TVLT
该模型目前处于维护模式,我们不接受任何更改其代码的新PR。
如果您在运行此模型时遇到任何问题,请重新安装支持此模型的最后一个版本:v4.40.2。
您可以通过运行以下命令来执行此操作:pip install -U transformers==4.40.2。
概述
TVLT模型由Zineng Tang、Jaemin Cho、Yixin Nie、Mohit Bansal(前三位作者贡献相同)在TVLT: Textless Vision-Language Transformer中提出。Textless Vision-Language Transformer (TVLT) 是一种使用原始视觉和音频输入进行视觉与语言表示学习的模型,不使用诸如分词或自动语音识别(ASR)等文本特定模块。它可以执行各种视听和视觉语言任务,如检索、问答等。
论文的摘要如下:
在这项工作中,我们提出了无文本视觉-语言变换器(TVLT),其中同质的变换器块接收原始的视觉和音频输入,用于视觉和语言表示学习,具有最少的模态特定设计,并且不使用文本特定模块,如分词或自动语音识别(ASR)。TVLT通过重建连续视频帧和音频频谱图的掩码补丁(掩码自编码)和对齐视频和音频的对比建模进行训练。TVLT在各种多模态任务上,如视觉问答、图像检索、视频检索和多模态情感分析,达到了与基于文本的对应模型相当的性能,推理速度快28倍,参数仅为1/3。我们的研究结果表明,可以从低层次的视觉和音频信号中学习紧凑且高效的视觉-语言表示,而无需假设文本的先验存在。
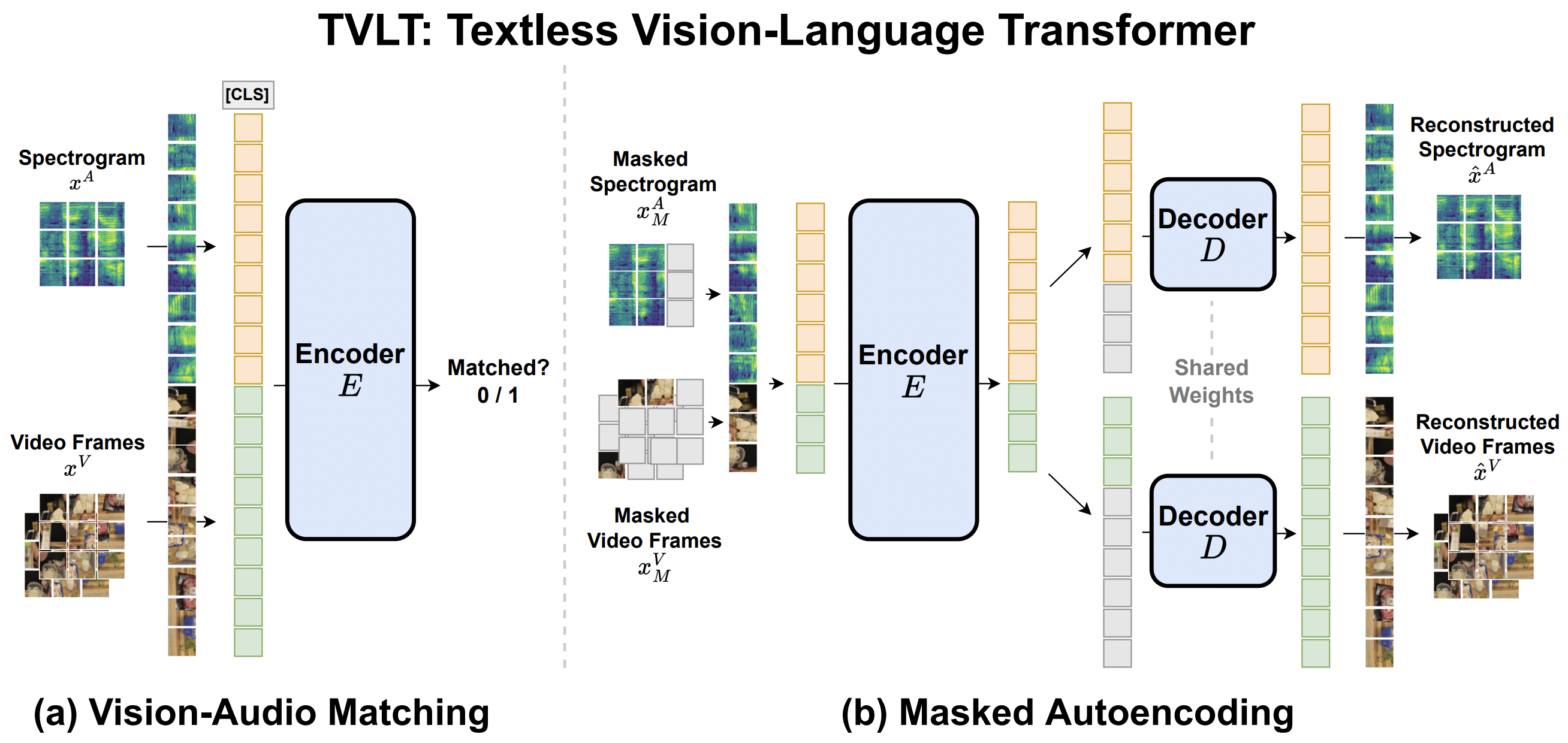
原始代码可以在这里找到。该模型由Zineng Tang贡献。
使用提示
- TVLT 是一个同时接受
pixel_values和audio_values作为输入的模型。可以使用 TvltProcessor 来为模型准备数据。 该处理器将图像处理器(用于图像/视频模态)和音频特征提取器(用于音频模态)封装在一起。 - TVLT 使用各种大小的图像/视频和音频进行训练:作者将输入图像/视频调整为224并进行裁剪,并将音频频谱图的长度限制为2048。为了使视频和音频的批处理成为可能,作者使用了一个
pixel_mask来指示哪些像素是真实的/填充的,以及一个audio_mask来指示哪些音频值是真实的/填充的。 - TVLT的设计与标准的视觉Transformer(ViT)和掩码自编码器(MAE)非常相似,如ViTMAE所示。不同之处在于该模型包含了音频模态的嵌入层。
- 此模型的PyTorch版本仅在torch 1.10及更高版本中可用。
TvltConfig
类 transformers.TvltConfig
< source >( image_size = 224 spectrogram_length = 2048 frequency_length = 128 image_patch_size = [16, 16] audio_patch_size = [16, 16] num_image_channels = 3 num_audio_channels = 1 num_frames = 8 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-06 qkv_bias = True use_mean_pooling = False decoder_num_attention_heads = 16 decoder_hidden_size = 512 decoder_num_hidden_layers = 8 decoder_intermediate_size = 2048 pixel_mask_ratio = 0.75 audio_mask_ratio = 0.15 audio_mask_type = 'frame-level' task_matching = True task_mae = True loss_type = 'classification' **kwargs )
参数
- image_size (
int, optional, 默认为 224) — 每张图片的大小(分辨率)。 - spectrogram_length (
int, optional, defaults to 2048) — 每个音频频谱图的时间长度。 - frequency_length (
int, optional, 默认为 128) — 音频频谱图的频率长度。 - image_patch_size (
List[int], 可选, 默认为[16, 16]) — 每个图像块的大小(分辨率)。 - audio_patch_size (
List[int], optional, defaults to[16, 16]) — 每个音频补丁的大小(分辨率)。 - num_image_channels (
int, optional, defaults to 3) — 输入图像通道的数量。 - num_audio_channels (
int, optional, 默认为 1) — 输入音频通道的数量。 - num_frames (
int, 可选, 默认为 8) — 输入视频的最大帧数。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, defaults to 12) — Transformer编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - hidden_dropout_prob (
float, optional, 默认为 0.0) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, defaults to 0.0) — 注意力概率的丢弃比率。 - initializer_range (
float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-06) — 层归一化层使用的epsilon值。 - qkv_bias (
bool, optional, defaults toTrue) — 是否在查询、键和值中添加偏置。 - use_mean_pooling (
