LLaVa
概述
LLaVa 是一个开源的聊天机器人,通过在 GPT 生成的多模态指令跟随数据上微调 LlamA/Vicuna 进行训练。它是一个基于 transformer 架构的自回归语言模型。换句话说,它是为聊天/指令微调的多模态版本的 LLMs。
LLaVa模型在Visual Instruction Tuning中提出,并在Improved Baselines with Visual Instruction Tuning中由Haotian Liu、Chunyuan Li、Yuheng Li和Yong Jae Lee进行了改进。
论文的摘要如下:
大型多模态模型(LMM)最近在视觉指令调优方面显示出令人鼓舞的进展。在本笔记中,我们展示了LLaVA中全连接的视觉-语言跨模态连接器出人意料地强大且数据高效。通过对LLaVA进行简单的修改,即使用带有MLP投影的CLIP-ViT-L-336px,并添加面向学术任务的VQA数据和简单的响应格式化提示,我们建立了更强的基线,在11个基准测试中实现了最先进的性能。我们最终的13B检查点仅使用了120万公开可用的数据,并在单个8-A100节点上在约1天内完成了全部训练。我们希望这能使最先进的LMM研究更加易于接触。代码和模型将公开提供
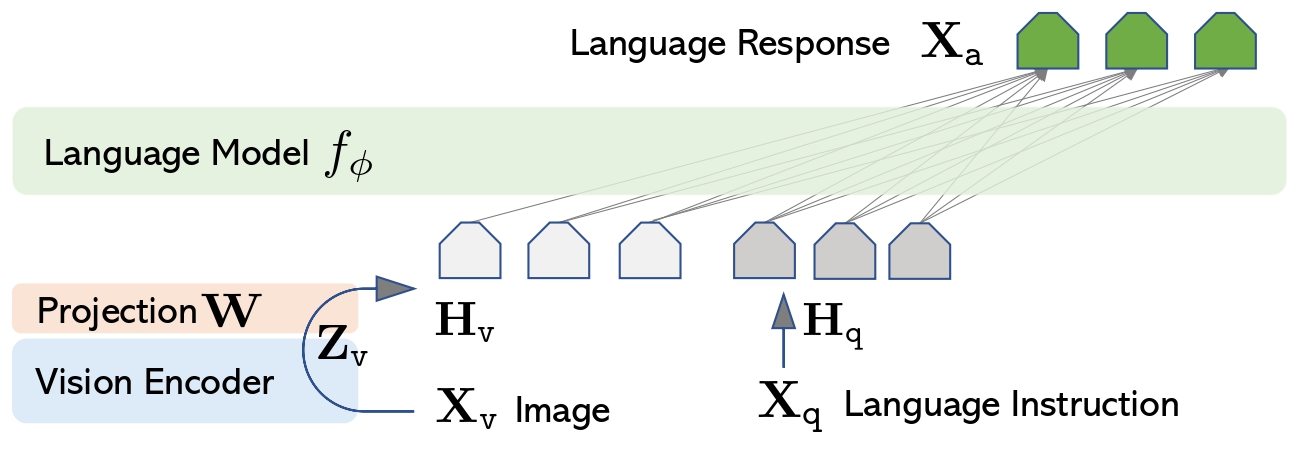 LLaVa architecture. Taken from the original paper.
