备注
Ray 2.10.0 引入了 RLlib 的“新 API 栈”的 alpha 阶段。Ray 团队计划将算法、示例脚本和文档迁移到新的代码库中,从而在 Ray 3.0 之前的后续小版本中逐步替换“旧 API 栈”(例如,ModelV2、Policy、RolloutWorker)。
然而,请注意,到目前为止,只有 PPO(单代理和多代理)和 SAC(仅单代理)支持“新 API 堆栈”,并且默认情况下继续使用旧 API 运行。您可以继续使用现有的自定义(旧堆栈)类。
请参阅此处 以获取有关如何使用新API堆栈的更多详细信息。
使用离线数据#
入门#
RLlib 的离线数据集 API 支持处理从离线存储(例如,磁盘、云存储、流系统、HDFS)读取的经验。例如,您可能希望读取从前一次训练运行中保存的经验,或从部署在 网页应用 中的策略收集的经验。您还可以记录在线训练期间生成的新代理经验以供将来使用。
RLlib 使用 SampleBatch 对象来表示轨迹序列(即 (s, a, r, s', ...) 元组)。使用批处理格式可以有效地编码和压缩经验。在在线训练期间,RLlib 使用 策略评估 参与者,通过当前策略并行生成经验批处理。RLlib 还使用相同的批处理格式来读取和写入离线存储的经验。
示例:基于先前保存的经验进行训练#
备注
对于自定义模型和环境,您需要使用 Python API。
在这个例子中,我们将在线训练期间生成的经验批量保存到磁盘,然后利用这些保存的数据使用DQN进行离线策略训练。首先,我们运行一个简单的策略梯度算法,进行10万步,并使用 "output": "/tmp/cartpole-out" 告诉RLlib将模拟输出写入 /tmp/cartpole-out 目录。
$ rllib train \
--run=PG \
--env=CartPole-v1 \
--config='{"output": "/tmp/cartpole-out", "output_max_file_size": 5000000}' \
--stop='{"timesteps_total": 100000}'
经验将被保存为压缩的 JSON 批处理格式:
$ ls -l /tmp/cartpole-out
total 11636
-rw-rw-r-- 1 eric eric 5022257 output-2019-01-01_15-58-57_worker-0_0.json
-rw-rw-r-- 1 eric eric 5002416 output-2019-01-01_15-59-22_worker-0_1.json
-rw-rw-r-- 1 eric eric 1881666 output-2019-01-01_15-59-47_worker-0_2.json
然后,我们可以告诉DQN使用这些先前生成的经验进行训练,使用 "input": "/tmp/cartpole-out"。我们禁用探索,因为它对输入没有影响:
$ rllib train \
--run=DQN \
--env=CartPole-v1 \
--config='{
"input": "/tmp/cartpole-out",
"explore": false}'
离策略估计 (OPE)#
在实践中,当使用离线数据进行训练时,通常不像在线强化学习那样直接使用模拟器来评估训练好的策略。例如,在推荐系统中,如果在现实环境中部署基于离线数据训练的策略,可能会因为策略次优而危及业务。对于这种情况,我们可以使用 off-policy estimation 方法,这些方法避免了在现实环境中评估可能次优策略的风险。
使用RLlib的评估框架,您可以:
在模拟环境中评估策略(如果可用),使用
evaluation_config["input"] = "sampler"。然后,您可以在策略训练过程中通过使用tensorboard --logdir=~/ray_results在tensorboard上监控策略的性能。使用 RLlib 的离策略估计方法,这些方法估计策略在单独的离线数据集上的性能。要使用此功能,评估数据集应包含
action_prob键,该键表示收集数据的动作概率分布,以便我们可以进行反事实评估。
RLlib 支持以下离策略估计器:
IS 和 WIS 计算行为策略(来自数据集)下的动作概率与目标策略(正在评估的策略)下的动作概率之间的比率,并使用这个比率来估计策略的回报。关于这方面的更多细节可以在它们各自的论文中找到。
DM 和 DR 训练一个 Q-模型来计算估计的回报。默认情况下,RLlib 使用 Fitted-Q Evaluation (FQE) 来训练 Q-模型。更多详情请参见 fqe_torch_model.py。
备注
对于一个上下文强盗数据集,dones 键应始终设置为 True。在这种情况下,FQE 简化为将奖励模型拟合到数据中。
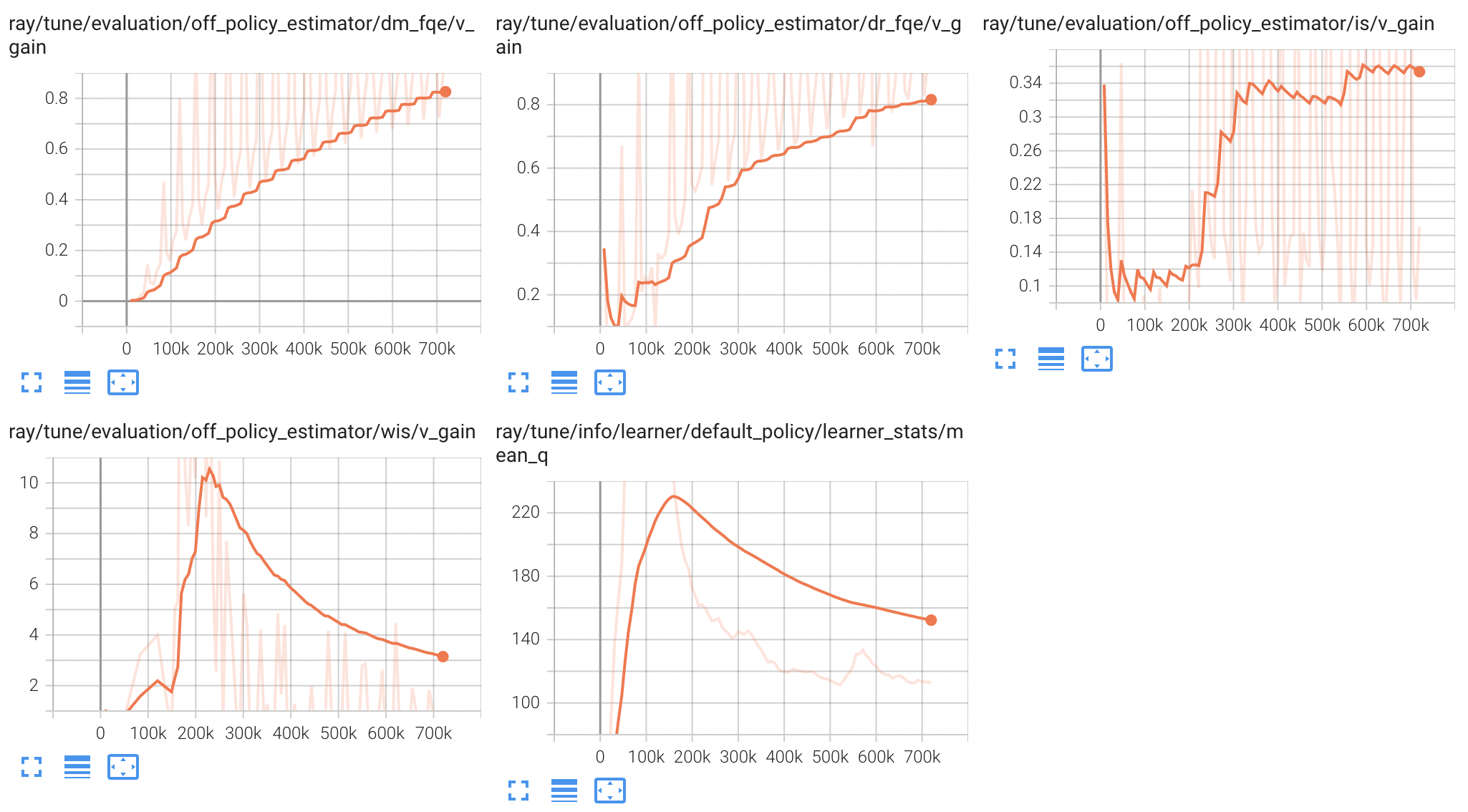
RLlib 的 OPE 估计器输出六个指标:
v_behavior: 离线剧集中奖励的折现总和,在批次中的剧集上取平均值。v_behavior_std: 对应于 v_behavior 的标准差。v_target: OPE 对目标策略的估计折扣回报,在批次中的剧集中取平均值。v_target_std: 对应于 v_target 的标准差。v_gain:v_target / max(v_behavior, 1e-8)。v_gain > 1.0表示策略优于生成行为数据的策略。如果v_behavior <= 0,则应使用v_delta进行比较。v_delta: v_target 和 v_behavior 之间的差异。
作为一个例子,我们生成了一个用于离策略估计的评估数据集:
$ rllib train \
--run=PG \
--env=CartPole-v1 \
--config='{"output": "/tmp/cartpole-eval", "output_max_file_size": 5000000}' \
--stop='{"timesteps_total": 10000}'
提示
你应该为算法训练和OPE使用不同的数据集,如这里所示。
我们现在可以离线训练一个DQN算法,并使用OPE对其进行评估:
from ray.rllib.algorithms.dqn import DQNConfig
from ray.rllib.offline.estimators import (
ImportanceSampling,
WeightedImportanceSampling,
DirectMethod,
DoublyRobust,
)
from ray.rllib.offline.estimators.fqe_torch_model import FQETorchModel
config = (
DQNConfig()
.environment(env="CartPole-v1")
.framework("torch")
.offline_data(input_="/tmp/cartpole-out")
.evaluation(
evaluation_interval=1,
evaluation_duration=10,
evaluation_num_env_runners=1,
evaluation_duration_unit="episodes",
evaluation_config={"input": "/tmp/cartpole-eval"},
off_policy_estimation_methods={
"is": {"type": ImportanceSampling},
"wis": {"type": WeightedImportanceSampling},
"dm_fqe": {
"type": DirectMethod,
"q_model_config": {"type": FQETorchModel, "polyak_coef": 0.05},
},
"dr_fqe": {
"type": DoublyRobust,
"q_model_config": {"type": FQETorchModel, "polyak_coef": 0.05},
},
},
)
)
algo = config.build()
for _ in range(100):
algo.train()
