UDOP
概述
UDOP模型由Zineng Tang、Ziyi Yang、Guoxin Wang、Yuwei Fang、Yang Liu、Chenguang Zhu、Michael Zeng、Cha Zhang和Mohit Bansal在《Unifying Vision, Text, and Layout for Universal Document Processing》中提出。 UDOP采用基于T5的编码器-解码器Transformer架构,用于文档AI任务,如文档图像分类、文档解析和文档视觉问答。
论文的摘要如下:
我们提出了通用文档处理(UDOP),这是一个基础的文档AI模型,它将文本、图像和布局模态与各种任务格式(包括文档理解和生成)统一在一起。UDOP利用文本内容和文档图像之间的空间相关性,通过一种统一的表示方式来建模图像、文本和布局模态。通过一种新颖的视觉-文本-布局Transformer,UDOP将预训练和多领域下游任务统一到一个基于提示的序列生成方案中。UDOP在大规模未标记文档语料库上使用创新的自监督目标和多样化的标记数据进行预训练。UDOP还通过学习从文本和布局模态生成文档图像,通过掩码图像重建。据我们所知,这是文档AI领域首次有一个模型同时实现了高质量的神经文档编辑和内容定制。我们的方法在9个文档AI任务(例如文档理解和问答)上设定了最先进的水平,涵盖了财务报告、学术论文和网站等多样化的数据领域。UDOP在文档理解基准(DUE)排行榜上排名第一。*
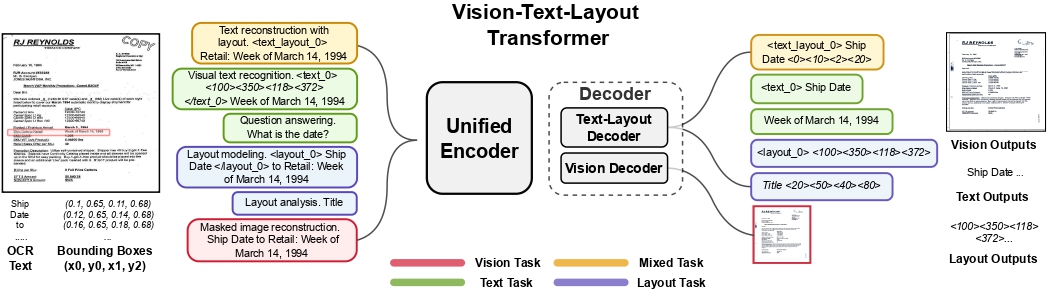 UDOP architecture. Taken from the original paper.
UDOP architecture. Taken from the original paper. 使用提示
- 除了input_ids,UdopForConditionalGeneration还期望输入
bbox,这是输入标记的边界框(即2D位置)。这些可以通过使用外部OCR引擎(如Google的Tesseract,有一个Python包装器可用)获得。每个边界框应为(x0, y0, x1, y1)格式,其中(x0, y0)对应于边界框左上角的位置,(x1, y1)表示右下角的位置。请注意,首先需要将边界框归一化到0-1000的比例。要进行归一化,可以使用以下函数:
def normalize_bbox(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]这里,width 和 height 对应于标记出现的原始文档的宽度和高度。例如,可以使用Python图像库(PIL)库来获取这些值,如下所示:
from PIL import Image
# Document can be a png, jpg, etc. PDFs must be converted to images.
image = Image.open(name_of_your_document).convert("RGB")
width, height = image.size可以使用UdopProcessor来为模型准备图像和文本,它会处理所有这些。默认情况下,这个类使用Tesseract引擎从给定文档中提取单词和框(坐标)的列表。它的功能与LayoutLMv3Processor相同,因此它支持传递apply_ocr=False,以防你更喜欢使用自己的OCR引擎,或者传递apply_ocr=True,以防你希望使用默认的OCR引擎。有关所有可能的用例,请参考LayoutLMv2的使用指南(UdopProcessor的功能是相同的)。
- 如果选择使用自己的OCR引擎,一个推荐是Azure的Read API,它支持所谓的线段。使用段位置嵌入通常会导致更好的性能。
- 在推理时,建议使用
generate方法根据文档图像自回归生成文本。 - 该模型已经在自监督和监督目标上进行了预训练。可以使用预训练期间使用的各种任务前缀(提示)来测试开箱即用的能力。例如,可以用“问答。日期是什么?”来提示模型,因为“问答。”是预训练期间用于DocVQA的任务前缀。有关所有任务前缀,请参阅论文(表1)。
- 还可以微调UdopEncoderModel,这是UDOP的仅编码器部分,可以看作是类似LayoutLMv3的Transformer编码器。对于判别任务,只需在其顶部添加一个线性分类器,并在标记的数据集上进行微调。
资源
以下是官方Hugging Face和社区(由🌎表示)提供的资源列表,帮助您开始使用UDOP。如果您有兴趣提交资源以包含在此处,请随时打开一个Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
UdopConfig
类 transformers.UdopConfig
< source >( vocab_size = 33201 d_model = 1024 d_kv = 64 d_ff = 4096 num_layers = 24 num_decoder_layers = None num_heads = 16 relative_attention_num_buckets = 32 relative_attention_max_distance = 128 relative_bias_args = [{'type': '1d'}, {'type': 'horizontal'}, {'type': 'vertical'}] dropout_rate = 0.1 layer_norm_epsilon = 1e-06 initializer_factor = 1.0 feed_forward_proj = 'relu' is_encoder_decoder = True use_cache = True pad_token_id = 0 eos_token_id = 1 max_2d_position_embeddings = 1024 image_size = 224 patch_size = 16 num_channels = 3 **kwargs )
参数
- vocab_size (
int, 可选, 默认为 33201) — UDOP 模型的词汇表大小。定义了可以通过调用 UdopForConditionalGeneration 时传递的inputs_ids表示的不同标记的数量。 - d_model (
int, optional, 默认为 1024) — 编码器层和池化层的大小。 - d_kv (
int, 可选, 默认为 64) — 每个注意力头的键、查询、值投影的大小。投影层的inner_dim将被定义为num_heads * d_kv. - d_ff (
int, optional, 默认为 4096) — 每个UdopBlock中中间前馈层的大小. - num_layers (
int, optional, 默认为 24) — Transformer 编码器和解码器中的隐藏层数。 - num_decoder_layers (
int, optional) — Transformer解码器中的隐藏层数。如果未设置,将使用与num_layers相同的值。 - num_heads (
int, optional, defaults to 16) — Transformer编码器和解码器中每个注意力层的注意力头数。 - relative_attention_num_buckets (
int, 可选, 默认为 32) — 用于每个注意力层的桶的数量。 - relative_attention_max_distance (
int, optional, 默认为 128) — 用于桶分离的较长序列的最大距离。 - relative_bias_args (
List[dict], 可选, 默认为[{'type' -- '1d'}, {'type': 'horizontal'}, {'type': 'vertical'}]): 一个包含相对偏差层参数的字典列表。 - dropout_rate (
float, optional, defaults to 0.1) — 所有 dropout 层的比率。 - layer_norm_epsilon (
float, optional, defaults to 1e-06) — 层归一化层使用的epsilon值。 - initializer_factor (
float, 可选, 默认为 1.0) — 用于初始化所有权重矩阵的因子(应保持为1,内部用于初始化测试)。 - feed_forward_proj (
string, 可选, 默认为"relu") — 使用的前馈层类型。应为"relu"或"gated-gelu"之一。Udopv1.1 使用"gated-gelu"前馈投影。原始 Udop 使用"relu". - is_encoder_decoder (
bool, optional, defaults toTrue) — 模型是否应该表现为编码器/解码器。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 - pad_token_id (
int, optional, defaults to 0) — 词汇表中填充标记的id. - eos_token_id (
int, optional, defaults to 1) — 词汇表中序列结束标记的id. - max_2d_position_embeddings (
int, optional, 默认为 1024) — 用于相对位置编码的最大绝对位置嵌入。 - image_size (
int, optional, 默认为 224) — 输入图像的大小。 - patch_size (
int, optional, defaults to 16) — 视觉编码器使用的补丁大小。 - num_channels (
int, optional, defaults to 3) — 输入图像中的通道数。
这是用于存储UdopForConditionalGeneration配置的配置类。它用于根据指定的参数实例化一个UDOP模型,定义模型架构。使用默认值实例化配置将产生与UDOP microsoft/udop-large架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
UdopTokenizer
类 transformers.UdopTokenizer
