存储和依赖的最佳实践#
本文档包含为在 Kubernetes 上部署 Ray 设置存储和处理应用程序依赖项的建议。
当你在 Kubernetes 上设置 Ray 时,KubeRay 文档 提供了如何配置操作员以执行和管理 Ray 集群生命周期的概述。然而,作为管理员,你可能仍然对实际用户工作流程有疑问。例如:
如何在 Ray 集群上部署或运行代码?
你应该为工件设置哪种类型的存储系统?
你如何处理应用程序的包依赖关系?
这些问题的答案在开发和生产环境中有所不同。下表总结了每种情况下的推荐设置:
交互式开发 |
生产 |
|
|---|---|---|
集群配置 |
KubeRay YAML |
KubeRay YAML |
代码 |
在头节点上运行驱动程序或Jupyter笔记本 |
将代码构建到 Docker 镜像中 |
工件存储 |
设置一个 EFS |
设置一个 EFS |
包依赖 |
安装到 NFS |
烘焙到 Docker 镜像中 |
表1:开发和生产推荐设置的比较表。
交互式开发#
为了为数据科学家和机器学习从业者提供一个交互式的开发环境,我们建议以减少开发者上下文切换和缩短迭代时间的方式设置代码、存储和依赖项。
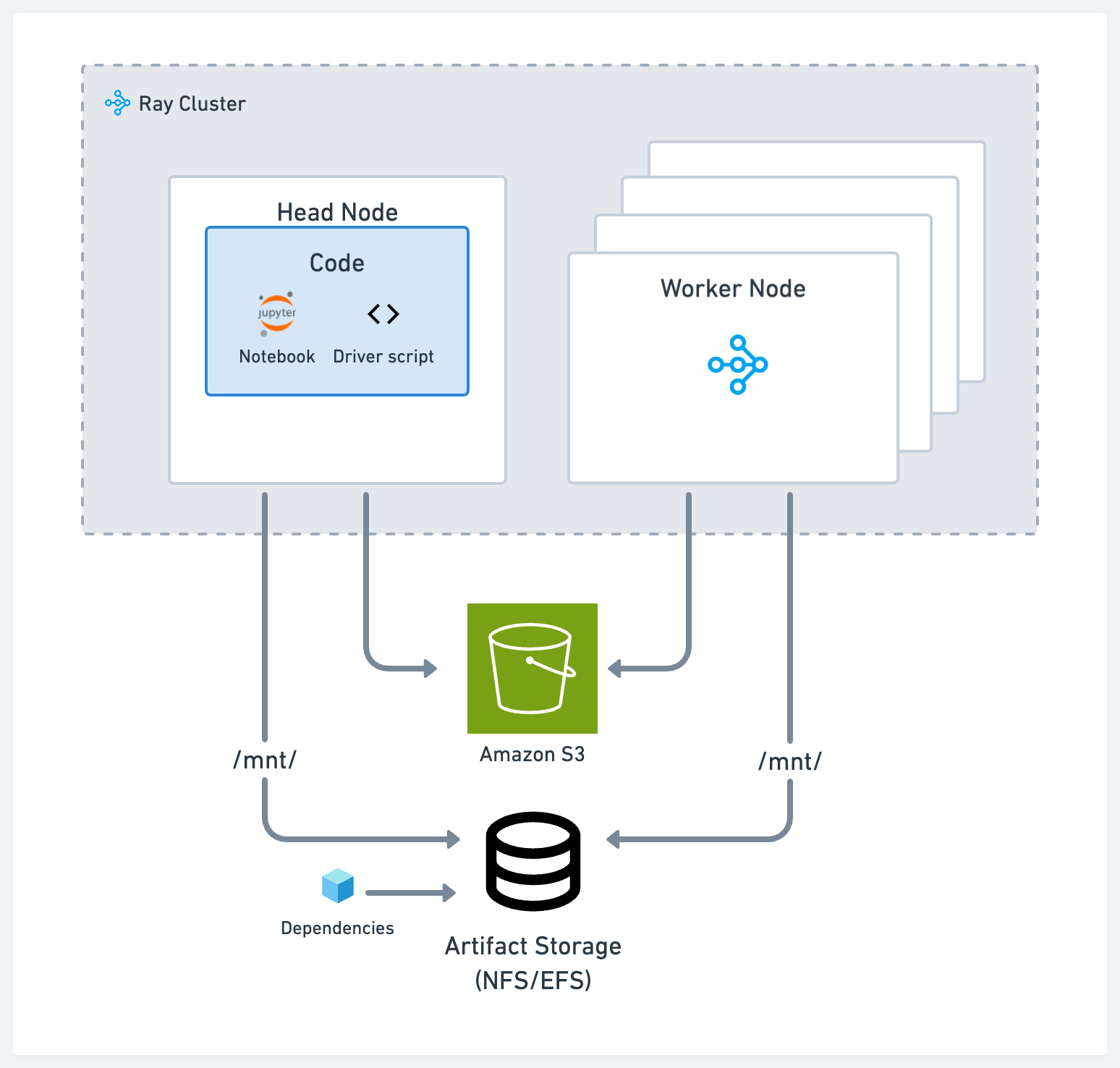
存储#
根据您的使用情况,在开发过程中使用以下两种标准解决方案之一来存储工件和日志:
符合POSIX标准的网络文件存储,如网络文件系统(NFS)和弹性文件服务(EFS):当你希望在不同节点之间以低延迟访问工件或依赖项时,这种方法非常有用。例如,在不同Ray任务上训练的不同模型的实验日志。
云存储,如AWS简单存储服务(S3)或GCP谷歌存储(GS):这种方法对于需要高吞吐量访问的大型工件或数据集非常有用。
Ray 的 AI 库,如 Ray Data、Ray Train 和 Ray Tune,自带了开箱即用的功能,可以从云存储和本地或网络存储中读取和写入数据。
驱动脚本#
在集群的头节点上运行主脚本或驱动脚本。Ray Core和库程序通常假设驱动程序在头节点上,并利用本地存储。例如,Ray Tune默认在头节点上生成日志文件。
一个典型的流程可能如下所示:
在头节点上启动Jupyter服务器
通过SSH登录到主节点并在那里运行驱动脚本或应用程序
使用 Ray 作业提交客户端将代码从本地机器提交到集群
依赖项#
对于本地依赖,例如,如果你在一个单一代码库中工作,或者外部依赖,比如一个 pip 包,使用以下选项之一:
将代码和安装包放到你的NFS上。这样做的好处是,你可以快速与代码库的其余部分和依赖项进行交互,而无需每次都在集群中传输。
使用 运行时环境 与 Ray 作业提交客户端,它可以从 S3 拉取代码或将代码从本地工作目录发送到远程集群。
将远程和本地依赖项烘焙到所有节点使用的已发布 Docker 镜像中。请参阅 自定义 Docker 镜像。这种方法是将应用程序部署到 Kubernetes 的最常见方式,但它也是摩擦最大的选项。
生产#
生产环境的建议与标准的Kubernetes最佳实践一致。请参见下图中的配置:
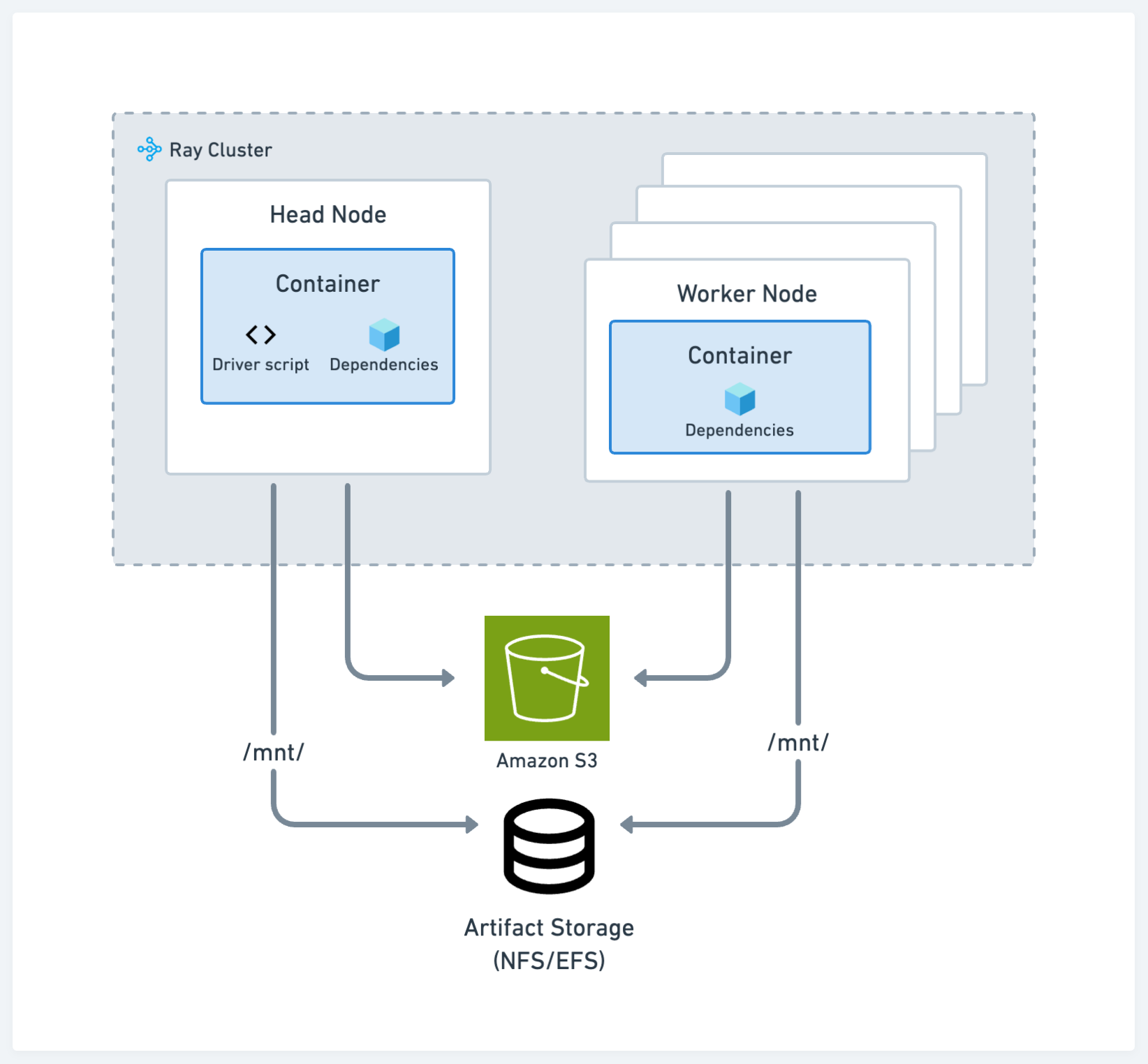
存储#
存储系统在开发和生产环境中的选择保持一致。
代码和依赖项#
将您的代码、远程和本地依赖项烘焙到发布到集群中所有节点的 Docker 镜像中。这种方法是将应用程序部署到 Kubernetes 的最常见方式。请参阅 自定义 Docker 镜像。
使用云存储和 runtime env 是一种不太推荐的方法,因为它可能不如容器路径那样可重复,但仍然是可行的。在这种情况下,使用运行时环境选项从云存储下载包含代码和其他私有模块的zip文件,此外还需要指定运行应用程序所需的pip包。