估计器 Python API: 为了更好地控制评估过程,您可以在 Python 代码中创建离策略估计器,并调用 estimator.train(batch) 进行任何必要的训练,以及调用 estimator.estimate(batch) 进行反事实估计。估计器接收一个 RLlib 策略对象和环境的 gamma 值,以及额外的估计器特定参数(例如 DM 和 DR 的 q_model_config)。您可以查看 q_model_config 的示例配置参数 这里。您还可以通过从 OffPolicyEstimator 基类派生来编写自己的离策略估计器。
algo = DQN(...)
... # train policy offline
from ray.rllib.offline.json_reader import JsonReader
from ray.rllib.offline.estimators import DoublyRobust
from ray.rllib.offline.estimators.fqe_torch_model import FQETorchModel
estimator = DoublyRobust(
policy=algo.get_policy(),
gamma=0.99,
q_model_config={"type": FQETorchModel, "n_iters": 160},
)
# Train estimator's Q-model; only required for DM and DR estimators
reader = JsonReader("/tmp/cartpole-out")
for _ in range(100):
batch = reader.next()
print(estimator.train(batch))
# {'loss': ...}
reader = JsonReader("/tmp/cartpole-eval")
# Compute off-policy estimates
for _ in range(100):
batch = reader.next()
print(estimator.estimate(batch))
# {'v_behavior': ..., 'v_target': ..., 'v_gain': ...,
# 'v_behavior_std': ..., 'v_target_std': ..., 'v_delta': ...}
示例:将外部经验转换为批处理格式#
当环境不支持模拟(例如,它是一个Web应用程序)时,需要在RLlib外部生成``*.json``经验批处理文件。这可以通过使用`JsonWriter <ray-project/ray>`__类来写出批次来完成。这个`可运行示例 <ray-project/ray>`__展示了如何为CartPole-v1生成并保存经验批次到磁盘:
import gymnasium as gym
import numpy as np
import os
import ray._private.utils
from ray.rllib.models.preprocessors import get_preprocessor
from ray.rllib.evaluation.sample_batch_builder import SampleBatchBuilder
from ray.rllib.offline.json_writer import JsonWriter
if __name__ == "__main__":
batch_builder = SampleBatchBuilder() # or MultiAgentSampleBatchBuilder
writer = JsonWriter(
os.path.join(ray._private.utils.get_user_temp_dir(), "demo-out")
)
# You normally wouldn't want to manually create sample batches if a
# simulator is available, but let's do it anyways for example purposes:
env = gym.make("CartPole-v1")
