备注
Ray 2.10.0 引入了 RLlib 的“新 API 栈”的 alpha 阶段。Ray 团队计划将算法、示例脚本和文档迁移到新的代码库中,从而在 Ray 3.0 之前的后续小版本中逐步替换“旧 API 栈”(例如,ModelV2、Policy、RolloutWorker)。
然而,请注意,到目前为止,只有 PPO(单代理和多代理)和 SAC(仅单代理)支持“新 API 堆栈”,并且默认情况下继续使用旧 API 运行。您可以继续使用现有的自定义(旧堆栈)类。
请参阅此处 以获取有关如何使用新API堆栈的更多详细信息。
算法#
概述#
下表概述了RLlib中所有可用的算法。请注意,所有这些算法都支持在 Ray (开源) 中单个(GPU)节点上的多GPU训练( ),以及在使用 Anyscale平台 时多节点(GPU)集群上的多GPU训练(
),以及在使用 Anyscale平台 时多节点(GPU)集群上的多GPU训练( )。
)。
算法 |
单代理和多代理 |
多GPU(多节点) |
动作空间 |
On-Policy |
|||
|
|
|
|
离策略 |
|||
|
|
|
|
|
|
|
|
高吞吐量的在线和离线策略 |
|||
|
|
|
|
|
|
|
|
基于模型的强化学习 |
|||
|
|
|
|
离线强化学习和模仿学习 |
|||
|
|
|
|
|
|
|
|
算法扩展和插件 |
|||
|
|
|
|




On-policy#
近端策略优化 (PPO)#

PPO架构: 在训练迭代中,PPO执行三个主要步骤:采样一组片段或片段片段(1),将这些转换为训练批次并使用裁剪目标和多次SGD遍历此批次来更新模型(2),以及将权重从学习者同步回环境运行者(3)。PPO在两个轴上扩展,支持多个环境运行者进行样本收集,以及多个基于GPU或CPU的学习者来更新模型。#
调优示例: Pong-v5, CartPole-v1. Pendulum-v1.
PPO 特定的配置 (另见 通用配置):
- class ray.rllib.algorithms.ppo.ppo.PPOConfig(algo_class=None)[源代码]#
定义一个配置类,从中可以构建一个PPO算法。
from ray.rllib.algorithms.ppo import PPOConfig config = PPOConfig() # Activate new API stack. config.api_stack( enable_rl_module_and_learner=True, enable_env_runner_and_connector_v2=True, ) config.environment("CartPole-v1") config.env_runners(num_env_runners=1) config.training( gamma=0.9, lr=0.01, kl_coeff=0.3, train_batch_size_per_learner=256 ) # Build a Algorithm object from the config and run 1 training iteration. algo = config.build() algo.train()
from ray.rllib.algorithms.ppo import PPOConfig from ray import air from ray import tune config = ( PPOConfig() # Activate new API stack. .api_stack( enable_rl_module_and_learner=True, enable_env_runner_and_connector_v2=True, ) # Set the config object's env. .environment(env="CartPole-v1") # Update the config object's training parameters. .training( lr=0.001, clip_param=0.2 ) ) tune.Tuner( "PPO", run_config=air.RunConfig(stop={"training_iteration": 1}), param_space=config, ).fit()
- training(*, use_critic: bool | None = <ray.rllib.utils.from_config._NotProvided object>, use_gae: bool | None = <ray.rllib.utils.from_config._NotProvided object>, lambda_: float | None = <ray.rllib.utils.from_config._NotProvided object>, use_kl_loss: bool | None = <ray.rllib.utils.from_config._NotProvided object>, kl_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, kl_target: float | None = <ray.rllib.utils.from_config._NotProvided object>, mini_batch_size_per_learner: int | None = <ray.rllib.utils.from_config._NotProvided object>, sgd_minibatch_size: int | None = <ray.rllib.utils.from_config._NotProvided