< source >( vocab_file eos_token = '' unk_token = '
参数
- vocab_file (
str) — 词汇表文件的路径。 - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.在使用特殊标记构建序列时,这不是用于序列结束的标记。 使用的标记是
sep_token。 - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - sep_token (
str, 可选, 默认为"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - sep_token_box (
List[int], 可选, 默认为[1000, 1000, 1000, 1000]) — 用于特殊 [SEP] 令牌的边界框。 - pad_token_box (
List[int], optional, defaults to[0, 0, 0, 0]) — 用于特殊 [PAD] 令牌的边界框。 - pad_token_label (
int, optional, 默认为 -100) — 用于填充标签的标签。默认为 -100,这是 PyTorch 的 CrossEntropyLoss 的ignore_index。 - only_label_first_subword (
bool, optional, defaults toTrue) — 是否仅标记第一个子词,在提供单词标签的情况下。 - additional_special_tokens (
List[str], 可选, 默认为[") — 分词器使用的额外特殊标记。NOTUSED", "NOTUSED"] - sp_model_kwargs (
dict, optional) — Will be passed to theSentencePieceProcessor.__init__()method. The Python wrapper for SentencePiece can be used, among other things, to set:-
enable_sampling: 启用子词正则化。 -
nbest_size: 用于unigram的采样参数。对于BPE-Dropout无效。nbest_size = {0,1}: No sampling is performed.nbest_size > 1: samples from the nbest_size results.nbest_size < 0: assuming that nbest_size is infinite and samples from the all hypothesis (lattice) using forward-filtering-and-backward-sampling algorithm.
-
alpha: 用于单字采样的平滑参数,以及BPE-dropout的合并操作丢弃概率。
-
- legacy (
bool, 可选, 默认为True) — 是否应使用分词器的legacy行为。Legacy 是在合并 #24622 之前的行为, 该合并包括修复以正确处理出现在特殊标记之后的标记。一个简单的例子:legacy=True:
改编自 LayoutXLMTokenizer 和 T5Tokenizer。基于 SentencePiece。
此分词器继承自PreTrainedTokenizer,其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
build_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。序列的格式如下:
- 单个序列:
X - 序列对:
A B
get_special_tokens_mask
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None already_has_special_tokens: bool = False ) → List[int]
从没有添加特殊标记的标记列表中检索序列ID。当使用标记器的prepare_for_model方法添加特殊标记时,会调用此方法。
create_token_type_ids_from_sequences
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
从传递给序列对分类任务的两个序列中创建一个掩码。T5不使用标记类型ID,因此返回一个零列表。
UdopTokenizerFast
类 transformers.UdopTokenizerFast
< source >( vocab_file = None tokenizer_file = None eos_token = '' sep_token = '' unk_token = '
参数
- vocab_file (
str, optional) — 词汇表文件的路径。 - tokenizer_file (
str, optional) — 指向分词器文件的路径。 - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.在使用特殊标记构建序列时,这不是用于序列结束的标记。 使用的标记是
sep_token。 - sep_token (
str, 可选, 默认为"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - unk_token (
str, 可选, 默认为") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - sep_token_box (
List[int], 可选, 默认为[1000, 1000, 1000, 1000]) — 用于特殊 [SEP] 令牌的边界框。 - pad_token_box (
List[int], optional, defaults to[0, 0, 0, 0]) — 用于特殊[PAD]标记的边界框。 - pad_token_label (
int, optional, 默认为 -100) — 用于填充标记的标签。默认为 -100,这是 PyTorch 的 CrossEntropyLoss 的ignore_index。 - only_label_first_subword (
bool, optional, defaults toTrue) — 是否仅标记第一个子词,在提供单词标签的情况下。 - additional_special_tokens (
List[str], 可选, 默认为[") — 分词器使用的额外特殊标记。NOTUSED", "NOTUSED"]
构建一个“快速”的UDOP分词器(基于HuggingFace的tokenizers库)。改编自 LayoutXLMTokenizer 和 T5Tokenizer。基于 BPE。
这个分词器继承自PreTrainedTokenizerFast,其中包含了大部分主要方法。用户应参考这个超类以获取有关这些方法的更多信息。
batch_encode_plus_boxes
< source >( batch_text_or_text_pairs: typing.Union[typing.List[str], typing.List[typing.Tuple[str, str]], typing.List[typing.List[str]]] is_pair: bool = None boxes: typing.Optional[typing.List[typing.List[typing.List[int]]]] = None word_labels: typing.Optional[typing.List[typing.List[int]]] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