# RLlib uses preprocessors to implement transforms such as one-hot encoding
# and flattening of tuple and dict observations. For CartPole a no-op
# preprocessor is used, but this may be relevant for more complex envs.
prep = get_preprocessor(env.observation_space)(env.observation_space)
print("The preprocessor is", prep)
for eps_id in range(100):
obs, info = env.reset()
prev_action = np.zeros_like(env.action_space.sample())
prev_reward = 0
terminated = truncated = False
t = 0
while not terminated and not truncated:
action = env.action_space.sample()
new_obs, rew, terminated, truncated, info = env.step(action)
batch_builder.add_values(
t=t,
eps_id=eps_id,
agent_index=0,
obs=prep.transform(obs),
actions=action,
action_prob=1.0, # put the true action probability here
action_logp=0.0,
rewards=rew,
prev_actions=prev_action,
prev_rewards=prev_reward,
terminateds=terminated,
truncateds=truncated,
infos=info,
new_obs=prep.transform(new_obs),
)
obs = new_obs
prev_action = action
prev_reward = rew
t += 1
writer.write(batch_builder.build_and_reset())
On-policy 算法和经验后处理#
RLlib 假设输入批次是 后处理的经验。这对于离策略算法(例如,DQN 的 后处理 仅在 n_step > 1 或 replay_buffer_config.worker_side_prioritization: True 时需要)通常不是关键的。对于离策略算法,你也可以安全地将 postprocess_inputs: True 配置设置为自动后处理数据。
然而,对于像 PPO 这样的 on-policy 算法,你需要将策略评估和后处理过程中添加的额外值传递给 batch_builder.add_values(),例如,PPO 的 logits、vf_preds、value_target 和 advantages。这是必需的,因为这些值的计算依赖于 行为 策略的参数,而在离线设置中,RLlib 无法访问这些参数(在在线训练中,这些值会在策略评估期间自动添加)。
请注意,对于on-policy算法,您还需要丢弃由策略的先前版本生成的经验。这大大降低了样本效率,这通常对于离线训练是不理想的,但对于某些应用来说是有意义的。
混合仿真与离线数据#
RLlib 支持从多个输入源复用输入,包括模拟。例如,在以下示例中,我们从 /tmp/cartpole-out 读取 40% 的经验,从 hdfs:/archive/cartpole 读取 30%,最后 30% 通过策略评估生成。输入源通过 np.random.choice 进行复用:
$ rllib train \
--run=DQN \
--env=CartPole-v1 \
--config='{
"input": {
"/tmp/cartpole-out": 0.4,
"hdfs:/archive/cartpole": 0.3,
"sampler": 0.3,
},
"explore": false}'
扩展 I/O 吞吐量#
类似于扩展在线训练,您可以通过 num_env_runners 配置增加 RLlib 工作者的数量来扩展离线 I/O 吞吐量。每个工作者独立并行地访问离线存储,以实现 I/O 吞吐量的线性扩展。在每个读取工作者中,文件以随机顺序选择进行读取,但文件内容按顺序读取。
Ray 数据集成#
RLlib 实验性地支持使用 Ray Data 从/向大型离线数据集读取/写入训练样本。我们今天支持 JSON 和 Parquet 文件。Ray Data 支持的其他文件格式也可以轻松添加。
与JSON输入不同,只需通过指定所需的 num_env_runners 配置,单个数据集可以自动分片并由多个回放工作者重放。
要使用 Dataset 加载示例数据,请指定 input 和 input_config 键,如下所示:
config = {
...
"input"="dataset",
"input_config"={
"format": "json", # json or parquet
# Path to data file or directory.
"path": "/path/to/json_dir/",
# Num of tasks reading dataset in parallel, default is num_env_runners.
"parallelism": 3,
# Dataset allocates 0.5 CPU for each reader by default.
# Adjust this value based on the size of your offline dataset.
"num_cpus_per_read_task": 0.5,
}
...