bool, 可选, 默认为False) — 是否对最终的隐藏状态进行平均池化,而不是使用[CLS]标记的最终隐藏状态。 - decoder_num_attention_heads (
int, optional, defaults to 16) — 解码器中每个注意力层的注意力头数量。 - decoder_hidden_size (
int, optional, defaults to 512) — 解码器的维度。 - decoder_num_hidden_layers (
int, optional, defaults to 8) — 解码器中的隐藏层数量。 - decoder_intermediate_size (
int, optional, defaults to 2048) — 解码器中“中间”(即前馈)层的维度。 - pixel_mask_ratio (
float, optional, defaults to 0.75) — 图像补丁的掩码比例. - audio_mask_ratio (
float, optional, 默认为 0.15) — 音频补丁掩码比例. - audio_mask_type (
str, optional, defaults to"frame-level") — 音频补丁掩码类型,选择“帧级”和“补丁级”。 - task_matching (
bool, optional, defaults toTrue) — 是否在预训练中使用视觉音频匹配任务。 - task_mae (
bool, optional, defaults toTrue) — 是否在预训练中使用掩码自编码器(MAE)。 - loss_type (
str, optional, defaults to"classification") — 损失类型包括回归和分类。
这是用于存储TvltModel配置的配置类。它用于根据指定的参数实例化TVLT模型,定义模型架构。使用默认值实例化配置将产生类似于TVLT ZinengTang/tvlt-base架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import TvltConfig, TvltModel
>>> # # Initializing a TVLT ZinengTang/tvlt-base style configuration
>>> configuration = TvltConfig()
>>> # # Initializing a model (with random weights) from the ZinengTang/tvlt-base style configuration
>>> model = TvltModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTvltProcessor
类 transformers.TvltProcessor
< source >( image_processor feature_extractor )
参数
- image_processor (
TvltImageProcessor) — 一个 TvltImageProcessor 的实例。图像处理器是一个必需的输入。 - feature_extractor (
TvltFeatureExtractor) — 一个 TvltFeatureExtractor 的实例。特征提取器是一个必需的输入。
构建一个TVLT处理器,它将TVLT图像处理器和TVLT特征提取器封装到一个单一的处理器中。
TvltProcessor 提供了 TvltImageProcessor 和 TvltFeatureExtractor 的所有功能。更多信息请参见 call() 的文档字符串。
__call__
< source >( images = 无 audio = 无 images_mixed = 无 sampling_rate = 无 mask_audio = 假 mask_pixel = 假 *args **kwargs )
将images参数转发到TvltImageProcessor的preprocess(),并将audio参数转发到TvltFeatureExtractor的call()。请参考上述两个方法的文档字符串以获取更多信息。
TvltImageProcessor
类 transformers.TvltImageProcessor
< source >( do_resize: bool = True size: typing.Dict[str, int] = None patch_size: typing.List[int] = [16, 16] num_frames: int = 8 resample: Resampling =
参数
- do_resize (
bool, 可选, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中通过do_resize参数覆盖此设置。 - size (
Dict[str, int]optional, defaults to{"shortest_edge" -- 224}): 调整大小后输出图像的尺寸。图像的短边将被调整为size["shortest_edge"],同时保持原始图像的宽高比。可以在preprocess方法中通过size覆盖此设置。 - patch_size (
List[int]optional, defaults to [16,16]) — 图像块嵌入的块大小。 - num_frames (
intoptional, 默认为 8) — 视频帧的最大数量。 - resample (
PILImageResampling, 可选, 默认为PILImageResampling.BILINEAR) — 如果调整图像大小,则使用的重采样过滤器。可以在preprocess方法中通过resample参数覆盖。 - do_center_crop (