object>, num_sgd_iter: int | None = <ray.rllib.utils.from_config._NotProvided object>, shuffle_sequences: bool | None = <ray.rllib.utils.from_config._NotProvided object>, vf_loss_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, entropy_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, entropy_coeff_schedule: ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, clip_param: float | None = <ray.rllib.utils.from_config._NotProvided object>, vf_clip_param: float | None = <ray.rllib.utils.from_config._NotProvided object>, grad_clip: float | None = <ray.rllib.utils.from_config._NotProvided object>, lr_schedule: ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, vf_share_layers=-1, **kwargs) PPOConfig[源代码]#
设置与训练相关的配置。
- 参数:
use_critic – 应使用批评者作为基准(否则不要使用价值基准;使用GAE时需要)。
use_gae – 如果为真,使用带有价值函数的广义优势估计器 (GAE),参见 https://arxiv.org/pdf/1506.02438.pdf。
lambda – General Advantage Estimation (GAE) 的 lambda 参数。定义了在多个时间步长上实际测量的奖励与价值函数估计之间使用的指数权重。具体来说,
lambda_平衡了短期、低方差估计与长期、高方差回报。lambda_为 0.0 时,GAE 仅依赖于即时奖励(以及从那时起的 vf 预测,减少了方差,但增加了偏差),而lambda_为 1.0 时,仅在给定剧集或剧集块的截断点处包含 vf 预测(减少了偏差,但增加了方差)。use_kl_loss – 是否在损失函数中使用KL项。
kl_coeff – KL散度的初始系数。
kl_target – KL散度的目标值。
mini_batch_size_per_learner – 仅在新 API 栈启用时使用。每个 Learner 工作者的迷你批次大小。这是每个 Learner 工作者的训练批次(其大小为
s`elf.train_batch_size_per_learner)将被分割成的批次大小。例如,如果每个 Learner 工作者的训练批次大小为 4000,而每个 Learner 工作者的迷你批次大小为 400,则训练批次将被分割成 10 个大小相等的块(或“迷你批次”)。每个这样的迷你批次将用于一次 SGD 更新。总体而言,每个 Learner 工作者的训练批次将被遍历self.num_sgd_iter次。在上面的例子中,如果self.num_sgd_iter为 5,我们将在每个 Learner 更新步骤中总共执行 50 次(10x5)SGD 更新。sgd_minibatch_size – 所有设备上SGD的总批次大小。这定义了每个epoch内的最小批次大小。在新API堆栈上已弃用(请改用`mini_batch_size_per_learner`)。
num_sgd_iter – 每个外循环中的SGD迭代次数(即每个训练批次执行的轮数)。
shuffle_sequences – 在训练时是否打乱批次中的序列(推荐)。
vf_loss_coeff – 价值函数损失的系数。重要提示:如果在模型的配置中设置了 vf_share_layers=True,则必须调整此参数。
entropy_coeff – 熵系数(浮点数)或熵系数调度,格式为 [[时间步, 系数值], [时间步, 系数值], …]。如果是调度,中间的时间步将分配给线性插值的系数值。调度配置的第一个条目必须从时间步 0 开始,即:[[0, 初始值], […]]。
clip_param – PPO 剪辑参数。
vf_clip_param – 值函数的剪辑参数。请注意,这取决于奖励的规模。如果你的预期 V 值较大,请增加此参数。
grad_clip – 如果指定,则按此数量裁剪梯度的全局范数。
- 返回:
这个更新的 AlgorithmConfig 对象。
离策略#
深度Q网络 (DQN, Rainbow, 参数化DQN)#

DQN 架构: DQN 使用一个重放缓冲区来临时存储从环境中收集的片段样本。在不同的训练迭代过程中,这些片段和片段片段会从缓冲区中重新采样并重新用于更新模型,直到缓冲区达到容量并且新样本不断进入时被丢弃(FIFO)。这种训练数据的重复使用使得 DQN 非常高效且非策略性。DQN 在两个轴上扩展,支持多个样本收集的 EnvRunner 和多个基于 GPU 或 CPU 的 Learner 来更新模型。#
在 Rainbow 中评估的所有 DQN 改进都可用,尽管并非所有改进都默认启用。另请参阅如何使用 DQN 中的参数化动作。
调优示例: PongDeterministic-v4, Rainbow 配置, {BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4, 带 Dueling 和 Double-Q, 带 Distributional DQN.
