牛轧糖
概述
Nougat模型由Lukas Blecher、Guillem Cucurull、Thomas Scialom和Robert Stojnic在Nougat: Neural Optical Understanding for Academic Documents中提出。Nougat使用与Donut相同的架构,即图像Transformer编码器和自回归文本Transformer解码器,将科学PDF转换为markdown,使其更易于访问。
论文的摘要如下:
科学知识主要存储在书籍和科学期刊中,通常以PDF的形式存在。然而,PDF格式会导致语义信息的丢失,特别是对于数学表达式。我们提出了Nougat(学术文档的神经光学理解),这是一种视觉Transformer模型,用于执行光学字符识别(OCR)任务,将科学文档处理为标记语言,并在一个新的科学文档数据集上展示了我们模型的有效性。所提出的方法通过弥合人类可读文档和机器可读文本之间的差距,为增强数字时代科学知识的可访问性提供了一个有前景的解决方案。我们发布了模型和代码,以加速未来在科学文本识别方面的工作。
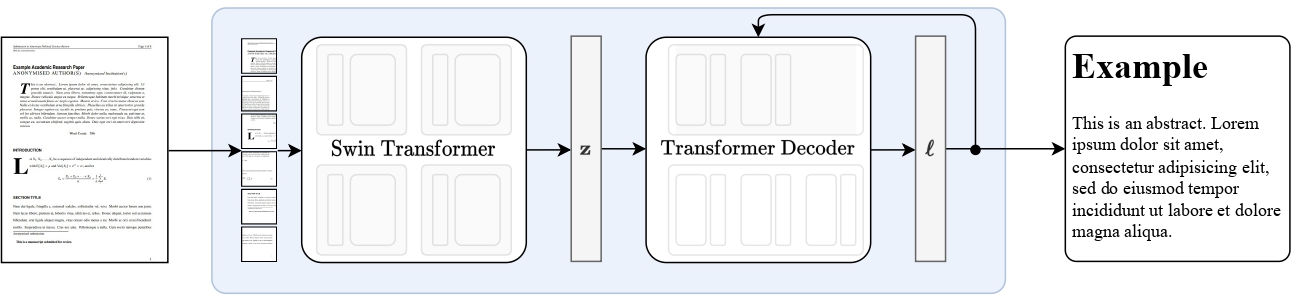 Nougat high-level overview. Taken from the original paper.
Nougat high-level overview. Taken from the original paper. 使用提示
- 开始使用Nougat的最快方法是查看教程笔记本,其中展示了如何在推理时使用模型以及如何对自定义数据进行微调。
- Nougat 总是在 VisionEncoderDecoder 框架内使用。该模型在架构上与 Donut 相同。
推理
Nougat的VisionEncoderDecoder模型接受图像作为输入,并利用generate()根据输入图像自回归生成文本。
NougatImageProcessor 类负责预处理输入图像,而 NougatTokenizerFast 将生成的目标标记解码为目标字符串。 NougatProcessor 将 NougatImageProcessor 和 NougatTokenizerFast 类 包装成一个实例,以提取输入特征并解码预测的标记ID。
- 逐步PDF转录
>>> from huggingface_hub import hf_hub_download
>>> import re
>>> from PIL import Image
>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
>>> from datasets import load_dataset
>>> import torch
>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device)
>>> # prepare PDF image for the model
>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
>>> image = Image.open(filepath)
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> # generate transcription (here we only generate 30 tokens)
>>> outputs = model.generate(
... pixel_values.to(device),
... min_length=1,
... max_new_tokens=30,
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
... )
>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
>>> print(repr(sequence))
'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'查看模型中心以寻找Nougat检查点。
该模型在架构上与Donut相同。
NougatImageProcessor
类 transformers.NougatImageProcessor
< source >( do_crop_margin: bool = True do_resize: bool = True size: typing.Dict[str, int] = None resample: Resampling =
参数
- do_crop_margin (
bool, optional, defaults toTrue) — 是否裁剪图像边缘。 - do_resize (
bool, 可选, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中被do_resize覆盖。 - size (
Dict[str, int]可选, 默认为{"height" -- 896, "width": 672}): 调整大小后的图像尺寸。可以在preprocess方法中通过size覆盖此设置。 - resample (
PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 如果调整图像大小,则使用的重采样过滤器。可以在preprocess方法中通过resample覆盖。 - do_thumbnail (
bool, 可选, 默认为True) — 是否使用缩略图方法调整图像大小. - do_align_long_axis (
bool, 可选, 默认为False) — 是否通过旋转90度将图像的长轴与size的长轴对齐。 - do_pad (
bool, 可选, 默认为True) — 是否将图像填充到批次中最大图像的尺寸。 - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor来重新缩放图像。可以在preprocess方法中通过do_rescale参数进行覆盖。 - rescale_factor (
int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以在preprocess方法中通过rescale_factor参数覆盖此值。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_DEFAULT_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_DEFAULT_STD) — 图像标准差.