bool, 可选, 默认为True) — 是否将图像中心裁剪到指定的crop_size。可以通过preprocess方法中的do_center_crop参数进行覆盖。 - crop_size (
Dict[str, int], 可选, 默认为{"height" -- 224, "width": 224}): 应用中心裁剪后的图像大小。可以在preprocess方法中通过crop_size参数覆盖。 - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess方法中通过do_rescale参数覆盖此设置。 - rescale_factor (
int或float, 可选, 默认为 1/255) — 定义在重新缩放图像时使用的比例因子。可以在preprocess方法中通过rescale_factor参数覆盖此值。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_std参数进行覆盖。
构建一个TVLT图像处理器。
此处理器可用于通过将图像转换为1帧视频来为模型准备视频或图像。
预处理
< source >( videos: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_resize: bool = None size: typing.Dict[str, int] = None patch_size: typing.List[int] = None num_frames: int = None resample: Resampling = None do_center_crop: bool = None crop_size: typing.Dict[str, int] = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None is_mixed: bool = False return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension =
参数
- 视频 (
ImageInput) — 要预处理的图像或视频。期望输入单个或一批帧,像素值范围为0到255。如果传入的帧像素值在0到1之间,请设置do_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], optional, defaults toself.size) — 应用调整大小后的图像尺寸。 - patch_size (
List[int]optional, 默认为 self.patch_size) — 图像块嵌入的块大小。 - num_frames (
intoptional, 默认为 self.num_frames) — 视频帧的最大数量. - resample (
PILImageResampling, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是枚举PILImageResampling中的一个,只有在do_resize设置为True时才会生效。 - do_center_crop (
bool, optional, defaults toself.do_centre_crop) — 是否对图像进行中心裁剪. - crop_size (
Dict[str, int], optional, defaults toself.crop_size) — 应用中心裁剪后图像的大小。 - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值重新缩放到 [0 - 1] 之间。 - rescale_factor (
float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_normalize (
bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化处理. - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 图像均值. - image_std (
floatorList[float], optional, defaults toself.image_std) — 图像标准差. - is_mixed (
bool, optional) — 如果输入视频包含负样本。 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的推断通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
返回
一个包含以下字段的BatchFeature:
-
pixel_values — 输入模型的像素值,形状为 (batch_size, num_channels, height, width)。
-
pixel_mask — 输入模型的像素掩码,形状为 (batch_size, num_pixel_patches)。
-
pixel_values_mixed — 输入模型的包含正负值的像素值,形状为 (batch_size, num_channels, height, width)。
-
pixel_mask_mixed — 输入模型的包含正负值的像素掩码,形状为 (batch_size, num_pixel_patches)。
预处理视频或图像或一批视频或图像。
TvltFeatureExtractor
类 transformers.TvltFeatureExtractor
< source >( spectrogram_length = 2048 num_channels = 1 patch_size = [16, 16] feature_size = 128 sampling_rate = 44100 hop_length_to_sampling_rate = 86 n_fft = 2048 padding_value = 0.0 **kwargs )
参数
- spectrogram_length (