}
要使用 Dataset 将示例数据写入 JSON 或 Parquet 文件,请指定 output 和 output_config 键,如下所示:
config = {
"output": "dataset",
"output_config": {
"format": "json", # json or parquet
# Directory to write data files.
"path": "/tmp/test_samples/",
# Break samples into multiple files, each containing about this many records.
"max_num_samples_per_file": 100000,
}
}
写作环境数据#
要在训练样本数据集中包含环境数据,可以使用 output_config 字典中的可选 store_infos 参数。此参数确保 infos 字典(由 RL 环境返回)包含在输出文件中。
备注
用户的责任是确保 infos 的内容可以序列化到文件中。
备注
此设置仅与基于 TensorFlow 的代理相关,对于 PyTorch 代理,infos 数据始终存储。
要使用 Dataset 将 infos 数据写入 JSON 或 Parquet 文件,请指定 output 和 output_config 键,如下所示:
config = {
"output": "dataset",
"output_config": {
"format": "json", # json or parquet
# Directory to write data files.
"path": "/tmp/test_samples/",
# Write the infos dict data
"store_infos" : True,
}
}
监督损失的输入管道#
你也可以在离线数据上定义监督模型损失。这需要定义一个 自定义模型损失 。我们提供了一个便利函数,InputReader.tf_input_ops(),可以用来将任何输入读取器转换为TF输入管道。例如:
def custom_loss(self, policy_loss):
input_reader = JsonReader("/tmp/cartpole-out")
# print(input_reader.next()) # if you want to access imperatively
input_ops = input_reader.tf_input_ops()
print(input_ops["obs"]) # -> output Tensor shape=[None, 4]
print(input_ops["actions"]) # -> output Tensor shape=[None]
supervised_loss = some_function_of(input_ops)
return policy_loss + supervised_loss
查看 custom_model_loss_and_metrics.py 以获取一个使用这些 TF 输入操作在自定义损失中的可运行示例。
输入 API#
您可以使用以下选项为代理配置经验输入:
小技巧
普通的Python配置字典将很快被 AlgorithmConfig 对象所取代,这些对象具有类型安全的优势,允许用户在有意义的子类别中设置不同的配置设置(例如 my_config.offline_data(input_=[xyz])),并提供从这些配置对象构建算法实例的能力(通过它们的 .build() 方法)。
