TVP
概述
文本视觉提示(TVP)框架由张一萌、陈鑫、贾静涵、刘思佳、丁可在论文Text-Visual Prompting for Efficient 2D Temporal Video Grounding中提出。
论文的摘要如下:
在本文中,我们研究了时间视频定位(TVG)问题,该问题旨在预测由文本句子描述的时刻在长未修剪视频中的开始/结束时间点。得益于细粒度的3D视觉特征,TVG技术在近年来取得了显著进展。然而,3D卷积神经网络(CNNs)的高复杂性使得提取密集的3D视觉特征耗时,这需要大量的内存和计算资源。为了实现高效的TVG,我们提出了一种新颖的文本-视觉提示(TVP)框架,该框架将优化的扰动模式(我们称之为“提示”)融入到TVG模型的视觉输入和文本特征中。与3D CNNs形成鲜明对比的是,我们展示了TVP使我们能够有效地在2D TVG模型中共同训练视觉编码器和语言编码器,并仅使用低复杂度的稀疏2D视觉特征来提高跨模态特征融合的性能。此外,我们提出了一种时间距离IoU(TDIoU)损失,用于高效学习TVG。在两个基准数据集Charades-STA和ActivityNet Captions上的实验表明,所提出的TVP显著提升了2D TVG的性能(例如,在Charades-STA上提高了9.79%,在ActivityNet Captions上提高了30.77%),并且比使用3D视觉特征的TVG实现了5倍的推理加速。
本研究探讨了时间视频定位(TVG),即通过文本句子描述,在长视频中精确定位特定事件的开始和结束时间的过程。提出了文本视觉提示(TVP)以增强TVG。TVP涉及将特别设计的模式(称为“提示”)集成到TVG模型的视觉(基于图像)和文本(基于单词)输入组件中。这些提示提供了额外的时空上下文,提高了模型准确确定视频中事件时间的能力。该方法采用2D视觉输入代替3D输入。尽管3D输入提供了更多的时空细节,但它们处理起来也更耗时。使用2D输入与提示方法旨在更高效地提供类似的上下文和准确性水平。
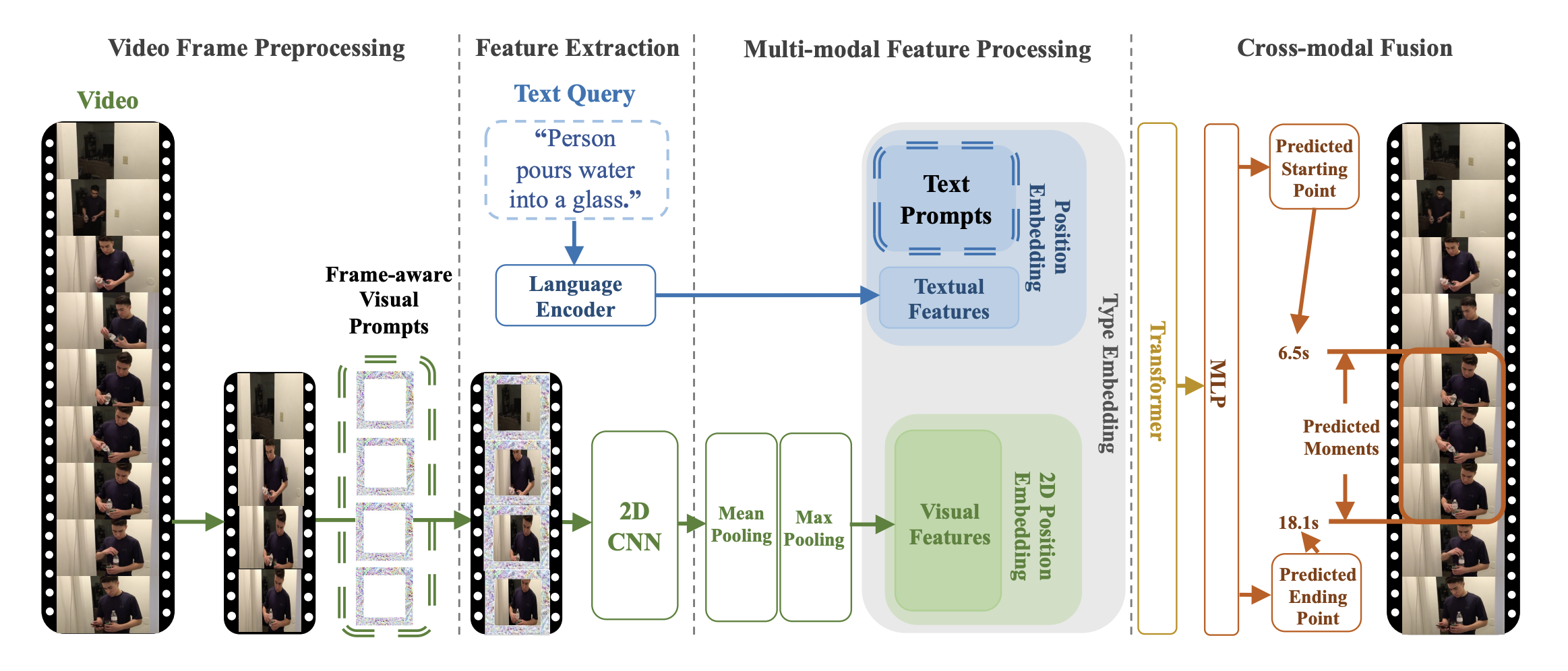 TVP architecture. Taken from the original paper.
