MGP-STR
概述
MGP-STR模型由Peng Wang、Cheng Da和Cong Yao在Multi-Granularity Prediction for Scene Text Recognition中提出。MGP-STR是一个概念上简单但强大的视觉场景文本识别(STR)模型,它基于Vision Transformer (ViT)构建。为了整合语言知识,提出了多粒度预测(MGP)策略,以隐式方式将语言模态的信息注入模型中。
论文的摘要如下:
场景文本识别(STR)多年来一直是计算机视觉领域的一个活跃研究课题。为了解决这一具有挑战性的问题,许多创新方法相继被提出,并且将语言知识融入STR模型最近成为一个显著趋势。在这项工作中,我们首先从视觉Transformer(ViT)的最新进展中汲取灵感,构建了一个概念上简单但功能强大的视觉STR模型,该模型基于ViT,并且在场景文本识别方面优于之前的最先进模型,包括纯视觉模型和语言增强方法。为了整合语言知识,我们进一步提出了一种多粒度预测策略,以隐式方式将语言模态的信息注入模型,即在输出空间中引入NLP中广泛使用的子词表示(BPE和WordPiece),除了传统的字符级表示外,而不采用独立的语言模型(LM)。由此产生的算法(称为MGP-STR)能够将STR的性能推向更高的水平。具体来说,它在标准基准测试中实现了93.35%的平均识别准确率。
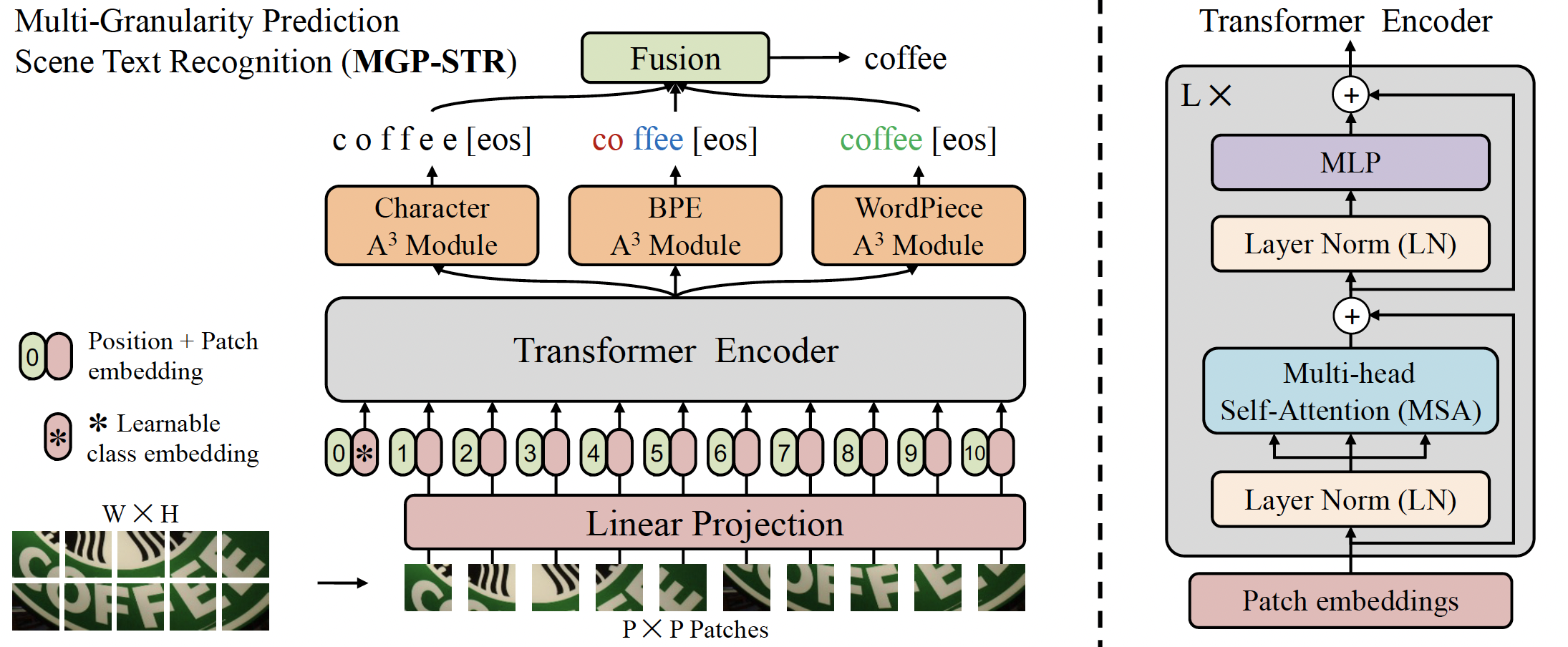 MGP-STR architecture. Taken from the original paper.