对一系列序列或一系列序列对进行标记化处理,并为模型做准备。
此方法已弃用,应改用__call__。
build_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。一个XLM-RoBERTa序列具有以下格式:
- 单一序列:
X - 序列对:
AB
call_boxes
< source >( text: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] text_pair: typing.Union[typing.List[str], typing.List[typing.List[str]], NoneType] = None boxes: typing.Union[typing.List[typing.List[int]], typing.List[typing.List[typing.List[int]]]] = None word_labels: typing.Union[typing.List[int], typing.List[typing.List[int]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → BatchEncoding
参数
- text (
str,List[str],List[List[str]]) — 要编码的序列或序列批次。每个序列可以是一个字符串、一个字符串列表 (单个示例的单词或一批示例的问题)或一个字符串列表的列表(一批 单词)。 - text_pair (
List[str],List[List[str]]) — 要编码的序列或序列批次。每个序列应该是一个字符串列表 (预分词的字符串)。 - boxes (
List[List[int]],List[List[List[int]]]) — 单词级别的边界框。每个边界框应归一化到0-1000的范围内。 - word_labels (
List[int],List[List[int]], optional) — 单词级别的整数标签(用于如FUNSD、CORD等标记分类任务)。 - add_special_tokens (
bool, optional, defaults toTrue) — 是否使用与模型相关的特殊标记对序列进行编码。 - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.如果未设置或设置为
None,则在需要截断/填充参数时,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如XLNet),则截断/填充到最大长度的功能将被停用。 - stride (
int, 可选, 默认为 0) — 如果与max_length一起设置为一个数字,当return_overflowing_tokens=True时返回的溢出标记将包含来自截断序列末尾的一些标记,以提供截断序列和溢出序列之间的一些重叠。此参数的值定义了重叠标记的数量。 - pad_to_multiple_of (
int, 可选) — 如果设置,将序列填充到提供的值的倍数。这对于在计算能力>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
- return_token_type_ids (
bool, optional) — Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_overflowing_tokens (
bool, 可选, 默认为False) — 是否返回溢出的令牌序列。如果提供了一对输入ID序列(或一批对)并且使用了truncation_strategy = longest_first或True,则会引发错误而不是返回溢出的令牌。 - return_special_tokens_mask (
bool, optional, 默认为False) — 是否返回特殊令牌掩码信息。 - return_offsets_mapping (
bool, optional, defaults toFalse) — Whether or not to return(char_start, char_end)for each token.这仅在继承自PreTrainedTokenizerFast的快速分词器上可用,如果使用Python的分词器,此方法将引发
NotImplementedError。 - return_length (
bool, 可选, 默认为False) — 是否返回编码输入的长度。 - verbose (
bool, 可选, 默认为True) — 是否打印更多信息和警告。 - **kwargs — 传递给
self.tokenize()方法
一个 BatchEncoding 包含以下字段:
-
input_ids — 要输入模型的标记ID列表。
-
bbox — 要输入模型的边界框列表。
-
token_type_ids — 要输入模型的标记类型ID列表(当
return_token_type_ids=True或 如果 “token_type_ids” 在self.model_input_names中时)。 -
attention_mask — 指定模型应关注哪些标记的索引列表(当
return_attention_mask=True或如果 “attention_mask” 在self.model_input_names中时)。 -
labels — 要输入模型的标签列表。(当指定了
word_labels时)。 -
overflowing_tokens — 溢出标记序列列表(当指定了
max_length并且return_overflowing_tokens=True时)。 -
num_truncated_tokens — 被截断的标记数量(当指定了
max_length并且return_overflowing_tokens=True时)。 -
special_tokens_mask — 0和1的列表,1表示添加的特殊标记,0表示 常规序列标记(当
add_special_tokens=True并且return_special_tokens_mask=True时)。 -
length — 输入的长度(当
return_length=True时)。
主要方法,用于将一个或多个序列或一个或多个序列对进行分词,并为模型准备,这些序列带有单词级别的归一化边界框和可选的标签。
create_token_type_ids_from_sequences
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
从传递给序列对分类任务的两个序列中创建一个掩码。XLM-RoBERTa不使用标记类型ID,因此返回一个零列表。
encode_boxes
< source >( text: typing.Union[str, typing.List[str], typing.List[int]] text_pair: typing.Union[str, typing.List[str], typing.List[int], NoneType] = None boxes: typing.Optional[typing.List[typing.List[int]]] = None word_labels: typing.Optional[typing.List[typing.List[int]]] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs )
参数
- 将字符串转换为ID序列(整数),使用分词器和词汇表。与执行—
-
self.convert_tokens_to_ids(self.tokenize(text)). — text (str,List[str]orList[int]): The first sequence to be encoded. This can be a string, a list of strings (tokenized string using thetokenizemethod) or a list of integers (tokenized string ids using theconvert_tokens_to_idsmethod). text_pair (str,List[str]orList[int], optional): Optional second sequence to be encoded. This can be a string, a list of strings (tokenized string using thetokenizemethod) or a list of integers (tokenized string ids using theconvert_tokens_to_idsmethod).
encode_plus_boxes
< source >( text: typing.Union[str, typing.List[str]] text_pair: typing.Optional[typing.List[str]] = None boxes: typing.Optional[typing.List[typing.List[int]]] = None word_labels: typing.Optional[typing.List[typing.List[int]]] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
对序列或序列对进行标记化并准备供模型使用。
此方法已弃用,应改用__call__。
UdopProcessor
类 transformers.UdopProcessor
< source >( image_processor tokenizer )
参数
- image_processor (
LayoutLMv3ImageProcessor) — 一个 LayoutLMv3ImageProcessor 的实例。图像处理器是一个必需的输入。 - tokenizer (
UdopTokenizer或UdopTokenizerFast) — UdopTokenizer 或 UdopTokenizerFast 的实例。tokenizer 是一个必需的输入。
构建一个UDOP处理器,将LayoutLMv3图像处理器和UDOP分词器结合成一个单一的处理器。
UdopProcessor 提供了准备模型数据所需的所有功能。
首先使用LayoutLMv3ImageProcessor来调整大小、重新缩放和规范化文档图像,并可选地应用OCR以获取单词和规范化边界框。然后将这些提供给UdopTokenizer或UdopTokenizerFast,它们将单词和边界框转换为标记级别的input_ids、attention_mask、token_type_ids、bbox。可选地,可以提供整数word_labels,这些将被转换为标记级别的labels,用于标记分类任务(如FUNSD、CORD)。
此外,它还支持向分词器传递text_target和text_pair_target,这些可以用于准备语言建模任务的标签。
__call__
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')], NoneType] = None text: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] = None *args audio = None videos = None **kwargs: typing_extensions.Unpack[transformers.models.udop.processing_udop.UdopProcessorKwargs] )
此方法首先将images参数转发给~UdopImageProcessor.__call__。如果UdopImageProcessor初始化时apply_ocr设置为True,它会将获得的单词和边界框与附加参数一起传递给__call__()并返回输出,同时准备好pixel_values。如果UdopImageProcessor初始化时apply_ocr设置为False,它会将用户指定的单词(text/`text_pair)和boxes与附加参数一起传递给__call__()并返回输出,同时准备好pixel_values。
或者,可以传递text_target和text_pair_target来准备UDOP的目标。
请参考上述两个方法的文档字符串以获取更多信息。
UdopModel
类 transformers.UdopModel
< source >( config )
参数
- config (UdopConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的UDOP编码器-解码器Transformer输出原始隐藏状态,没有任何特定的头部。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: Tensor = None attention_mask: Tensor = None bbox: typing.Dict[str, typing.Any] = None pixel_values: typing.Optional[torch.Tensor] = None visual_bbox: typing.Dict[str, typing.Any] = None decoder_input_ids: typing.Optional[torch.Tensor] = None decoder_attention_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None encoder_outputs: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None decoder_inputs_embeds: typing.Optional[torch.Tensor] = None decoder_head_mask: typing.Optional[torch.Tensor] = None cross_attn_head_mask: typing.Optional[torch.Tensor] = None use_cache = True output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.Seq2SeqModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。UDOP 是一个具有相对位置嵌入的模型,因此您应该能够在右侧和左侧填充输入。可以使用 AutoTokenizer 获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。 什么是输入 ID? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示未掩码的标记,
- 0 表示掩码的标记。 什么是注意力掩码?
