首次用户提示#
Ray 提供了一个高度灵活、同时又极简且易于使用的 API。在本页中,我们描述了几种技巧,这些技巧可以帮助 Ray 的初次使用者避免一些常见的错误,这些错误可能会显著影响其程序的性能。如需深入了解高级设计模式,请阅读 核心设计模式。
API |
描述 |
|---|---|
|
初始化 Ray 上下文。 |
|
指定函数将被修饰的函数或类装饰器
作为任务执行或在不同的进程中作为类执行。
|
|
在每个远程函数、远程类声明或
调用远程类方法。
远程操作是异步的。
|
|
将对象存储在对象存储中,并返回其ID。
此ID可用于将对象作为参数传递
到任何远程函数或方法调用。
这是一个同步操作。
|
|
从对象ID返回一个对象或对象列表
或对象ID列表。
这是一个同步(即,阻塞)操作。
|
|
从一个对象ID列表中返回
(1)已准备好的对象的ID列表,以及
(2) the list of IDs of the objects that are not ready yet.
默认情况下,它一次返回一个准备好的对象ID。
|
本页报告的所有结果均在一台配备2.7 GHz Core i7 CPU和16GB内存的13英寸MacBook Pro上获得。虽然``ray.init()``在单机运行时会自动检测核心数量,但为了减少您在运行以下代码时观察到的结果的变异性,这里我们指定num_cpus = 4,即一台拥有4个CPU的机器。
由于每个任务默认请求一个CPU,此设置允许我们最多并行执行四个任务。因此,我们的Ray系统由一个执行程序的驱动程序和最多四个运行远程任务或角色的工作程序组成。
提示 1: 延迟 ray.get()#
使用 Ray,每个远程操作(例如,任务、actor 方法)的调用都是异步的。这意味着操作会立即返回一个承诺/未来,这本质上是一个操作结果的标识符(ID)。这是实现并行性的关键,因为它允许驱动程序并行启动多个操作。要获取实际结果,程序员需要在结果的 ID 上调用 ray.get()。此调用会阻塞,直到结果可用。作为副作用,此操作还会阻止驱动程序调用其他操作,这可能会损害并行性。
不幸的是,新 Ray 用户无意中使用 ray.get() 是很自然的。为了说明这一点,考虑以下简单的 Python 代码,它调用了 do_some_work() 函数四次,每次调用大约需要 1 秒:
import ray
import time
def do_some_work(x):
time.sleep(1) # Replace this with work you need to do.
return x
start = time.time()
results = [do_some_work(x) for x in range(4)]
print("duration =", time.time() - start)
print("results =", results)
程序执行的输出如下。如预期,程序大约需要4秒:
duration = 4.0149290561676025
results = [0, 1, 2, 3]
现在,让我们用 Ray 并行化上面的程序。一些初次使用的用户会通过将函数设为远程来实现这一点,即,
import time
import ray
ray.init(num_cpus=4) # Specify this system has 4 CPUs.
@ray.remote
def do_some_work(x):
time.sleep(1) # Replace this with work you need to do.
return x
start = time.time()
results = [do_some_work.remote(x) for x in range(4)]
print("duration =", time.time() - start)
print("results =", results)
然而,在执行上述程序时,会得到:
duration = 0.0003619194030761719
results = [ObjectRef(df5a1a828c9685d3ffffffff0100000001000000), ObjectRef(cb230a572350ff44ffffffff0100000001000000), ObjectRef(7bbd90284b71e599ffffffff0100000001000000), ObjectRef(bd37d2621480fc7dffffffff0100000001000000)]
查看此输出时,有两点显而易见。首先,程序立即完成,即在不到1毫秒的时间内完成。其次,我们得到的不是预期的结果(即 [0, 1, 2, 3]),而是一堆标识符。回想一下,远程操作是异步的,它们返回的是未来对象(即对象ID),而不是结果本身。这正是我们在这里看到的。我们只测量调用任务所需的时间,而不是它们的运行时间,并且我们得到了对应于四个任务的结果ID。
要获取实际结果,我们需要使用 ray.get(),这里的第一反应是直接在远程操作调用上使用 ray.get(),即,将第12行替换为:
results = [ray.get(do_some_work.remote(x)) for x in range(4)]
在此更改后重新运行程序,我们得到:
duration = 4.018050909042358
results = [0, 1, 2, 3]
所以现在结果是正确的,但它仍然需要4秒,所以没有加速!这是怎么回事?细心的读者可能已经知道答案了:ray.get() 是阻塞的,因此在每次远程操作后调用它意味着我们要等待该操作完成,这实际上意味着我们一次只执行一个操作,因此没有并行性!