LLaVa architecture. Taken from the original paper. 该模型由ArthurZ和ybelkada贡献。 原始代码可以在这里找到。
使用提示
我们建议用户在计算批量生成时使用
padding_side="left",因为它可以带来更准确的结果。只需确保在生成之前调用processor.tokenizer.padding_side = "left"。请注意,该模型并未经过明确训练以处理同一提示中的多张图像,尽管这在技术上是可行的,但您可能会遇到不准确的结果。
[!注意] LLaVA模型在发布v4.46版本后,将会发出关于添加
processor.patch_size = {{patch_size}}、processor.num_additional_image_tokens = {{num_additional_image_tokens}}和processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}的警告。强烈建议如果您拥有模型检查点,请将这些属性添加到处理器中,或者如果不是您拥有的,请提交一个PR。添加这些属性意味着LLaVA将尝试推断每张图像所需的图像令牌数量,并使用尽可能多的占位符扩展文本。通常每张图像大约有500个令牌,因此请确保文本没有被截断,否则在合并嵌入时会出现失败。这些属性可以从模型配置中获取,如model.config.vision_config.patch_size或model.config.vision_feature_select_strategy。如果视觉骨干添加了CLS令牌,则num_additional_image_tokens应为1,如果没有向视觉补丁添加额外内容,则应为0`。
单张图像推理
为了获得最佳效果,我们建议用户使用处理器的apply_chat_template()方法来正确格式化您的提示。为此,您需要构建一个对话历史记录,传入纯字符串将无法格式化您的提示。聊天模板中的每条对话历史记录消息都是一个包含“role”和“content”键的字典。“content”应该是一个字典列表,用于“text”和“image”模式,如下所示:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
conversation = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What’s shown in this image?"},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": "This image shows a red stop sign."},]
},
{
"role": "user",
"content": [
{"type": "text", "text": "Describe the image in more details."},
],
},
]
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your images
print(text_prompt)
>>> "USER: <image>\n<What’s shown in this image? ASSISTANT: This image shows a red stop sign.</s>USER: Describe the image in more details. ASSISTANT:"批量推理
LLaVa 还支持批量推理。以下是您可以如何操作的方法:
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
# Load the model in half-precision
model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf", torch_dtype=torch.float16, device_map="auto")
processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
# Get two different images
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image_stop = Image.open(requests.get(url, stream=True).raw)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image_cats = Image.open(requests.get(url, stream=True).raw)
# Prepare a batch of two prompts
conversation_1 = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What is shown in this image?"},
],
},
]
conversation_2 = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What is shown in this image?"},
],
},
]
prompt_1 = processor.apply_chat_template(conversation_1, add_generation_prompt=True)
prompt_2 = processor.apply_chat_template(conversation_2, add_generation_prompt=True)
prompts = [prompt_1, prompt_2]
# We can simply feed images in the order they have to be used in the text prompt
inputs = processor(images=[image_stop, image_cats, image_snowman], text=prompts, padding=True, return_tensors="pt").to(model.device, torch.float16)
# Generate
generate_ids = model.generate(**inputs, max_new_tokens=30)
processor.batch_decode(generate_ids, skip_special_tokens=True)- 如果你想自己构建一个聊天提示,以下是每个llava检查点接受的提示格式列表:
llava-interleave models 需要以下格式:
"<|im_start|>user <image>\nWhat is shown in this image?<|im_end|><|im_start|>assistant"对于多轮对话:
"<|im_start|>user <image>\n<prompt1><|im_end|><|im_start|>assistant <answer1><|im_end|><|im_start|>user <image>\n<prompt1><|im_end|><|im_start|>assistant "llava-1.5 models 需要以下格式:
"USER: <image>\n<prompt> ASSISTANT:"对于多轮对话:
"USER: <image>\n<prompt1> ASSISTANT: <answer1></s>USER: <prompt2> ASSISTANT: <answer2></s>USER: <prompt3> ASSISTANT:"使用 Flash Attention 2
Flash Attention 2 是之前优化版本的更快、更优化的版本,请参考 性能文档中的 Flash Attention 2 部分。
资源
一份官方的Hugging Face和社区(由🌎表示)资源列表,帮助您开始使用BEiT。
- 一个Google Colab演示,展示了如何在免费的Google Colab实例上利用4位推理运行Llava。
- 一个类似的笔记本展示了批量推理。🌎
LlavaConfig
类 transformers.LlavaConfig
< source >( vision_config = 无 text_config = 无 ignore_index = -100 image_token_index = 32000 projector_hidden_act = 'gelu' vision_feature_select_strategy = '默认' vision_feature_layer = -2 image_seq_length = 576 **kwargs )
参数
- vision_config (
Union[AutoConfig, dict], optional, defaults toCLIPVisionConfig) — 视觉骨干的配置对象或字典。 - text_config (
Union[AutoConfig, dict], 可选, 默认为LlamaConfig) — 文本主干的配置对象或字典. - ignore_index (
int, optional, 默认为 -100) — 损失函数的忽略索引。 - image_token_index (
int, optional, 默认为 32000) — 用于编码图像提示的图像令牌索引。 - projector_hidden_act (
str, optional, defaults to"gelu") — 多模态投影器使用的激活函数。 - vision_feature_select_strategy (
str, 可选, 默认为"default") — 用于从视觉骨干中选择视觉特征的特征选择策略。 可以是"default"或"full"之一。 - vision_feature_layer (
int, optional, defaults to -2) — 选择视觉特征的层的索引。 - image_seq_length (
int, optional, 默认为 576) — 一张图片嵌入的序列长度。