TVP architecture. Taken from the original paper. 该模型由Jiqing Feng贡献。原始代码可以在这里找到。
使用技巧和示例
提示是优化的扰动模式,将被添加到输入视频帧或文本特征中。通用集指的是对任何输入使用相同的提示集,这意味着这些提示将一致地添加到所有视频帧和文本特征中,而不管输入的内容如何。
TVP由一个视觉编码器和跨模态编码器组成。一组通用的视觉提示和文本提示分别集成到采样的视频帧和文本特征中。特别地,一组不同的视觉提示按顺序应用于一个未修剪视频的均匀采样帧。
该模型的目标是将可训练的提示融入视觉输入和文本特征中,以解决时间视频定位(TVG)问题。 原则上,可以在所提出的架构中应用任何视觉、跨模态编码器。
TvpProcessor 将 BertTokenizer 和 TvpImageProcessor 封装到一个实例中,分别用于编码文本和准备图像。
以下示例展示了如何使用TvpProcessor和TvpForVideoGrounding运行时间视频定位。
import av
import cv2
import numpy as np
import torch
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, TvpForVideoGrounding
def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video. Return None if the no
video stream was found.
fps (float): the number of frames per second of the video.
'''
video = container.streams.video[0]
fps = float(video.average_rate)
clip_size = sampling_rate * num_frames / target_fps * fps
delta = max(num_frames - clip_size, 0)
start_idx = delta * clip_idx / num_clips
end_idx = start_idx + clip_size - 1
timebase = video.duration / num_frames
video_start_pts = int(start_idx * timebase)
video_end_pts = int(end_idx * timebase)
seek_offset = max(video_start_pts - 1024, 0)
container.seek(seek_offset, any_frame=False, backward=True, stream=video)
frames = {}
for frame in container.decode(video=0):
if frame.pts < video_start_pts:
continue
frames[frame.pts] = frame
if frame.pts > video_end_pts:
break
frames = [frames[pts] for pts in sorted(frames)]
return frames, fps
def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Decode the video and perform temporal sampling.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video.
'''
assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
clip_size = sampling_rate * num_frames / target_fps * fps
index = np.linspace(0, clip_size - 1, num_frames)
index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
frames = frames.transpose(0, 3, 1, 2)
return frames
file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
decoder_kwargs = dict(
container=av.open(file, metadata_errors="ignore"),
sampling_rate=1,
num_frames=model.config.num_frames,
clip_idx=0,
num_clips=1,
target_fps=3,
)
raw_sampled_frms = decode(**decoder_kwargs)
text = "a person is sitting on a bed."