Dict[str, int]optional, 默认为 2048) — 每个音频频谱图的时间长度。 - num_channels (
intoptional, 默认为 1) — 音频通道的数量。 - patch_size (
List[int]可选, 默认为[16, 16]) — 音频补丁嵌入的补丁大小。 - feature_size (
int, optional, defaults to 128) — 音频频谱图的频率长度。 - sampling_rate (
int, optional, defaults to 44100) — 音频文件应被数字化的采样率,以赫兹(Hz)表示。 - hop_length_to_sampling_rate (
int, optional, 默认为 86) — Hop length 是用于获取梅尔频率系数的短时傅里叶变换(STFT)的重叠窗口的长度。 例如,采样率为 44100 时,hop length 为 512,44100 / 512 = 86 - n_fft (
int, optional, 默认为 2048) — 傅里叶变换的大小. - padding_value (
float, 可选, 默认值为 0.0) — 用于填充音频的填充值。应对应于静音部分。
构建一个TVLT音频特征提取器。该特征提取器可用于为模型准备音频。
此特征提取器继承自FeatureExtractionMixin,其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
__call__
< source >( raw_speech: typing.Union[numpy.ndarray, typing.List[float], typing.List[numpy.ndarray], typing.List[typing.List[float]]] return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_attention_mask: typing.Optional[bool] = True sampling_rate: typing.Optional[int] = None resample: bool = False mask_audio: bool = False **kwargs ) → BatchFeature
参数
- raw_speech (
np.ndarray,List[float],List[np.ndarray,List[List[float]]) — 要填充的序列或序列批次。每个序列可以是一个numpy数组、一个浮点值列表、一个numpy数组列表或一个浮点值列表的列表。必须是单声道音频,而不是立体声,即每个时间步长只有一个浮点数。 - return_tensors (
stror TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'pt': 返回PyTorchtorch.Tensor对象。'np': 返回Numpynp.ndarray对象。
- return_attention_mask (
bool, optional, default toTrue) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific feature_extractor’s default. What are attention masks?对于TvltTransformer模型,
attention_mask应始终在批量推理时传递,以避免细微的错误。 - sampling_rate (
int, optional) —raw_speech输入被采样的采样率。强烈建议在调用时传递sampling_rate以防止静默错误并允许自动语音识别 管道。当前模型支持16000和44100的采样率。 - resample (
bool, 可选, 默认为False) — 如果采样率不匹配,重新采样输入音频以匹配。 - mask_audio (
bool, optional, defaults toFalse) — 是否对MAE任务的输入音频进行掩码处理。
返回
一个 BatchFeature 包含以下字段:
-
audio_values — 要输入模型的音频值,形状为 (batch_size, num_channels, height, width)。
-
audio_mask — 要输入模型的音频掩码,形状为 (batch_size, num_audio_patches)。
为模型准备一个或多个音频的主要方法。
TvltModel
类 transformers.TvltModel
< source >( config )
参数
- config (TvltConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的TVLT模型转换器输出原始隐藏状态,没有任何特定的头部。 该模型是一个PyTorch torch.nn.Module子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有事项。
前进
< source >( pixel_values: FloatTensor audio_values: FloatTensor pixel_mask: typing.Optional[torch.FloatTensor] = None audio_mask: typing.Optional[torch.FloatTensor] = None mask_pixel: bool = False mask_audio: bool = False output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.deprecated.tvlt.modeling_tvlt.TvltModelOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - audio_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 音频值。音频值可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - pixel_mask (