# Specify how to generate experiences:
# - "sampler": Generate experiences via online (env) simulation (default).
# - A local directory or file glob expression (e.g., "/tmp/*.json").
# - A list of individual file paths/URIs (e.g., ["/tmp/1.json",
# "s3://bucket/2.json"]).
# - A dict with string keys and sampling probabilities as values (e.g.,
# {"sampler": 0.4, "/tmp/*.json": 0.4, "s3://bucket/expert.json": 0.2}).
# - A callable that takes an `IOContext` object as only arg and returns a
# ray.rllib.offline.InputReader.
# - A string key that indexes a callable with tune.registry.register_input
"input": "sampler",
# Arguments accessible from the IOContext for configuring custom input
"input_config": {},
# True, if the actions in a given offline "input" are already normalized
# (between -1.0 and 1.0). This is usually the case when the offline
# file has been generated by another RLlib algorithm (e.g. PPO or SAC),
# while "normalize_actions" was set to True.
"actions_in_input_normalized": False,
# Specify how to evaluate the current policy. This only has an effect when
# reading offline experiences ("input" is not "sampler").
# Available options:
# - "simulation": Run the environment in the background, but use
# this data for evaluation only and not for learning.
# - Any subclass of OffPolicyEstimator, e.g.
# ray.rllib.offline.estimators.is::ImportanceSampling or your own custom
# subclass.
"off_policy_estimation_methods": {
"is": {"type": ImportanceSampling},
"wis": {"type": WeightedImportanceSampling}
},
# Whether to run postprocess_trajectory() on the trajectory fragments from
# offline inputs. Note that postprocessing will be done using the *current*
# policy, not the *behavior* policy, which is typically undesirable for
# on-policy algorithms.
"postprocess_inputs": False,
# If positive, input batches will be shuffled via a sliding window buffer
# of this number of batches. Use this if the input data isn't in random
# enough order. Input is delayed until the shuffle buffer is filled.
"shuffle_buffer_size": 0,
自定义输入读取器的接口如下:
- class ray.rllib.offline.InputReader[源代码]
在策略评估期间收集和返回经验的API。
- abstract next() SampleBatch | MultiAgentBatch | Dict[str, Any][源代码]
返回下一批读取的经验。
- 返回:
经验读取(SampleBatch 或 MultiAgentBatch)。
- tf_input_ops(queue_size: int = 1) Dict[str, numpy.array | jnp.ndarray | tf.Tensor | torch.Tensor][源代码]
返回用于从此读取器读取输入的 TensorFlow 队列操作。
这些操作的主要用途是集成到自定义模型损失中。例如,您可以使用 tf_input_ops() 从外部经验文件中读取,以向您的模型添加模仿学习损失。
此方法创建一个队列运行器线程,该线程将反复调用此读取器的 next() 方法以向 TensorFlow 队列提供数据。
- 参数:
queue_size – TF 队列中允许的最大元素数。
from ray.rllib.models.modelv2 import ModelV2 from ray.rllib.offline.json_reader import JsonReader imitation_loss = ... class MyModel(ModelV2): def custom_loss(self, policy_loss, loss_inputs): reader = JsonReader(...) input_ops = reader.tf_input_ops() logits, _ = self._build_layers_v2( {"obs": input_ops["obs"]}, self.num_outputs, self.options) il_loss = imitation_loss(logits, input_ops["action"]) return policy_loss + il_loss
你可以在 examples/custom_loss.py 中找到这个的可运行版本。
- 返回:
每个读取的 SampleBatch 列对应一个张量的字典。
示例自定义输入API#
你可以创建一个自定义输入阅读器,如下所示:
from ray.rllib.offline import InputReader, IOContext, ShuffledInput
from ray.tune.registry import register_input
class CustomInputReader(InputReader):
def __init__(self, ioctx: IOContext): ...
def next(self): ...
def input_creator(ioctx: IOContext) -> InputReader:
return ShuffledInput(CustomInputReader(ioctx))
register_input("custom_input", input_creator)
config = {
"input": "custom_input",
"input_config": {},
...
}
你可以通过 input_config 选项将参数从配置传递到自定义输入API,该选项可以通过 IOContext 访问。 IOContext 的接口如下:
- class ray.rllib.offline.IOContext(log_dir: str | None = None, config: AlgorithmConfig | None = None, worker_index: int = 0, worker: RolloutWorker | None = None)[源代码]
包含传递给输入/输出类构造函数的属性的类。
RLlib 在构建输入/输出类(如 InputReaders 和 OutputWriters)时会自动设置这些属性。
- default_sampler_input() SamplerInput | None[源代码]
返回 RolloutWorker 的 SamplerInput 对象(如果有)。
如果 RolloutWorker 没有 SamplerInput,则返回 None。请注意,默认情况下,如果存在一个或多个远程工作者,本地工作者不会创建 SamplerInput 对象。
- 返回:
如果没有,则为 RolloutWorkers 的 SamplerInput 对象或 None。
查看 custom_input_api.py 获取一个可运行的示例。
输出 API#
您可以使用以下选项为代理配置体验输出:
小技巧
普通的Python配置字典将很快被 AlgorithmConfig 对象所取代,这些对象具有类型安全的优势,允许用户在有意义的子类别中设置不同的配置设置(例如 my_config.offline_data(input_=[xyz])),并提供从这些配置对象构建算法实例的能力(通过它们的 .build() 方法)。
# Specify where experiences should be saved:
# - None: don't save any experiences
# - "logdir" to save to the agent log dir
# - a path/URI to save to a custom output directory (e.g., "s3://bucket/")
# - a function that returns a rllib.offline.OutputWriter
"output": None,
# Arguments accessible from the IOContext for configuring custom output
"output_config": {},
# What sample batch columns to LZ4 compress in the output data.
"output_compress_columns": ["obs", "new_obs"],
# Max output file size (in bytes) before rolling over to a new file.
"output_max_file_size": 64 * 1024 * 1024,
自定义输出写入器的接口如下:
- class ray.rllib.offline.OutputWriter[源代码]
用于从策略评估中保存经验的写入器API。
- write(sample_batch: SampleBatch | MultiAgentBatch | Dict[str, Any])[源代码]
保存一批经验。
- 参数:
sample_batch – 要保存的 SampleBatch 或 MultiAgentBatch。