提示
对于一个完整的 rainbow 设置,请对默认的 DQN 配置进行以下更改:"n_step": [1 到 10 之间], "noisy": True, "num_atoms": [大于 1], "v_min": -10.0, "v_max": 10.0``(根据你预期的回报范围设置 ``v_min 和 v_max)。
DQN 特定的配置 (另见 通用配置):
- class ray.rllib.algorithms.dqn.dqn.DQNConfig(algo_class=None)[源代码]#
定义一个配置类,从中可以构建一个DQN算法。
from ray.rllib.algorithms.dqn.dqn import DQNConfig config = DQNConfig() replay_config = { "type": "MultiAgentPrioritizedReplayBuffer", "capacity": 60000, "prioritized_replay_alpha": 0.5, "prioritized_replay_beta": 0.5, "prioritized_replay_eps": 3e-6, } config = config.training(replay_buffer_config=replay_config) config = config.resources(num_gpus=0) config = config.env_runners(num_env_runners=1) config = config.environment("CartPole-v1") algo = DQN(config=config) algo.train() del algo
from ray.rllib.algorithms.dqn.dqn import DQNConfig from ray import air from ray import tune config = DQNConfig() config = config.training( num_atoms=tune.grid_search([1,])) config = config.environment(env="CartPole-v1") tune.Tuner( "DQN", run_config=air.RunConfig(stop={"training_iteration":1}), param_space=config.to_dict() ).fit()
- training(*, target_network_update_freq: int | None = <ray.rllib.utils.from_config._NotProvided object>, replay_buffer_config: dict | None = <ray.rllib.utils.from_config._NotProvided object>, store_buffer_in_checkpoints: bool | None = <ray.rllib.utils.from_config._NotProvided object>, lr_schedule: ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, epsilon: float | ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, adam_epsilon: float | None = <ray.rllib.utils.from_config._NotProvided object>, grad_clip: int | None = <ray.rllib.utils.from_config._NotProvided object>, num_steps_sampled_before_learning_starts: int | None = <ray.rllib.utils.from_config._NotProvided object>, tau: float | None = <ray.rllib.utils.from_config._NotProvided object>, num_atoms: int | None = <ray.rllib.utils.from_config._NotProvided object>, v_min: float | None = <ray.rllib.utils.from_config._NotProvided object>, v_max: float | None = <ray.rllib.utils.from_config._NotProvided object>, noisy: bool | None = <ray.rllib.utils.from_config._NotProvided object>, sigma0: float | None = <ray.rllib.utils.from_config._NotProvided object>, dueling: bool | None = <ray.rllib.utils.from_config._NotProvided object>, hiddens: int | None = <ray.rllib.utils.from_config._NotProvided object>, double_q: bool | None = <ray.rllib.utils.from_config._NotProvided object>, n_step: int | ~typing.Tuple[int, int] | None = <ray.rllib.utils.from_config._NotProvided object>, before_learn_on_batch: ~typing.Callable[[~typing.Type[~ray.rllib.policy.sample_batch.MultiAgentBatch], ~typing.List[~typing.Type[~ray.rllib.policy.policy.Policy]], ~typing.Type[int]], ~typing.Type[~ray.rllib.policy.sample_batch.MultiAgentBatch]] = <ray.rllib.utils.from_config._NotProvided object>, training_intensity: float | None = <ray.rllib.utils.from_config._NotProvided object>, td_error_loss_fn: str | None = <ray.rllib.utils.from_config._NotProvided object>, categorical_distribution_temperature: float | None = <ray.rllib.utils.from_config._NotProvided object>, **kwargs) DQNConfig[源代码]#
设置与训练相关的配置。
- 参数:
target_network_update_freq – 每
target_network_update_freq个样本步骤更新一次目标网络。replay_buffer_config – 重放缓冲区配置。示例:{ “_enable_replay_buffer_api”: True, “type”: “MultiAgentReplayBuffer”, “capacity”: 50000, “replay_sequence_length”: 1, } - 或 - { “_enable_replay_buffer_api”: True, “type”: “MultiAgentPrioritizedReplayBuffer”, “capacity”: 50000, “prioritized_replay_alpha”: 0.6, “prioritized_replay_beta”: 0.4, “prioritized_replay_eps”: 1e-6, “replay_sequence_length”: 1, } - 其中 - prioritized_replay_alpha:Alpha 参数控制缓冲区中优先级的程度。换句话说,当缓冲区样本具有更高的时序差分误差时,应该以多大的概率将其抽取出来用于更新参数化 Q 网络。0.0 对应于均匀概率。设置远高于 1.0 可能会导致采样分布变得非常“尖锐”且熵低。prioritized_replay_beta:Beta 参数控制重要性采样的程度,抑制通过 alpha 参数和时序差分误差具有更高采样概率的样本的梯度更新影响。prioritized_replay_eps:Epsilon 参数设置采样的基准概率,以便当样本的时序差分误差为零时,仍有抽取该样本的机会。