构建一个Nougat图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_crop_margin: bool = None do_resize: bool = None size: typing.Dict[str, int] = None resample: Resampling = None do_thumbnail: bool = None do_align_long_axis: bool = None do_pad: bool = None do_rescale: bool = None rescale_factor: typing.Union[int, float] = None do_normalize: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Optional[transformers.image_utils.ChannelDimension] =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或一批图像,像素值范围从0到255。 - do_crop_margin (
bool, optional, defaults toself.do_crop_margin) — 是否裁剪图像边缘。 - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], 可选, 默认为self.size) — 调整大小后的图像尺寸。图像的最短边将调整为min(size[“height”], size[“width”]),最长边将按比例调整以保持输入的宽高比。 - resample (
int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是枚举PILImageResampling中的一个。只有在do_resize设置为True时才会生效。 - do_thumbnail (
bool, 可选, 默认为self.do_thumbnail) — 是否使用缩略图方法调整图像大小. - do_align_long_axis (
bool, 可选, 默认为self.do_align_long_axis) — 是否通过旋转90度将图像的长轴与size的长轴对齐。 - do_pad (
bool, 可选, 默认为self.do_pad) — 是否将图像填充到批次中最大图像的大小。 - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否通过指定的比例rescale_factor来重新缩放图像。 - rescale_factor (
int或float, 可选, 默认为self.rescale_factor) — 如果重新缩放图像,则使用的缩放因子。 - do_normalize (
bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化处理. - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 用于归一化的图像均值. - image_std (
float或List[float], 可选, 默认为self.image_std) — 用于归一化的图像标准差. - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:默认为输入图像的通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
NougatTokenizerFast
类 transformers.NougatTokenizerFast
< source >( vocab_file = 无 tokenizer_file = 无 clean_up_tokenization_spaces = 假 unk_token = '' eos_token = '' pad_token = '
参数
- vocab_file (
str, 可选) — SentencePiece 文件(通常具有 .model 扩展名),包含实例化分词器所需的词汇表。 - tokenizer_file (
str, optional) — tokenizers 文件(通常具有 .json 扩展名),包含加载分词器所需的所有内容。 - clean_up_tokenization_spaces (
str, optional, defaults toFalse) — 是否在解码后清理空格,清理包括移除潜在的额外空格等可能的痕迹。 - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - bos_token (
str, optional, defaults to") — 在预训练期间使用的序列开始标记。可以用作序列分类器标记。" - eos_token (
str, optional, defaults to"") — 序列结束标记。 - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - model_max_length (
int, optional) — 变压器模型输入的最大长度(以令牌数计)。当使用from_pretrained()加载分词器时,这将设置为存储在max_model_input_sizes中的关联模型的值(见上文)。如果未提供值,则默认为VERY_LARGE_INTEGER (int(1e30))。 - padding_side (
str, optional) — 模型应在哪一侧应用填充。应在['right', 'left']之间选择。 默认值从同名的类属性中选取。 - truncation_side (
str, optional) — 模型应在哪一侧应用截断。应在['right', 'left']之间选择。 默认值从同名的类属性中选取。 - chat_template (
str, optional) — 一个用于格式化聊天消息列表的Jinja模板字符串。有关完整描述,请参见 https://huggingface.co/docs/transformers/chat_templating. - model_input_names (