要启用并行性,我们需要在调用所有任务后调用 ray.get()。我们可以在示例中通过将第12行替换为以下内容来轻松实现:
results = ray.get([do_some_work.remote(x) for x in range(4)])
在此更改后重新运行程序,我们现在得到:
duration = 1.0064549446105957
results = [0, 1, 2, 3]
最终,成功了!我们的 Ray 程序现在只需 1 秒即可运行,这意味着所有 do_some_work() 的调用都在并行运行。
总之,始终记住 ray.get() 是一个阻塞操作,因此如果过早调用它可能会损害并行性。相反,你应该尝试编写程序,使得 ray.get() 尽可能晚地被调用。
提示 2:避免微小任务#
当一个初次开发的开发者想要使用 Ray 并行化他们的代码时,自然的本能是让每一个函数或类都变成远程的。不幸的是,这可能会导致不良后果;如果任务非常小,Ray 程序可能会比等效的 Python 程序花费更长的时间。
让我们再次考虑上述示例,但这次我们将任务大大缩短(即每个任务仅需要0.1毫秒),并将任务调用次数大幅增加到100,000次。
import time
def tiny_work(x):
time.sleep(0.0001) # Replace this with work you need to do.
return x
start = time.time()
results = [tiny_work(x) for x in range(100000)]
print("duration =", time.time() - start)
通过运行这个程序,我们得到:
duration = 13.36544418334961
由于执行100,000个每个耗时0.1毫秒的任务的下限是10秒,再加上其他开销如函数调用等,这个结果是可以预期的。
现在让我们使用 Ray 并行化这段代码,通过使每一次对 tiny_work() 的调用变为远程调用:
import time
import ray
@ray.remote
def tiny_work(x):
time.sleep(0.0001) # Replace this with work you need to do.
return x
start = time.time()
result_ids = [tiny_work.remote(x) for x in range(100000)]
results = ray.get(result_ids)
print("duration =", time.time() - start)
运行此代码的结果是:
duration = 27.46447515487671
令人惊讶的是,Ray不仅没有改善执行时间,而且Ray程序实际上比顺序程序还要慢!这是怎么回事?问题在于,每次任务调用都有不小的开销(例如,调度、进程间通信、更新系统状态),这些开销主导了执行任务的实际时间。
加速此程序的一种方法是增加远程任务的规模,以分摊调用开销。以下是一个可能的解决方案,我们将1000次 tiny_work() 函数调用聚合到一个更大的远程函数中:
import time
import ray
def tiny_work(x):
time.sleep(0.0001) # replace this is with work you need to do
return x
@ray.remote
def mega_work(start, end):
return [tiny_work(x) for x in range(start, end)]
start = time.time()
result_ids = []
[result_ids.append(mega_work.remote(x*1000, (x+1)*1000)) for x in range(100)]
results = ray.get(result_ids)
print("duration =", time.time() - start)
现在,如果我们运行上述程序,我们会得到:
duration = 3.2539820671081543
这大约是顺序执行的四分之一,符合我们的预期(回想一下,我们可以并行运行四个任务)。当然,自然的问题是任务要多大才能分摊远程调用开销。找到这一点的一种方法是运行以下简单程序来估计每个任务的调用开销:
@ray.remote
def no_work(x):
return x
start = time.time()
num_calls = 1000
[ray.get(no_work.remote(x)) for x in range(num_calls)]
print("per task overhead (ms) =", (time.time() - start)*1000/num_calls)
在2018年的MacBook Pro笔记本上运行上述程序显示:
per task overhead (ms) = 0.4739549160003662
换句话说,执行一个空任务几乎需要半毫秒。这表明我们需要确保一个任务至少需要几毫秒来分摊调用开销。一个需要注意的是,每个任务的开销会因机器而异,并且在同一台机器上运行的任务与远程运行的任务之间也会有所不同。尽管如此,确保任务至少需要几毫秒是一个在开发Ray程序时的好经验法则。
提示 3:避免将同一对象重复传递给远程任务#
当我们把一个大对象作为参数传递给一个远程函数时,Ray 会在幕后调用 ray.put() 将该对象存储在本地对象存储中。当远程任务在本地执行时,这可以显著提高远程任务调用的性能,因为所有本地任务共享对象存储。
然而,在某些情况下,自动在任务调用时调用 ray.put() 会导致性能问题。一个例子是重复传递相同的大对象作为参数,如下面的程序所示:
import time
import numpy as np
import ray
@ray.remote
def no_work(a):
return
start = time.time()
a = np.zeros((5000, 5000))
result_ids = [no_work.remote(a) for x in range(10)]