- bbox (
torch.LongTensorof shape({0}, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner.请注意,
sequence_length = token_sequence_length + patch_sequence_length + 1其中1是用于 [CLS] 标记的。有关patch_sequence_length的信息,请参见pixel_values。 - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 文档图像的批次。每张图像被分割成形状为(num_channels, config.patch_size, config.patch_size)的补丁,补丁的总数 (=patch_sequence_length) 等于((height / config.patch_size) * (width / config.patch_size)). - visual_bbox (
torch.LongTensorof shape(batch_size, patch_sequence_length, 4), optional) — 图像中每个补丁的边界框。如果未提供,则在模型中创建边界框。 - decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are decoder input IDs? T5 uses thepad_token_idas the starting token fordecoder_input_idsgeneration. Ifpast_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values). To know more on how to preparedecoder_input_idsfor pretraining take a look at T5 Training. - decoder_attention_mask (
torch.BoolTensorof shape(batch_size, target_sequence_length), 可选) — 默认行为:生成一个忽略decoder_input_ids中填充标记的张量。默认情况下也会使用因果掩码。 - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于在编码器中屏蔽自注意力模块中选定的头。在[0, 1]中选择的掩码值:- 1 表示头 未被屏蔽,
- 0 表示头 被屏蔽.
- decoder_head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于在解码器中屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- cross_attn_head_mask (
torch.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于在解码器中取消选择交叉注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被掩码,
- 0 表示头部被掩码.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), 可选) — 元组由 (last_hidden_state,可选: hidden_states,可选: attentions) 组成last_hidden_state的形状为(batch_size, sequence_length, hidden_size)是编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力中。 - past_key_values (
tuple(tuple(torch.FloatTensor))长度为config.n_layers,每个元组包含4个形状为(batch_size, num_heads, sequence_length - 1, embed_size_per_head)的张量) — 包含预计算的注意力块的关键和值隐藏状态。可用于加速解码。 如果使用了past_key_values,用户可以选择仅输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去的关键值状态提供给此模型的),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix. Ifdecoder_input_idsanddecoder_inputs_embedsare both unset,decoder_inputs_embedstakes the value ofinputs_embeds. - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。它用于在正确的位置更新缓存并推断完整的序列长度。
返回
transformers.modeling_outputs.Seq2SeqModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.Seq2SeqModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(UdopConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型解码器最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量和 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
decoder_hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。解码器每层输出的隐藏状态加上可选的初始嵌入输出。
-
decoder_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
-
encoder_last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 模型编码器最后一层输出的隐藏状态序列。 -
encoder_hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。编码器每层输出的隐藏状态加上可选的初始嵌入输出。
-
encoder_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
UdopModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, AutoModel
>>> from datasets import load_dataset
>>> import torch
>>> # load model and processor
>>> # in this case, we already have performed OCR ourselves
>>> # so we initialize the processor with `apply_ocr=False`
>>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
>>> model = AutoModel.from_pretrained("microsoft/udop-large")
>>> # load an example image, along with the words and coordinates
>>> # which were extracted using an OCR engine
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> image = example["image"]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> inputs = processor(image, words, boxes=boxes, return_tensors="pt")
>>> decoder_input_ids = torch.tensor([[model.config.decoder_start_token_id]])
>>> # forward pass
>>> outputs = model(**inputs, decoder_input_ids=decoder_input_ids)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 1, 1024]UdopForConditionalGeneration
类 transformers.UdopForConditionalGeneration
< source >( config )
参数
- config (UdopConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
UDOP编码器-解码器Transformer,顶部带有语言建模头,能够在给定文档图像和可选提示的情况下生成文本。