List[string], 可选) — 模型前向传递接受的输入列表(如"token_type_ids"或"attention_mask")。默认值从同名的类属性中选取。 - bos_token (
str或tokenizers.AddedToken, 可选) — 表示句子开头的特殊标记。将与self.bos_token和self.bos_token_id关联。 - eos_token (
str或tokenizers.AddedToken, 可选) — 表示句子结束的特殊标记。将与self.eos_token和self.eos_token_id关联。 - unk_token (
str或tokenizers.AddedToken, 可选) — 一个表示词汇表外词的特殊标记。将与self.unk_token和self.unk_token_id关联。 - sep_token (
str或tokenizers.AddedToken, 可选) — 用于分隔同一输入中的两个不同句子的特殊标记(例如BERT使用)。将关联到self.sep_token和self.sep_token_id. - pad_token (
str或tokenizers.AddedToken, 可选) — 用于使令牌数组在批处理时大小相同的特殊令牌。随后将被注意力机制或损失计算忽略。将与self.pad_token和self.pad_token_id关联。 - cls_token (
str或tokenizers.AddedToken, 可选) — 一个表示输入类别的特殊标记(例如由BERT使用)。将与self.cls_token和self.cls_token_id关联。 - mask_token (
str或tokenizers.AddedToken, 可选) — 一个特殊的标记,表示一个被掩码的标记(用于掩码语言建模预训练目标,如BERT)。将与self.mask_token和self.mask_token_id关联。 - additional_special_tokens (元组或列表,元素类型为
str或tokenizers.AddedToken, 可选) — 一个包含额外特殊标记的元组或列表。将它们添加到这里以确保在解码时,当skip_special_tokens设置为 True 时,这些标记会被跳过。如果它们不是词汇表的一部分,它们将被添加到词汇表的末尾。 - clean_up_tokenization_spaces (
bool, 可选, 默认为True) — 模型是否应该清理在分词过程中添加的空格,这些空格是在拆分输入文本时添加的。 - split_special_tokens (
bool, optional, defaults toFalse) — 是否在分词过程中拆分特殊标记。传递此参数将影响分词器的内部状态。默认行为是不拆分特殊标记。这意味着如果bos_token,那么tokenizer.tokenize("]。否则,如果") = ['split_special_tokens=True,那么tokenizer.tokenize("将会得到")['<','s', '>']. - tokenizer_object (
tokenizers.Tokenizer) — 一个来自🤗 tokenizers的tokenizers.Tokenizer对象,用于实例化。有关更多信息,请参见使用🤗 tokenizers的tokenizers. - tokenizer_file (
str) — 一个指向本地JSON文件的路径,该文件表示之前从🤗 tokenizers序列化的tokenizers.Tokenizer对象。
Nougat的快速分词器(由HuggingFace分词器库支持)。
这个分词器继承自PreTrainedTokenizerFast,其中包含了大部分主要方法。用户应参考这个超类以获取有关这些方法的更多信息。这个类主要添加了用于后处理生成文本的Nougat特定方法。
类属性(由派生类覆盖)
- vocab_files_names (
Dict[str, str]) — 一个字典,其键为模型所需的每个词汇文件的__init__关键字名称,关联的值为保存相关文件的文件名(字符串)。 - pretrained_vocab_files_map (
Dict[str, Dict[str, str]]) — 一个字典的字典,其中高级键是模型所需的每个词汇表文件的__init__关键字名称,低级键是预训练模型的short-cut-names,关联值是相关预训练词汇表文件的url。 - model_input_names (
List[str]) — 模型前向传递中期望的输入列表。 - padding_side (
str) — 模型应用填充的默认边。 应为'right'或'left'。 - truncation_side (
str) — 模型应用截断的默认侧。应为'right'或'left'。
correct_tables
< source >( generation: str ) → str
获取生成的字符串并修复表格/表格,使其符合所需的markdown格式。
post_process_generation
< source >( generation: typing.Union[str, typing.List[str]] fix_markdown: bool = True num_workers: int = None ) → Union[str, List[str]]
对生成的文本或生成的文本列表进行后处理。
此函数可用于对生成的文本进行后处理,例如修复Markdown格式。
后处理速度较慢,因此建议使用多进程来加快处理速度。
post_process_single
< source >( generation: str fix_markdown: bool = True ) → str
对单个生成的文本进行后处理。这里使用的正则表达式直接来自Nougat文章的作者。这些表达式为了清晰起见进行了注释,并且在大多数情况下进行了端到端的测试。
remove_hallucinated_references
< source >( text: str ) → str
从文本中删除虚构或缺失的引用。
此函数识别并移除输入文本中标记为缺失或虚构的引用。
NougatProcessor
类 transformers.NougatProcessor