processor = AutoProcessor.from_pretrained("Intel/tvp-base")
model_inputs = processor(
text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
)
model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
output = model(**model_inputs)
def get_video_duration(filename):
cap = cv2.VideoCapture(filename)
if cap.isOpened():
rate = cap.get(5)
frame_num = cap.get(7)
duration = frame_num/rate
return duration
return -1
duration = get_video_duration(file)
start, end = processor.post_process_video_grounding(output.logits, duration)
print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")提示:
- 此TVP实现使用BertTokenizer生成文本嵌入,并使用Resnet-50模型计算视觉嵌入。
- 预训练的tvp-base的检查点已发布。
- 请参考表2了解TVP在时序视频定位任务中的表现。
TvpConfig
类 transformers.TvpConfig
< source >( backbone_config = None backbone = None use_pretrained_backbone = False use_timm_backbone = False backbone_kwargs = None distance_loss_weight = 1.0 duration_loss_weight = 0.1 visual_prompter_type = 'framepad' visual_prompter_apply = 'replace' visual_prompt_size = 96 max_img_size = 448 num_frames = 48 vocab_size = 30522 hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 max_position_embeddings = 512 max_grid_col_position_embeddings = 100 max_grid_row_position_embeddings = 100 hidden_dropout_prob = 0.1 hidden_act = 'gelu' layer_norm_eps = 1e-12 initializer_range = 0.02 attention_probs_dropout_prob = 0.1 **kwargs )
参数
- backbone_config (
PretrainedConfig或dict, 可选) — 骨干模型的配置。 - backbone (
str, 可选) — 当backbone_config为None时使用的骨干网络名称。如果use_pretrained_backbone为True,这将从timm或transformers库加载相应的预训练权重。如果use_pretrained_backbone为False,这将加载骨干网络的配置并使用该配置初始化具有随机权重的骨干网络。 - use_pretrained_backbone (
bool, 可选, 默认为False) — 是否使用预训练的权重作为骨干网络。 - use_timm_backbone (
bool, optional, 默认为False) — 是否从 timm 库加载backbone。如果为False,则从 transformers 库加载 backbone。 - backbone_kwargs (
dict, 可选) — 从检查点加载时传递给AutoBackbone的关键字参数 例如{'out_indices': (0, 1, 2, 3)}。如果设置了backbone_config,则不能指定此参数。 - distance_loss_weight (
float, optional, defaults to 1.0) — 距离损失的权重。 - duration_loss_weight (
float, optional, defaults to 0.1) — 持续时间损失的权重。 - visual_prompter_type (
str, 可选, 默认为"framepad") — 视觉提示类型。填充的类型。Framepad 表示在每一帧上进行填充。应为 “framepad” 或 “framedownpad” 之一 - visual_prompter_apply (
str, 可选, 默认为"replace") — 应用视觉提示的方式。替换意味着使用提示的值来更改视觉输入中的原始值。应为“replace”、“add”或“remove”之一。 - visual_prompt_size (
int, optional, 默认为 96) — 视觉提示的大小。 - max_img_size (
int, optional, 默认为 448) — 帧的最大尺寸。 - num_frames (
int, optional, defaults to 48) — 从视频中提取的帧数。 - vocab_size (
int, 可选, 默认为 30522) — Tvp 文本模型的词汇表大小。定义了调用 TvpModel 时传递的inputs_ids可以表示的不同标记的数量。 - hidden_size (
int, optional, defaults to 768) — 编码器层的维度。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, defaults to 12) — Transformer编码器中每个注意力层的注意力头数。 - max_position_embeddings (
int, optional, 默认为 512) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - max_grid_col_position_embeddings (
int, optional, 默认为 100) — 视频帧中水平补丁的最大数量。 - max_grid_row_position_embeddings (
int, optional, 默认为 100) — 视频帧中垂直补丁的最大数量。 - hidden_dropout_prob (
float, optional, 默认为 0.1) — 隐藏层的丢弃概率。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","selu"和"gelu_new""quick_gelu". - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - initializer_range (
float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - attention_probs_dropout_prob (
float, optional, 默认为 0.1) — 注意力层的丢弃概率。
这是用于存储TvpModel配置的配置类。它用于根据指定的参数实例化Tvp模型,定义模型架构。使用默认值实例化配置将产生类似于Intel/tvp-base架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
from_backbone_config
< source >( backbone_config: PretrainedConfig **kwargs ) → TvpConfig
从预训练的主干模型配置中实例化一个TvpConfig(或派生类)。
将此实例序列化为Python字典。覆盖默认的to_dict()。
TvpImageProcessor
类 transformers.TvpImageProcessor
< source >( do_resize: bool = True size: typing.Dict[str, int] = None resample: Resampling =
参数
- do_resize (
bool, 可选, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中通过do_resize参数覆盖此设置。 - size (
Dict[str, int]可选, 默认为{"longest_edge" -- 448}): 调整大小后输出图像的尺寸。图像的最长边将被调整为size["longest_edge"],同时保持原始图像的宽高比。可以在preprocess方法中通过size覆盖此设置。 - resample (
PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 如果调整图像大小,使用的重采样过滤器。可以在preprocess方法中通过resample参数覆盖。 - do_center_crop (