MGP-STR architecture. Taken from the original paper. MGP-STR 在两个合成数据集 MJSynth (MJ) 和 SynthText (ST) 上进行了训练,没有在其他数据集上进行微调。它在六个标准的拉丁场景文本基准测试中取得了最先进的结果,包括3个常规文本数据集(IC13, SVT, IIIT)和3个不规则文本数据集(IC15, SVTP, CUTE)。 该模型由 yuekun 贡献。原始代码可以在 这里 找到。
推理示例
MgpstrModel 接受图像作为输入,并生成三种类型的预测,这些预测代表了不同粒度的文本信息。 这三种类型的预测被融合以给出最终的预测结果。
ViTImageProcessor 类负责预处理输入图像,而 MgpstrTokenizer 将生成的字符标记解码为目标字符串。 MgpstrProcessor 将 ViTImageProcessor 和 MgpstrTokenizer 封装到一个实例中,以便同时提取输入特征并解码预测的标记ID。
- 逐步光学字符识别(OCR)
>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
>>> import requests
>>> from PIL import Image
>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(pixel_values)
>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']MgpstrConfig
类 transformers.MgpstrConfig
< source >( image_size = [32, 128] patch_size = 4 num_channels = 3 max_token_length = 27 num_character_labels = 38 num_bpe_labels = 50257 num_wordpiece_labels = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 mlp_ratio = 4.0 qkv_bias = True distilled = False layer_norm_eps = 1e-05 drop_rate = 0.0 attn_drop_rate = 0.0 drop_path_rate = 0.0 output_a3_attentions = False initializer_range = 0.02 **kwargs )
参数
- image_size (
List[int], 可选, 默认为[32, 128]) — 每张图像的尺寸(分辨率)。 - patch_size (
int, optional, defaults to 4) — 每个补丁的大小(分辨率)。 - num_channels (
int, optional, 默认为 3) — 输入通道的数量。 - max_token_length (
int, optional, 默认为 27) — 输出的最大令牌数。 - num_character_labels (
int, optional, 默认为 38) — 字符头的类别数量. - num_bpe_labels (
int, optional, 默认为 50257) — bpe 头的类别数量. - num_wordpiece_labels (
int, optional, defaults to 30522) — wordpiece头的类别数量. - hidden_size (
int, optional, 默认为 768) — 嵌入维度. - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - mlp_ratio (
float, optional, defaults to 4.0) — mlp隐藏维度与嵌入维度的比率。 - qkv_bias (
bool, optional, defaults toTrue) — 是否向查询、键和值添加偏置。 - distilled (
bool, 可选, 默认为False) — 模型包含蒸馏令牌和头部,如DeiT模型中的设计。 - layer_norm_eps (
float, optional, defaults to 1e-05) — 层归一化层使用的epsilon值。 - drop_rate (
float, optional, defaults to 0.0) — 嵌入层和编码器中所有全连接层的丢弃概率。 - attn_drop_rate (
float, optional, 默认为 0.0) — 注意力概率的丢弃比例。 - drop_path_rate (
float, optional, 默认为 0.0) — 随机深度率。 - output_a3_attentions (
bool, 可选, 默认为False) — 模型是否应返回A^3模块的注意力。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。
这是用于存储MgpstrModel配置的配置类。它用于根据指定的参数实例化一个MGP-STR模型,定义模型架构。使用默认值实例化配置将产生与MGP-STR alibaba-damo/mgp-str-base架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import MgpstrConfig, MgpstrForSceneTextRecognition
>>> # Initializing a Mgpstr mgp-str-base style configuration
>>> configuration = MgpstrConfig()
>>> # Initializing a model (with random weights) from the mgp-str-base style configuration
>>> model = MgpstrForSceneTextRecognition(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configMgpstrTokenizer
类 transformers.MgpstrTokenizer
< source >( vocab_file unk_token = '[GO]' bos_token = '[GO]' eos_token = '[s]' pad_token = '[GO]' **kwargs )
参数
- vocab_file (
str) — 词汇表文件的路径。 - unk_token (
str, optional, defaults to"[GO]") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为该标记。 - bos_token (
str, optional, defaults to"[GO]") — 序列的开始标记。 - eos_token (
str, optional, defaults to"[s]") — 序列结束标记。 - pad_token (
str或tokenizers.AddedToken, 可选, 默认为"[GO]") — 用于使令牌数组在批处理时大小相同的特殊令牌。然后将被注意力机制或损失计算忽略。
构建一个MGP-STR字符分词器。
