool, 可选, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中通过do_resize参数覆盖此设置。 - size (
Dict[str, int]可选, 默认为{'shortest_edge' -- 288}): 将输入的较短边调整为size["shortest_edge"]。较长边将被限制在int((1333 / 800) * size["shortest_edge"])以下,同时保持宽高比。仅在do_resize设置为True时有效。可以通过preprocess方法中的size参数进行覆盖。 - size_divisor (
int, 可选, 默认为 32) — 确保高度和宽度都可以被整除的大小。仅在do_resize设置为True时有效。可以在preprocess方法中通过size_divisor参数覆盖。 - resample (
PILImageResampling, 可选, 默认为Resampling.BICUBIC) — 如果调整图像大小,则使用的重采样过滤器。仅在do_resize设置为True时有效。可以通过preprocess方法中的resample参数进行覆盖。 - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess方法中通过do_rescale参数覆盖此设置。 - rescale_factor (
int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。仅在do_rescale设置为True时有效。可以被preprocess方法中的rescale_factor参数覆盖。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。可以在preprocess方法中通过do_normalize参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以在preprocess方法中通过image_mean参数覆盖。可以在preprocess方法中通过image_mean参数覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以在preprocess方法中通过image_std参数进行覆盖。 可以在preprocess方法中通过image_std参数进行覆盖。 - do_center_crop (
bool, 可选, 默认为True) — 是否对图像进行中心裁剪。可以在preprocess方法中通过do_center_crop参数进行覆盖。 - crop_size (
Dict[str, int], 可选) — 在应用中心裁剪时所需的输出大小。仅在do_center_crop设置为True时有效。 可以通过preprocess方法中的crop_size参数进行覆盖。如果未设置,则默认为size, - do_pad (
bool, 可选, 默认为True) — 是否将图像填充到批次中图像的(max_height, max_width)。可以通过preprocess方法中的do_pad参数进行覆盖。
构建一个BridgeTower图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_resize: typing.Optional[bool] = None size: typing.Optional[typing.Dict[str, int]] = None size_divisor: typing.Optional[int] = None resample: Resampling = None do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_pad: typing.Optional[bool] = None do_center_crop: typing.Optional[bool] = None crop_size: typing.Dict[str, int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围在0到255之间。如果传入的图像像素值在0到1之间,请设置do_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], 可选, 默认为self.size) — 控制调整大小后图像的尺寸。图像的最短边将调整为size["shortest_edge"],同时保持宽高比。如果调整大小后的图像的最长边 大于int(size["shortest_edge"] * (1333 / 800)),则图像将再次调整大小以使最长边 等于int(size["shortest_edge"] * (1333 / 800)). - size_divisor (
int, optional, defaults toself.size_divisor) — 图像被调整为这个值的倍数大小。 - resample (
PILImageResampling, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。仅在do_resize设置为True时有效。 - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到[0 - 1]之间。 - rescale_factor (
float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_normalize (
bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化处理. - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 如果do_normalize设置为True,则用于归一化图像的图像均值。 - image_std (
float或List[float], 可选, 默认为self.image_std) — 如果do_normalize设置为True,则用于归一化图像的标准差。 - do_pad (
bool, 可选, 默认为self.do_pad) — 是否将图像填充到批次中的 (max_height, max_width)。如果为True,还会创建并返回一个像素掩码。 - do_center_crop (
bool, 可选, 默认为self.do_center_crop) — 是否对图像进行中心裁剪。如果输入图像的尺寸在任何一边小于crop_size,图像将用0填充,然后进行中心裁剪。 - crop_size (
Dict[str, int], 可选, 默认为self.crop_size) — 图像中心裁剪后的大小。如果图像的某一边小于crop_size,它将被填充零然后裁剪 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
BridgeTowerProcessor
类 transformers.BridgeTowerProcessor
< source >( image_processor tokenizer )
参数
- image_processor (
BridgeTowerImageProcessor) — 一个 BridgeTowerImageProcessor 的实例。图像处理器是一个必需的输入。 - tokenizer (
RobertaTokenizerFast) — [‘RobertaTokenizerFast`] 的一个实例。tokenizer 是一个必需的输入。
构建一个BridgeTower处理器,它将Roberta分词器和BridgeTower图像处理器封装到一个单一的处理器中。
BridgeTowerProcessor 提供了 BridgeTowerImageProcessor 和
RobertaTokenizerFast 的所有功能。有关更多信息,请参阅 call() 和
decode() 的文档字符串。
__call__
< source >( images text: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] = None audio = None videos = None **kwargs: typing_extensions.Unpack[transformers.models.bridgetower.processing_bridgetower.BridgeTowerProcessorKwargs] )
此方法使用BridgeTowerImageProcessor.call()方法来为模型准备图像,并使用RobertaTokenizerFast.call()来为模型准备文本。
请参考上述两个方法的文档字符串以获取更多信息。
BridgeTowerModel
类 transformers.BridgeTowerModel
< source >( config )
参数