bool, 可选, 默认为True) — 是否将图像中心裁剪到指定的crop_size。可以通过preprocess方法中的do_center_crop参数进行覆盖。 - crop_size (
Dict[str, int], 可选, 默认为{"height" -- 448, "width": 448}): 应用中心裁剪后的图像大小。可以通过preprocess方法中的crop_size参数进行覆盖。 - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess方法中通过do_rescale参数覆盖此设置。 - rescale_factor (
int或float, 可选, 默认为1/255) — 定义在重新缩放图像时使用的比例因子。可以在preprocess方法中通过rescale_factor参数覆盖此值。 - do_pad (
bool, 可选, 默认为True) — 是否对图像进行填充。可以在preprocess方法中通过do_pad参数进行覆盖。 - pad_size (
Dict[str, int], 可选, 默认为{"height" -- 448, "width": 448}): 应用填充后的图像大小。可以通过preprocess方法中的pad_size参数进行覆盖。 - constant_values (
Union[float, Iterable[float]], optional, defaults to 0) — 填充图像时使用的填充值。 - pad_mode (
PaddingMode, 可选, 默认为PaddingMode.CONSTANT) — 在填充中使用哪种模式。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。 - do_flip_channel_order (
bool, 可选, 默认为True) — 是否将颜色通道从RGB翻转为BGR。可以通过preprocess方法中的do_flip_channel_order参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以在preprocess方法中通过image_std参数进行覆盖。
构建一个Tvp图像处理器。
预处理
< source >( videos: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')], typing.List[typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]]], typing.List[typing.List[typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]]]]] do_resize: bool = None size: typing.Dict[str, int] = None resample: Resampling = None do_center_crop: bool = None crop_size: typing.Dict[str, int] = None do_rescale: bool = None rescale_factor: float = None do_pad: bool = None pad_size: typing.Dict[str, int] = None constant_values: typing.Union[float, typing.Iterable[float]] = None pad_mode: PaddingMode = None do_normalize: bool = None do_flip_channel_order: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension =
参数
- 视频 (
ImageInput或List[ImageInput]或List[List[ImageInput]]) — 要预处理的帧。 - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], optional, defaults toself.size) — 应用调整大小后的图像尺寸。 - resample (
PILImageResampling, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是枚举PILImageResampling中的一个,只有在do_resize设置为True时才会生效。 - do_center_crop (
bool, optional, defaults toself.do_centre_crop) — 是否对图像进行中心裁剪。 - crop_size (
Dict[str, int], optional, defaults toself.crop_size) — 应用中心裁剪后的图像大小。 - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到 [0 - 1] 之间。 - rescale_factor (
float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_pad (
bool, 可选, 默认为True) — 是否对图像进行填充。可以在preprocess方法中通过do_pad参数进行覆盖。 - pad_size (
Dict[str, int], 可选, 默认为{"height" -- 448, "width": 448}): 应用填充后的图像大小。可以在preprocess方法中通过pad_size参数覆盖此设置。 - constant_values (
Union[float, Iterable[float]], optional, defaults to 0) — 填充图像时使用的填充值。 - pad_mode (
PaddingMode, 可选, 默认为“PaddingMode.CONSTANT”) — 在填充中使用哪种模式。 - do_normalize (
bool, optional, defaults toself.do_normalize) — 是否对图像进行归一化处理。 - do_flip_channel_order (
bool, optional, defaults toself.do_flip_channel_order) — 是否翻转图像的通道顺序。 - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 图像均值. - image_std (
float或List[float], 可选, 默认为self.image_std) — 图像标准差. - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的推断通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
TvpProcessor
类 transformers.TvpProcessor
< source >( image_processor = 无 tokenizer = 无 **kwargs )
参数
- image_processor (TvpImageProcessor, optional) — 图像处理器是一个必需的输入。
- tokenizer (BertTokenizerFast, optional) — 分词器是一个必需的输入。
构建一个TVP处理器,它将TVP图像处理器和Bert分词器封装成一个单一的处理器。
TvpProcessor 提供了 TvpImageProcessor 和 BertTokenizerFast 的所有功能。更多信息请参见
call() 和 decode()。
__call__
< source >( text = None videos = None return_tensors = None **kwargs ) → BatchEncoding
参数
- text (
str,List[str],List[List[str]]) — 要编码的序列或序列批次。每个序列可以是一个字符串或一个字符串列表(预分词的字符串)。如果序列以字符串列表(预分词)的形式提供,你必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - 视频 (
List[PIL.Image.Image],List[np.ndarray],List[torch.Tensor],List[List[PIL.Image.Image]],List[List[np.ndarrray]], —List[List[torch.Tensor]]): 要准备的视频或视频批次。每个视频应该是一个帧列表,帧可以是PIL图像或NumPy数组。在NumPy数组/PyTorch张量的情况下,每帧的形状应为(H, W, C),其中H和W是帧的高度和宽度,C是通道数。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回特定框架的张量。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 NumPynp.ndarray对象。'jax': 返回 JAXjnp.ndarray对象。