这是用于存储LlavaForConditionalGeneration配置的配置类。它用于根据指定的参数实例化一个Llava模型,定义模型架构。使用默认值实例化配置将产生类似于Llava-9B的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import LlavaForConditionalGeneration, LlavaConfig, CLIPVisionConfig, LlamaConfig
>>> # Initializing a CLIP-vision config
>>> vision_config = CLIPVisionConfig()
>>> # Initializing a Llama config
>>> text_config = LlamaConfig()
>>> # Initializing a Llava llava-1.5-7b style configuration
>>> configuration = LlavaConfig(vision_config, text_config)
>>> # Initializing a model from the llava-1.5-7b style configuration
>>> model = LlavaForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configLlavaProcessor
类 transformers.LlavaProcessor
< source >( image_processor = 无 tokenizer = 无 patch_size = 无 vision_feature_select_strategy = 无 chat_template = 无 image_token = '' num_additional_image_tokens = 0 **kwargs )
参数
- image_processor (CLIPImageProcessor, optional) — 图像处理器是一个必需的输入。
- tokenizer (LlamaTokenizerFast, optional) — tokenizer 是一个必需的输入。
- patch_size (
int, optional) — 视觉塔中的补丁大小。 - vision_feature_select_strategy (
str, optional) — 用于从视觉骨干中选择视觉特征的特征选择策略。 应与模型配置中的相同 - chat_template (
str, optional) — 一个Jinja模板,用于将聊天中的消息列表转换为可标记的字符串。 - image_token (
str, 可选, 默认为") — 用于表示图像位置的特殊标记。"
- num_additional_image_tokens (
int, optional, 默认为 0) — 添加到图像嵌入中的额外令牌数量,例如 CLS (+1)。如果骨干网络没有 CLS 或其他额外令牌附加,则无需设置此参数。
构建一个Llava处理器,它将Llava图像处理器和Llava分词器封装到一个单一的处理器中。
LlavaProcessor 提供了 CLIPImageProcessor 和 LlamaTokenizerFast 的所有功能。更多信息请参见
__call__() 和 decode()。
此方法将其所有参数转发给LlamaTokenizerFast的batch_decode()。请参考该方法的文档字符串以获取更多信息。
此方法将其所有参数转发给LlamaTokenizerFast的decode()。请参考该方法的文档字符串以获取更多信息。
LlavaForConditionalGeneration
类 transformers.LlavaForConditionalGeneration
< source >( config: LlavaConfig )
参数
- config (LlavaConfig 或
LlavaVisionConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
LLAVA模型由视觉骨干和语言模型组成。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: LongTensor = None pixel_values: FloatTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None vision_feature_layer: typing.Optional[int] = None vision_feature_select_strategy: typing.Optional[str] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None num_logits_to_keep: int = 0 ) → transformers.models.llava.modeling_llava.LlavaCausalLMOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, image_size, image_size)) -- 对应于输入图像的张量。可以使用 [AutoImageProcessor](/docs/transformers/v4.47.1/en/model_doc/auto#transformers.AutoImageProcessor) 获取像素值。有关详细信息,请参阅 [CLIPImageProcessor.__call__()](/docs/transformers/v4.47.1/en/model_doc/imagegpt#transformers.ImageGPTFeatureExtractor.__call__)([]LlavaProcessor`] 使用 CLIPImageProcessor 处理图像)。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,则可以选择性地仅输入最后一个decoder_input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围在[0, config.n_positions - 1]内。What are position IDs? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - vision_feature_layer (
int, optional, defaults to -2) — 选择视觉特征的层的索引。 - vision_feature_select_strategy (
str, 可选, 默认为"default") — 用于从视觉骨干中选择视觉特征的特征选择策略。 可以是"default"或"full"之一。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids相反, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。 - Args —
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional): Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].num_logits_to_keep (
int, 可选): 计算最后num_logits_to_keep个token的logits。如果为0,则计算所有input_ids的logits(特殊情况)。生成时只需要最后一个token的logits,仅计算该token的logits可以节省内存,这对于长序列或大词汇量来说非常重要。
返回
transformers.models.llava.modeling_llava.LlavaCausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.models.llava.modeling_llava.LlavaCausalLMOutputWithPast 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(LlavaConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个标记的预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量包含预计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
image_hidden_states (
torch.FloatTensor,可选) — 一个大小为 (batch_size, num_images, sequence_length, hidden_size)` 的torch.FloatTensor。 由视觉编码器生成并在投影最后一个隐藏状态后的模型的 image_hidden_states。
LlavaForConditionalGeneration 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, LlavaForConditionalGeneration
>>> model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf")
>>> processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
>>> prompt = "USER: <image>\nWhat's the content of the image? ASSISTANT:"
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(**inputs, max_new_tokens=15)
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"USER: \nWhat's the content of the image? ASSISTANT: The image features a busy city street with a stop sign prominently displayed"