- config (BridgeTowerConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的BridgeTower模型转换器输出BridgeTowerModelOutput对象,顶部没有任何特定的头部。
这个模型是一个PyTorch torch.nn.Module _ 子类。使用
它作为常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None image_token_type_idx: typing.Optional[int] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None interpolate_pos_encoding: bool = False ) → transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape({0})) — 词汇表中输入序列标记的索引。可以使用AutoTokenizer获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入ID? - attention_mask (
torch.FloatTensorof shape({0}), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。 什么是注意力掩码?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — 用于指示输入的第一部分和第二部分的段标记索引。索引在[0, 1]中选择:- 0 对应于 句子 A 的标记,
- 1 对应于 句子 B 的标记。 什么是标记类型 ID?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 BridgeTowerImageProcessor 获取。详情请参见 BridgeTowerImageProcessor.call(). - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — 用于避免对填充像素值执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示真实的像素(即 未掩码),
- 0 表示填充的像素(即 掩码)。
什么是注意力掩码? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - image_embeds (
torch.FloatTensor形状为(batch_size, num_patches, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递pixel_values。 如果您希望对如何将pixel_values转换为补丁嵌入有更多控制,这将非常有用。 - image_token_type_idx (
int, optional) —- 图像的令牌类型ID。
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, 默认为False) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - output_hidden_states (
bool, 可选) — 如果设置为True,隐藏状态将作为包含文本、图像和跨模态组件的隐藏状态的列表返回。即(hidden_states_text, hidden_states_image, hidden_states_cross_modal),其中每个元素是对应模态的隐藏状态列表。hidden_states_txt/img是对应单模态隐藏状态的张量列表,而hidden_states_cross_modal是包含每个桥接层的cross_modal_text_hidden_states和cross_modal_image_hidden_states的元组列表。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 目前不支持标签。
返回
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BridgeTowerConfig)和输入。
-
text_features (
torch.FloatTensor形状为(batch_size, text_sequence_length, hidden_size)) — 模型最后一层的文本输出的隐藏状态序列。 -
image_features (
torch.FloatTensor形状为(batch_size, image_sequence_length, hidden_size)) — 模型最后一层的图像输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size x 2)) — 文本和图像序列的第一个标记(分类标记)的最后一层隐藏状态的连接,分别经过用于辅助预训练任务的层进一步处理。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。 -
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
BridgeTowerModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])BridgeTowerForContrastiveLearning
类 transformers.BridgeTowerForContrastiveLearning
< source >( config )
参数
- config (BridgeTowerConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
BridgeTower 模型,顶部带有图像-文本对比头,用于计算图像-文本对比损失。
该模型是一个PyTorch torch.nn.Module _ 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = True return_dict: typing.Optional[bool] = None return_loss: typing.Optional[bool] = None ) → transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape({0})) — 词汇表中输入序列标记的索引。可以使用AutoTokenizer获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入ID? - attention_mask (
torch.FloatTensorof shape({0}), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。 什么是注意力掩码?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — 用于指示输入的第一部分和第二部分的段标记索引。索引在[0, 1]中选择:- 0 对应于 句子 A 的标记,
- 1 对应于 句子 B 的标记。 什么是标记类型 ID?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 BridgeTowerImageProcessor 获取。详情请参见 BridgeTowerImageProcessor.call(). - pixel_mask (
torch.LongTensor形状为(batch_size, height, width), 可选) — 用于避免对填充像素值执行注意力操作的掩码。掩码值在[0, 1]中选择:- 1 表示真实的像素(即 未掩码),
- 0 表示填充的像素(即 掩码)。
什么是注意力掩码? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - image_embeds (
torch.FloatTensor形状为(batch_size, num_patches, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递pixel_values。 如果您希望对如何将pixel_values转换为补丁嵌入有更多控制,这将非常有用。 - image_token_type_idx (
int, optional) —- 图像的token类型id。
- output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, 默认为False) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - return_loss (
bool, optional) — 是否返回对比损失。
返回
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BridgeTowerConfig)和输入。