一个 BatchEncoding 包含以下字段:
- input_ids — 要输入模型的标记ID列表。当
text不是None时返回。 - attention_mask — 指定模型应关注哪些标记的索引列表(当
return_attention_mask=True或如果 “attention_mask” 在self.model_input_names中且text不是None时)。 - pixel_values — 要输入模型的像素值。当
videos不是None时返回。
准备模型的一个或多个序列和图像的主要方法。如果text不为None,则此方法将text和kwargs参数转发给BertTokenizerFast的call()以编码文本。为了准备图像,如果videos不为None,则此方法将videos和kwargs参数转发给TvpImageProcessor的call()。请参考上述两个方法的文档字符串以获取更多信息。
TvpModel
类 transformers.TvpModel
< source >( config )
参数
- config (TvpConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的 Tvp 模型转换器输出 BaseModelOutputWithPooling 对象,顶部没有任何特定的头部。 该模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以了解与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None attention_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None interpolate_pos_encoding: bool = False ) → transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用AutoTokenizer获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入 ID? - pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用TvpImageProcessor获取。详情请参见TvpImageProcessor.call()。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。 什么是注意力掩码?
- head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - interpolate_pos_encoding (
bool, optional, defaults toFalse) — 是否插值预训练的图像填充提示编码和位置编码。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size)) — 序列的第一个标记(分类标记)在经过用于辅助预训练任务的层进一步处理后的最后一层隐藏状态。例如,对于BERT系列模型,这返回经过线性层和tanh激活函数处理后的分类标记。线性层的权重是在预训练期间通过下一个句子预测(分类)目标训练的。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力softmax后的注意力权重,用于计算自注意力头中的加权平均值。
TvpModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoConfig, AutoTokenizer, TvpModel
>>> model = TvpModel.from_pretrained("Jiqing/tiny-random-tvp")
>>> tokenizer = AutoTokenizer.from_pretrained("Jiqing/tiny-random-tvp")
>>> pixel_values = torch.rand(1, 1, 3, 448, 448)
>>> text_inputs = tokenizer("This is an example input", return_tensors="pt")
>>> output = model(text_inputs.input_ids, pixel_values, text_inputs.attention_mask)TvpForVideoGrounding
类 transformers.TvpForVideoGrounding
< source >( config )
参数
- config (TvpConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
带有视频定位头的Tvp模型,用于计算IoU、距离和持续时间损失。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None attention_mask: typing.Optional[torch.LongTensor] = None labels: typing.Tuple[torch.Tensor] = None head_mask: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None interpolate_pos_encoding: bool = False ) → transformers.models.tvp.modeling_tvp.TvpVideoGroundingOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用AutoTokenizer获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。什么是输入ID? - pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用 TvpImageProcessor 获取。详情请参见 TvpImageProcessor.call()。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。 什么是注意力掩码?
- head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - interpolate_pos_encoding (
bool, optional, defaults toFalse) — 是否插值预训练的图像填充提示编码和位置编码。 - labels (
torch.FloatTensorof shape(batch_size, 3), optional) — 标签包含与文本对应的视频的持续时间、开始时间和结束时间。
返回
transformers.models.tvp.modeling_tvp.TvpVideoGroundingOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.tvp.modeling_tvp.TvpVideoGroundingOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
- loss (
torch.FloatTensor形状为(1,), 可选, 当return_loss为True时返回) — 视频定位的时间距离 IoU 损失。 - logits (
torch.FloatTensor形状为(batch_size, 2)) — 包含开始时间/持续时间和结束时间/持续时间。它是与输入文本对应的视频时间段。 - hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出时的隐藏状态加上可选的初始嵌入输出。 - attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。
TvpForVideoGrounding 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoConfig, AutoTokenizer, TvpForVideoGrounding
>>> model = TvpForVideoGrounding.from_pretrained("Jiqing/tiny-random-tvp")
>>> tokenizer = AutoTokenizer.from_pretrained("Jiqing/tiny-random-tvp")
>>> pixel_values = torch.rand(1, 1, 3, 448, 448)
>>> text_inputs = tokenizer("This is an example input", return_tensors="pt")
>>> output = model(text_inputs.input_ids, pixel_values, text_inputs.attention_mask)