此分词器继承自PreTrainedTokenizer,其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
MgpstrProcessor
类 transformers.MgpstrProcessor
< source >( image_processor = 无 tokenizer = 无 **kwargs )
参数
- image_processor (
ViTImageProcessor, 可选) —ViTImageProcessor的一个实例。图像处理器是一个必需的输入。 - tokenizer (MgpstrTokenizer, optional) — 分词器是一个必需的输入。
构建一个MGP-STR处理器,它将图像处理器和MGP-STR分词器封装成一个整体
MgpstrProcessor 提供了 ViTImageProcessor 和 MgpstrTokenizer 的所有功能。更多信息请参见
call() 和 batch_decode()。
在正常模式下使用时,此方法会将其所有参数转发给ViTImageProcessor的
call() 并返回其输出。如果 text 不是 None,此方法还会将 text 和 kwargs
参数转发给MgpstrTokenizer的 call() 以编码文本。请
参考上述方法的文档字符串以获取更多信息。
batch_decode
< source >( sequences ) → Dict[str, any]
通过调用decode将token id的列表列表转换为字符串列表。
此方法将其所有参数转发给PreTrainedTokenizer的batch_decode()。请参考该方法的文档字符串以获取更多信息。
MgpstrModel
类 transformers.MgpstrModel
< source >( 配置: MgpstrConfig )
参数
- config (MgpstrConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的MGP-STR模型转换器输出原始隐藏状态,没有任何特定的头部。 这个模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有事项。
前进
< source >( pixel_values: FloatTensor output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见ViTImageProcessor.call()。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
MgpstrModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
MgpstrForSceneTextRecognition
类 transformers.MgpstrForSceneTextRecognition
< source >( 配置: MgpstrConfig )
参数
- config (MgpstrConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
MGP-STR模型变压器,顶部有三个分类头(三个A^3模块和三个线性层位于变压器编码器输出之上),用于场景文本识别(STR)。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor output_attentions: typing.Optional[bool] = None output_a3_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见ViTImageProcessor.call()。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - output_a3_attentions (
bool, 可选) — 是否返回a3模块的注意力张量。有关更多详细信息,请参见返回张量下的a3_attentions。
返回
transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,取决于配置(
-
logits (
tuple(torch.FloatTensor)形状为(batch_size, config.num_character_labels)) — 由torch.FloatTensor组成的元组(一个用于字符输出的形状为(batch_size, config.max_token_length, config.num_character_labels),+ 一个用于 bpe 输出的形状为(batch_size, config.max_token_length, config.num_bpe_labels),+ 一个用于 wordpiece 输出的形状为(batch_size, config.max_token_length, config.num_wordpiece_labels))。字符、bpe 和 wordpiece 的分类分数(在 SoftMax 之前)。
-
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, config.max_token_length, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
a3_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_a3_attentions=True或当config.output_a3_attentions=True时返回) — 由torch.FloatTensor组成的元组(一个用于字符的注意力,+ 一个用于 bpe 的注意力, + 一个用于 wordpiece 的注意力)形状为(batch_size, config.max_token_length, sequence_length)`。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
MgpstrForSceneTextRecognition 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import (
... MgpstrProcessor,
... MgpstrForSceneTextRecognition,
... )
>>> import requests
>>> from PIL import Image
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> processor = MgpstrProcessor.from_pretrained("alibaba-damo/mgp-str-base")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> model = MgpstrForSceneTextRecognition.from_pretrained("alibaba-damo/mgp-str-base")
>>> # inference
>>> outputs = model(pixel_values)
>>> out_strs = processor.batch_decode(outputs.logits)
>>> out_strs["generated_text"]
'["ticket"]'