- loss (
torch.FloatTensor形状为(1,), 可选, 当return_loss为True时返回) — 图像-文本对比损失。 - logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 - text_embeds (
torch.FloatTensor), 可选, 当模型初始化时使用with_projection=True时返回) — 通过将投影层应用于 pooler_output 获得的文本嵌入。 - image_embeds (
torch.FloatTensor), 可选, 当模型初始化时使用with_projection=True时返回) — 通过将投影层应用于 pooler_output 获得的图像嵌入。 - cross_embeds (
torch.FloatTensor), 可选, 当模型初始化时使用with_projection=True时返回) — 通过将投影层应用于 pooler_output 获得的文本-图像跨模态嵌入。 - hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。 - attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。
BridgeTowerForContrastiveLearning 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> images = [Image.open(requests.get(url, stream=True).raw) for url in image_urls]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126BridgeTowerForMaskedLM
类 transformers.BridgeTowerForMaskedLM
< source >( config )
参数
- config (BridgeTowerConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
BridgeTower 模型,顶部带有语言建模头,与预训练期间相同。
该模型是一个PyTorch torch.nn.Module _ 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用AutoTokenizer获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入ID? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力机制的掩码。掩码值在[0, 1]中选择:- 1 表示未被掩码的标记,
- 0 表示被掩码的标记。 什么是注意力掩码?
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于指示输入的第一部分和第二部分的段标记索引。索引在[0, 1]中选择:- 0 对应于 句子 A 的标记,
- 1 对应于 句子 B 的标记。 什么是标记类型 ID?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 BridgeTowerImageProcessor 获取。详情请参见 BridgeTowerImageProcessor.call(). - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — 用于避免对填充像素值执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示真实的像素(即 未掩码),
- 0 表示填充的像素(即 掩码)。
什么是注意力掩码? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递pixel_values。 如果您希望对如何将pixel_values转换为补丁嵌入有更多控制,这将非常有用。 - image_token_type_idx (
int, 可选) —- 图像的令牌类型ID。
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, 默认为False) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]范围内(参见input_ids文档字符串)。索引设置为-100的标记将被忽略(掩码), 损失仅针对标签在[0, ..., config.vocab_size]范围内的标记进行计算
返回
transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MaskedLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BridgeTowerConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BridgeTowerForMaskedLM 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.BridgeTowerForImageAndTextRetrieval
类 transformers.BridgeTowerForImageAndTextRetrieval
< source >( config )
参数
- config (BridgeTowerConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
BridgeTower 模型转换器,顶部带有分类器头(在最终隐藏状态的 [CLS] 标记上有一个线性层),用于图像到文本的匹配。
该模型是一个PyTorch torch.nn.Module _ 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape({0})) — 词汇表中输入序列标记的索引。可以使用AutoTokenizer获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入ID? - attention_mask (
torch.FloatTensorof shape({0}), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。 什么是注意力掩码?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — 用于指示输入的第一部分和第二部分的段标记索引。索引在[0, 1]中选择:- 0 对应于 句子 A 的标记,
- 1 对应于 句子 B 的标记。 什么是标记类型 ID?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 BridgeTowerImageProcessor 获取。详情请参见 BridgeTowerImageProcessor.call(). - pixel_mask (
torch.LongTensor形状为(batch_size, height, width), 可选) — 用于避免对填充像素值执行注意力操作的掩码。掩码值在[0, 1]中选择:- 1 表示真实的像素(即 未掩码),
- 0 表示填充的像素(即 掩码)。
什么是注意力掩码? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - image_embeds (
torch.FloatTensor形状为(batch_size, num_patches, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递pixel_values。 如果您希望对如何将pixel_values转换为补丁嵌入有更多控制,这将非常有用。 - image_token_type_idx (
int, 可选) —- 图像的token类型id。
- output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, 默认为False) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, 1), optional) — 用于计算图像-文本匹配损失的标签。0表示这对不匹配,1表示匹配。 0的对将被跳过计算。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BridgeTowerConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BridgeTowerForImageAndTextRetrieval 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()