results = ray.get(result_ids)
print("duration =", time.time() - start)
该程序输出:
duration = 1.0837509632110596
这个运行时间对于一个只调用10个不做任何事情的远程任务的程序来说相当大。造成这种意外高运行时间的原因是,每次我们调用 no_work(a) 时,Ray 都会调用 ray.put(a),这会导致将数组 a 复制到对象存储中。由于数组 a 有250万个条目,复制它需要相当长的时间。
为了避免每次调用 no_work() 时都复制数组 a,一个简单的解决方案是显式调用 ray.put(a),然后将 a 的 ID 传递给 no_work(),如下所示:
import time
import numpy as np
import ray
ray.init(num_cpus=4)
@ray.remote
def no_work(a):
return
start = time.time()
a_id = ray.put(np.zeros((5000, 5000)))
result_ids = [no_work.remote(a_id) for x in range(10)]
results = ray.get(result_ids)
print("duration =", time.time() - start)
运行此程序只需:
duration = 0.132796049118042
这比原始程序快了7倍,这是可以预见的,因为调用 no_work(a) 的主要开销是将数组 a 复制到对象存储中,现在这种情况只发生一次。
避免将同一对象的多个副本存储到对象存储中,一个更重要的优势是它可以防止对象存储过早填满,从而避免对象驱逐的成本。
提示 4:管道数据处理#
如果我们对多个任务的结果使用 ray.get(),我们将不得不等到这些任务中的最后一个完成。如果任务所需的时间差异很大,这可能会成为一个问题。
为了说明这个问题,考虑以下例子,我们在并行中运行四个 do_some_work() 任务,每个任务所需时间均匀分布在0到4秒之间。接下来,假设这些任务的结果由 process_results() 处理,每个结果需要1秒。预期的运行时间是(1)执行最慢的 do_some_work() 任务所需的时间,加上(2)4秒,这是执行 process_results() 所需的时间。
import time
import random
import ray
@ray.remote
def do_some_work(x):
time.sleep(random.uniform(0, 4)) # Replace this with work you need to do.
return x
def process_results(results):
sum = 0
for x in results:
time.sleep(1) # Replace this with some processing code.
sum += x
return sum
start = time.time()
data_list = ray.get([do_some_work.remote(x) for x in range(4)])
sum = process_results(data_list)
print("duration =", time.time() - start, "\nresult = ", sum)
程序的输出显示,运行时间接近8秒:
duration = 7.82636022567749
result = 6
当其他任务可能早已完成时,等待最后一个任务完成会不必要地增加程序运行时间。更好的解决方案是数据一可用就进行处理。幸运的是,Ray 允许你通过在对象 ID 列表上调用 ray.wait() 来实现这一点。如果不指定任何其他参数,此函数会在其参数列表中的对象准备好时立即返回。此调用有两个返回值:(1) 准备好的对象的 ID,以及 (2) 包含尚未准备好的对象的 ID 的列表。修改后的程序如下。请注意,我们需要做的一个更改是将 process_results() 替换为 process_incremental(),后者一次处理一个结果。
import time
import random
import ray
@ray.remote
def do_some_work(x):
time.sleep(random.uniform(0, 4)) # Replace this with work you need to do.
return x
def process_incremental(sum, result):
time.sleep(1) # Replace this with some processing code.
return sum + result
start = time.time()
result_ids = [do_some_work.remote(x) for x in range(4)]
sum = 0
while len(result_ids):
done_id, result_ids = ray.wait(result_ids)
sum = process_incremental(sum, ray.get(done_id[0]))
print("duration =", time.time() - start, "\nresult = ", sum)
这个程序现在只需要大约4.8秒,这是一个显著的改进:
duration = 4.852453231811523
result = 6
为了帮助理解,图1展示了两种情况下的执行时间线:使用 ray.get() 等待所有结果可用后再进行处理,以及使用 ray.wait() 在结果一可用时就立即开始处理。
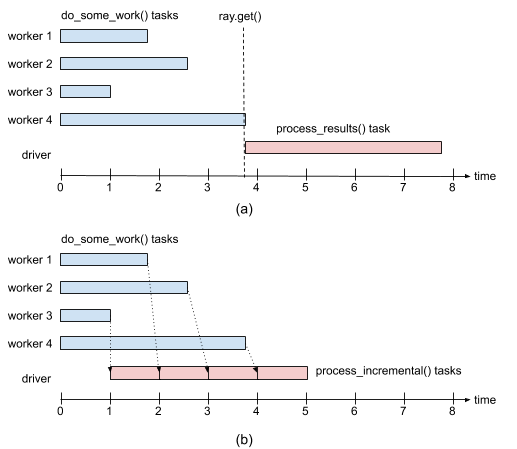
图1:(a) 使用 ray.get() 等待所有 do_some_work() 任务的结果后再调用 process_results() 的执行时间线。(b) 使用 ray.wait() 在结果一可用时就处理结果的执行时间线。#