< source >( image_processor tokenizer )
参数
- image_processor (NougatImageProcessor) — 一个 NougatImageProcessor 的实例。图像处理器是一个必需的输入。
- tokenizer (NougatTokenizerFast) — 一个 NougatTokenizerFast 的实例。tokenizer 是一个必需的输入。
构建一个Nougat处理器,它将Nougat图像处理器和Nougat分词器封装到一个处理器中。
NougatProcessor 提供了 NougatImageProcessor 和 NougatTokenizerFast 的所有功能。更多信息请参见 call() 和 decode()。
__call__
< source >( images = None text = None do_crop_margin: bool = None do_resize: bool = None size: typing.Dict[str, int] = None resample: PILImageResampling = None do_thumbnail: bool = None do_align_long_axis: bool = None do_pad: bool = None do_rescale: bool = None rescale_factor: typing.Union[int, float] = None do_normalize: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None data_format: typing.Optional[ForwardRef('ChannelDimension')] = 'channels_first' input_data_format: typing.Union[str, ForwardRef('ChannelDimension'), NoneType] = None text_pair: typing.Union[str, typing.List[str], typing.List[typing.List[str]], NoneType] = None text_target: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] = None text_pair_target: typing.Union[str, typing.List[str], typing.List[typing.List[str]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True )
from_pretrained
< source >( pretrained_model_name_or_path: typing.Union[str, os.PathLike] cache_dir: typing.Union[str, os.PathLike, NoneType] = None force_download: bool = False local_files_only: bool = False token: typing.Union[str, bool, NoneType] = None revision: str = 'main' **kwargs )
参数
- pretrained_model_name_or_path (
str或os.PathLike) — 这可以是以下之一:- 一个字符串,表示托管在 huggingface.co 上的模型仓库中的预训练特征提取器的 模型 id。
- 一个路径,指向使用 save_pretrained() 方法保存的特征提取器文件的 目录,例如
./my_model_directory/。 - 一个路径或 URL,指向保存的特征提取器 JSON 文件,例如
./my_model_directory/preprocessor_config.json。
- **kwargs —
传递给from_pretrained()和
~tokenization_utils_base.PreTrainedTokenizer.from_pretrained的额外关键字参数.
实例化一个与预训练模型关联的处理器。
这个类方法只是简单地调用了特征提取器
from_pretrained(),图像处理器
ImageProcessingMixin 和分词器
~tokenization_utils_base.PreTrainedTokenizer.from_pretrained 方法。请参考上述方法的文档字符串以获取更多信息。
save_pretrained
< source >( save_directory push_to_hub: bool = False **kwargs )
参数
- save_directory (
stroros.PathLike) — 保存特征提取器 JSON 文件和分词器文件的目录(如果目录不存在,将会创建)。 - push_to_hub (
bool, optional, defaults toFalse) — 是否在保存后将模型推送到 Hugging Face 模型中心。您可以使用repo_id指定要推送到的仓库(默认为您命名空间中的save_directory名称)。 - kwargs (
Dict[str, Any], 可选) — 传递给 push_to_hub() 方法的额外关键字参数。
保存此处理器(特征提取器、分词器等)的属性到指定目录,以便可以使用from_pretrained()方法重新加载。
这个类方法只是调用了 save_pretrained() 和 save_pretrained()。请参考上述方法的文档字符串以获取更多信息。
此方法将其所有参数转发给NougatTokenizer的batch_decode()。请参考该方法的文档字符串以获取更多信息。
此方法将其所有参数转发给NougatTokenizer的decode()。请参考该方法的文档字符串以获取更多信息。
此方法将其所有参数转发给NougatTokenizer的~PreTrainedTokenizer.post_process_generation。
有关更多信息,请参阅此方法的文档字符串。