torch.FloatTensorof shape(batch_size, num_pixel_patches)) — 像素掩码。像素掩码可以使用 TvltProcessor 获取。详情请参见 TvltProcessor.call()。 - audio_mask (
torch.FloatTensorof shape(batch_size, num_audio_patches)) — 音频掩码。音频掩码可以使用TvltProcessor获得。详情请参见TvltProcessor.call()。 - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 在Tvlt视觉-音频匹配中混合正负样本的像素值。混合的像素值可以使用TvltProcessor获得。详情请参见TvltProcessor.call(). - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — pixel_values_mixed 的像素掩码。可以使用 TvltProcessor 获取混合的像素掩码。详情请参见 TvltProcessor.call(). - mask_pixel (
bool, optional) — 是否在MAE任务中屏蔽像素。仅在TvltForPreTraining中设置为True。 - mask_audio (
bool, optional) — 是否在MAE任务中屏蔽音频。仅在TvltForPreTraining中设置为True。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.models.deprecated.tvlt.modeling_tvlt.TvltModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.deprecated.tvlt.modeling_tvlt.TvltModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(TvltConfig)和输入。
- last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 - last_pixel_hidden_state (
torch.FloatTensor形状为(batch_size, pixel_sequence_length, hidden_size)) — 模型最后一层输出的像素隐藏状态序列。 - last_audio_hidden_state (
torch.FloatTensor形状为(batch_size, audio_sequence_length, hidden_size)) — 模型最后一层输出的音频隐藏状态序列。 - pixel_label_masks (
torch.FloatTensor形状为(batch_size, pixel_patch_length)) — 指示哪些像素补丁被掩码(1)和哪些未被掩码(0)的张量。 - audio_label_masks (
torch.FloatTensor形状为(batch_size, audio_patch_length)) — 指示哪些音频补丁被掩码(1)和哪些未被掩码(0)的张量。 - pixel_ids_restore (
torch.LongTensor形状为(batch_size, pixel_patch_length)) — 包含像素掩码的ID排列的张量。 - audio_ids_restore (
torch.LongTensor形状为(batch_size, audio_patch_length)) — 包含音频掩码的ID排列的张量。 - hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入输出,一个用于每层输出)形状为(batch_size, sequence_length, hidden_size)。模型每层输出的隐藏状态加上初始嵌入输出。 - attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
TvltModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import TvltProcessor, TvltModel
>>> import numpy as np
>>> import torch
>>> num_frames = 8
>>> images = list(np.random.randn(num_frames, 3, 224, 224))
>>> audio = list(np.random.randn(10000))
>>> processor = TvltProcessor.from_pretrained("ZinengTang/tvlt-base")
>>> model = TvltModel.from_pretrained("ZinengTang/tvlt-base")
>>> input_dict = processor(images, audio, sampling_rate=44100, return_tensors="pt")
>>> outputs = model(**input_dict)
>>> loss = outputs.lossTvltForPreTraining
类 transformers.TvltForPreTraining
< source >( config )
参数
- config (TvltConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