这个类基于T5ForConditionalGeneration,扩展用于处理图像和布局(2D)数据。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法 (如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: Tensor = None attention_mask: Tensor = None bbox: typing.Dict[str, typing.Any] = None pixel_values: typing.Optional[torch.Tensor] = None visual_bbox: typing.Dict[str, typing.Any] = None decoder_input_ids: typing.Optional[torch.Tensor] = None decoder_attention_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None encoder_outputs: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None decoder_inputs_embeds: typing.Optional[torch.Tensor] = None decoder_head_mask: typing.Optional[torch.Tensor] = None cross_attn_head_mask: typing.Optional[torch.Tensor] = None use_cache = True output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None cache_position: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.Seq2SeqLMOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。UDOP 是一个具有相对位置嵌入的模型,因此您应该能够在右侧和左侧填充输入。可以使用 AutoTokenizer 获取索引。详情请参见 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。 什么是输入 ID? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — 用于避免在填充标记索引上执行注意力机制的掩码。掩码值在[0, 1]中选择:- 1 表示未掩码的标记,
- 0 表示掩码的标记。 什么是注意力掩码?
- bbox (
torch.LongTensorof shape({0}, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner.请注意,
sequence_length = token_sequence_length + patch_sequence_length + 1其中1是用于 [CLS] 标记的。有关patch_sequence_length的信息,请参见pixel_values。 - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 文档图像的批次。每张图像被分割成形状为(num_channels, config.patch_size, config.patch_size)的补丁,补丁的总数 (=patch_sequence_length) 等于((height / config.patch_size) * (width / config.patch_size)). - visual_bbox (
torch.LongTensorof shape(batch_size, patch_sequence_length, 4), optional) — 图像中每个补丁的边界框。如果未提供,则在模型中创建边界框。 - decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are decoder input IDs? T5 uses thepad_token_idas the starting token fordecoder_input_idsgeneration. Ifpast_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values). To know more on how to preparedecoder_input_idsfor pretraining take a look at T5 Training. - decoder_attention_mask (
torch.BoolTensorof shape(batch_size, target_sequence_length), 可选) — 默认行为:生成一个忽略decoder_input_ids中填充标记的张量。默认情况下也会使用因果掩码。 - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于在编码器中屏蔽自注意力模块中选定的头。屏蔽值在[0, 1]中选择:- 1 表示头 未被屏蔽,
- 0 表示头 被屏蔽.
- decoder_head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于在解码器中屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- cross_attn_head_mask (
torch.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — 用于在解码器中取消选择交叉注意力模块的特定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被掩码,
- 0 表示头部被掩码.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), 可选的) — 元组由 (last_hidden_state,可选的: hidden_states,可选的: attentions) 组成last_hidden_state的形状为(batch_size, sequence_length, hidden_size)是编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力中。 - past_key_values (
tuple(tuple(torch.FloatTensor))长度为config.n_layers,每个元组包含4个形状为(batch_size, num_heads, sequence_length - 1, embed_size_per_head)的张量) — 包含预计算的注意力块的关键和值隐藏状态。可用于加速解码。 如果使用了past_key_values,用户可以选择仅输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去的关键值状态提供给此模型的),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix. Ifdecoder_input_idsanddecoder_inputs_embedsare both unset,decoder_inputs_embedstakes the value ofinputs_embeds. - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。它用于在正确的位置更新缓存并推断完整的序列长度。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size - 1]范围内。所有设置为-100的标签将被忽略(屏蔽),损失仅针对[0, ..., config.vocab_size]范围内的标签计算。
返回
transformers.modeling_outputs.Seq2SeqLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.Seq2SeqLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(UdopConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量和 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
decoder_hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。解码器在每层输出处的隐藏状态加上初始嵌入输出。
-
decoder_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
-
encoder_last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size),可选) — 模型编码器最后一层输出的隐藏状态序列。 -
encoder_hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。编码器在每层输出处的隐藏状态加上初始嵌入输出。
-
encoder_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
UdopForConditionalGeneration 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, UdopForConditionalGeneration
>>> from datasets import load_dataset
>>> # load model and processor
>>> # in this case, we already have performed OCR ourselves
>>> # so we initialize the processor with `apply_ocr=False`
>>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
>>> model = UdopForConditionalGeneration.from_pretrained("microsoft/udop-large")
>>> # load an example image, along with the words and coordinates
>>> # which were extracted using an OCR engine
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> image = example["image"]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> # one can use the various task prefixes (prompts) used during pre-training
>>> # e.g. the task prefix for DocVQA is "Question answering. "
>>> question = "Question answering. What is the date on the form?"