TVLT模型变压器,顶部带有解码器,用于自监督预训练。 该模型是PyTorch torch.nn.Module的子类。将其 作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor audio_values: FloatTensor pixel_mask: typing.Optional[torch.FloatTensor] = None audio_mask: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None pixel_values_mixed: typing.Optional[torch.FloatTensor] = None pixel_mask_mixed: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.deprecated.tvlt.modeling_tvlt.TvltForPreTrainingOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - audio_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 音频值。音频值可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - pixel_mask (
torch.FloatTensorof shape(batch_size, num_pixel_patches)) — 像素掩码。像素掩码可以使用TvltProcessor获得。详情请参见TvltProcessor.call()。 - audio_mask (
torch.FloatTensorof shape(batch_size, num_audio_patches)) — 音频掩码。音频掩码可以使用TvltProcessor获得。详情请参见TvltProcessor.call()。 - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 在Tvlt视觉-音频匹配中混合正负样本的像素值。混合的像素值可以使用TvltProcessor获得。详情请参见TvltProcessor.call(). - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — pixel_values_mixed 的像素掩码。可以使用 TvltProcessor 获取混合的像素掩码。详情请参见 TvltProcessor.call(). - mask_pixel (
bool, optional) — 是否在MAE任务中屏蔽像素。仅在TvltForPreTraining中设置为True。 - mask_audio (
bool, optional) — 是否在MAE任务中屏蔽音频。仅在TvltForPreTraining中设置为True。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 在Tvlt视觉-音频匹配中混合正负样本的像素值。音频值可以使用TvltProcessor获取。详情请参见TvltProcessor.call(). - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — pixel_values_mixed 的像素掩码。可以使用 TvltProcessor 获取混合的像素值。详情请参见 TvltProcessor.call(). - labels (
torch.LongTensorof shape(batch_size, num_labels), optional) — 用于计算视觉音频匹配损失的标签。索引应在[0, 1]范围内。num_labels 必须为 1。
返回
transformers.models.deprecated.tvlt.modeling_tvlt.TvltForPreTrainingOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.deprecated.tvlt.modeling_tvlt.TvltForPreTrainingOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(TvltConfig)和输入。
- loss (
torch.FloatTensor形状为(1,)) — 像素重建损失。 - matching_logits (
torch.FloatTensor形状为(batch_size, 1)) — 匹配目标 logits。 - pixel_logits (
torch.FloatTensor形状为(batch_size, pixel_patch_length, image_patch_size ** 3 * pixel_num_channels)): 像素重建 logits。 - audio_logits (
torch.FloatTensor形状为(batch_size, audio_patch_length, image_patch_size[0] * image_patch_size[1])): 音频重建 logits。 - hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入的输出,一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态 加上初始嵌入输出。 - attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算 自注意力头中的加权平均值。
TvltForPreTraining 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import TvltProcessor, TvltForPreTraining
>>> import numpy as np
>>> import torch
>>> num_frames = 8
>>> images = list(np.random.randn(num_frames, 3, 224, 224))
>>> images_mixed = list(np.random.randn(num_frames, 3, 224, 224))
>>> audio = list(np.random.randn(10000))
>>> processor = TvltProcessor.from_pretrained("ZinengTang/tvlt-base")
>>> model = TvltForPreTraining.from_pretrained("ZinengTang/tvlt-base")
>>> input_dict = processor(
... images, audio, images_mixed, sampling_rate=44100, mask_pixel=True, mask_audio=True, return_tensors="pt"
... )
>>> outputs = model(**input_dict)
>>> loss = outputs.lossTvltForAudioVisualClassification
类 transformers.TvltForAudioVisualClassification
< source >( config )
参数
- config (TvltConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Tvlt 模型转换器,顶部带有分类器头(在 [CLS] 标记的最终隐藏状态之上的 MLP),用于视听分类任务,例如 CMU-MOSEI 情感分析和音频到视频检索。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor audio_values: FloatTensor pixel_mask: typing.Optional[torch.FloatTensor] = None audio_mask: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 像素值。像素值可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - audio_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 音频值。音频值可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - pixel_mask (
torch.FloatTensorof shape(batch_size, num_pixel_patches)) — 像素掩码。像素掩码可以使用TvltProcessor获取。详情请参见TvltProcessor.call()。 - audio_mask (
torch.FloatTensorof shape(batch_size, num_audio_patches)) — 音频掩码。音频掩码可以使用TvltProcessor获得。详情请参见TvltProcessor.call()。 - pixel_values_mixed (
torch.FloatTensorof shape(batch_size, num_frames, num_channels, height, width)) — 在Tvlt视觉-音频匹配中混合正负样本的像素值。混合的像素值可以使用TvltProcessor获得。详情请参见TvltProcessor.call(). - pixel_mask_mixed (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — pixel_values_mixed 的像素掩码。可以使用 TvltProcessor 获取混合的像素掩码。详情请参见 TvltProcessor.call(). - mask_pixel (
bool, optional) — 是否在MAE任务中屏蔽像素。仅在TvltForPreTraining中设置为True。 - mask_audio (
bool, optional) — 是否在MAE任务中屏蔽音频。仅在TvltForPreTraining中设置为True。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, num_labels), optional) — 用于计算视听损失的标签。索引应在[0, ..., num_classes-1]范围内,其中 num_classes 指的是视听任务中的类别数量。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(TvltConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TvltForAudioVisualClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import TvltProcessor, TvltForAudioVisualClassification
>>> import numpy as np
>>> import torch
>>> num_frames = 8
>>> images = list(np.random.randn(num_frames, 3, 224, 224))
>>> audio = list(np.random.randn(10000))
>>> processor = TvltProcessor.from_pretrained("ZinengTang/tvlt-base")
>>> model = TvltForAudioVisualClassification.from_pretrained("ZinengTang/tvlt-base")
>>> input_dict = processor(images, audio, sampling_rate=44100, return_tensors="pt")
>>> outputs = model(**input_dict)
>>> loss = outputs.loss