>>> encoding = processor(image, question, text_pair=words, boxes=boxes, return_tensors="pt")
>>> # autoregressive generation
>>> predicted_ids = model.generate(**encoding)
>>> print(processor.batch_decode(predicted_ids, skip_special_tokens=True)[0])
9/30/92UdopEncoderModel
类 transformers.UdopEncoderModel
< source >( config: UdopConfig )
参数
- config (UdopConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸UDOP模型转换器输出编码器的原始隐藏状态,没有任何特定的头部。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: Tensor = None bbox: typing.Dict[str, typing.Any] = None attention_mask: Tensor = None pixel_values: typing.Optional[torch.Tensor] = None visual_bbox: typing.Dict[str, typing.Any] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.udop.modeling_udop.BaseModelOutputWithAttentionMask 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. T5 is a model with relative position embeddings so you should be able to pad the inputs on both the right and the left.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
要了解更多关于如何为预训练准备
input_ids的信息,请查看T5 Training. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- bbox (
torch.LongTensorof shape({0}, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner.请注意,
sequence_length = token_sequence_length + patch_sequence_length + 1其中1是用于 [CLS] 标记的。有关patch_sequence_length的信息,请参见pixel_values。 - pixel_values (
torch.FloatTensor形状为(batch_size, num_channels, height, width)) — 文档图像的批次。每张图像被分割成形状为(num_channels, config.patch_size, config.patch_size)的补丁,补丁的总数 (=patch_sequence_length) 等于((height / config.patch_size) * (width / config.patch_size)). - visual_bbox (
torch.LongTensorof shape(batch_size, patch_sequence_length, 4), optional) — 图像中每个补丁的边界框。如果未提供,则在模型中创建边界框。 - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.models.udop.modeling_udop.BaseModelOutputWithAttentionMask 或 tuple(torch.FloatTensor)
一个 transformers.models.udop.modeling_udop.BaseModelOutputWithAttentionMask 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置(UdopConfig)和输入的各种元素。
- last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 - past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或 - 当
config.use_cache=True) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True,则还包含 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块中的键和值,并且如果config.is_encoder_decoder=True,则还包含交叉注意力块中的键和值),可用于(参见past_key_values输入)加速顺序解码。 - hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或 - 当
config.output_hidden_states=True) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型每层输出的隐藏状态加上可选的初始嵌入输出。 - attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当 config.output_attentions=True): 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。- cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True和 config.add_cross_attention=True或当config.output_attentions=True) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
UdopEncoderModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, UdopEncoderModel
>>> from huggingface_hub import hf_hub_download
>>> from datasets import load_dataset
>>> # load model and processor
>>> # in this case, we already have performed OCR ourselves
>>> # so we initialize the processor with `apply_ocr=False`
>>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
>>> model = UdopEncoderModel.from_pretrained("microsoft/udop-large")
>>> # load an example image, along with the words and coordinates
>>> # which were extracted using an OCR engine
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train", trust_remote_code=True)
>>> example = dataset[0]
>>> image = example["image"]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = processor(image, words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state