store_buffer_in_checkpoints – 如果希望将缓冲区内容也存储在任何保存的检查点中,请将此设置为 True。如果出现以下情况,将生成警告:- 此项为 True 且从包含无缓冲区数据的检查点恢复。- 此项为 False 且从包含缓冲区数据的检查点恢复。
epsilon – Epsilon 探索计划。格式为 [[时间步, 值], [时间步, 值], …]。计划必须从时间步 0 开始。
adam_epsilon – Adam 优化器的 epsilon 超参数。
grad_clip – 如果不是 None,在优化过程中在此值处裁剪梯度。
num_steps_sampled_before_learning_starts – 在从回放缓冲区中采样进行学习之前,从回放工作者收集的时间步数。我们是以代理步骤还是环境步骤来计算这个取决于 config.multi_agent(count_steps_by=..)。
tau – 通过 au * 策略 + (1 - au) * 目标策略 更新目标。
num_atoms – 用于表示回报分布的原子数量。当这个数量大于1时,使用分布式Q学习。
v_min – 最小值估计
v_max – 最大值估计
noisy – 是否使用噪声网络来辅助探索。这会在模型权重中添加参数噪声。
sigma0 – 控制噪声网络的初始参数噪声。
dueling – 是否使用 dueling DQN。
hiddens – 优势分支和价值分支的密集层设置
double_q – 是否使用双DQN。
n_step – N步目标更新。如果 >1,轨迹中的 sars’ 元组将被后处理为 sa[折扣后的 R 总和][s t+n] 元组。一个整数将被解释为一个固定的 n 步值。如果在这里提供了一个由 2 个整数组成的元组,n 步值将从定义的闭区间
[n_step[0], n_step[1]]上的均匀分布中为训练批次中的每个样本抽取。before_learn_on_batch – 在处理多智能体经验批处理之前运行的回调函数。
training_intensity – 更新模型的强度(相对于从环境中收集样本)。如果为 None,则使用“自然”值:
train_batch_size/ (rollout_fragment_lengthxnum_env_runnersxnum_envs_per_env_runner)。如果不为 None,将确保插入缓冲区和从缓冲区采样的步数之间的比率与给定值匹配。示例:training_intensity=1000.0 train_batch_size=250 rollout_fragment_length=1 num_env_runners=1(或 0)num_envs_per_env_runner=1 -> 自然值 = 250 / 1 = 250.0 -> 将确保重放+训练操作的执行频率是回放+插入操作的 4 倍(4 * 250 = 1000)。详情请参阅:rllib/algorithms/dqn/dqn.py::calculate_rr_weights。td_error_loss_fn – “huber” 或 “mse”。当 num_atoms 为 1 时计算 TD 误差的损失函数。请注意,如果 num_atoms 大于 1,则此参数将被忽略,并将使用 softmax 交叉熵损失。
categorical_distribution_temperature – 设置分类动作分布使用的温度参数。有效的温度范围是 [0, 1]。请注意,这主要影响评估,因为TD误差在返回计算中使用argmax。
- 返回:
这个更新的 AlgorithmConfig 对象。
软动作评论家 (SAC)#

SAC 架构: SAC 使用一个重放缓冲区来暂时存储从环境中收集的片段样本。在不同的训练迭代过程中,这些片段和片段片段从缓冲区中重新采样并重新用于更新模型,当缓冲区达到容量并且新样本不断进入时,最终会被丢弃(FIFO)。这种训练数据的重复使用使得 DQN 非常样本高效且非策略。SAC 在两个轴上扩展,支持多个样本收集的 EnvRunners 和多个基于 GPU 或 CPU 的 Learners 用于更新模型。#
调优示例: Pendulum-v1, HalfCheetah-v3,
SAC 特定配置 (另见 通用配置):
- class ray.rllib.algorithms.sac.sac.SACConfig(algo_class=None)[源代码]#
定义一个配置类,从中可以构建一个SAC算法。
config = SACConfig().training(gamma=0.9, lr=0.01, train_batch_size=32) config = config.resources(num_gpus=0) config = config.env_runners(num_env_runners=1) # Build a Algorithm object from the config and run 1 training iteration. algo = config.build(env="CartPole-v1") algo.train()
- training(*, twin_q: bool | None = <ray.rllib.utils.from_config._NotProvided object>, q_model_config: ~typing.Dict[str, ~typing.Any] | None = <ray.rllib.utils.from_config._NotProvided object>, policy_model_config: ~typing.Dict[str, ~typing.Any] | None = <ray.rllib.utils.from_config._NotProvided object>, tau: float | None = <ray.rllib.utils.from_config._NotProvided object>, initial_alpha: float | None = <ray.rllib.utils.from_config._NotProvided object>, target_entropy: str | float | None = <ray.rllib.utils.from_config._NotProvided object>, n_step: int | ~typing.Tuple[int, int] | None = <ray.rllib.utils.from_config._NotProvided object>, store_buffer_in_checkpoints: bool | None = <ray.rllib.utils.from_config._NotProvided object>, replay_buffer_config: ~typing.Dict[str, ~typing.Any] | None = <ray.rllib.utils.from_config._NotProvided object>, training_intensity: float | None = <ray.rllib.utils.from_config._NotProvided object>, clip_actions: bool | None = <ray.rllib.utils.from_config._NotProvided object>, grad_clip: float | None = <ray.rllib.utils.from_config._NotProvided object>, optimization_config: ~typing.Dict[str, ~typing.Any] | None = <ray.rllib.utils.from_config._NotProvided object>, actor_lr: float | ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, critic_lr: float | ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, alpha_lr: float | ~typing.List[~typing.List[int | float]] | None = <ray.rllib.utils.from_config._NotProvided object>, target_network_update_freq: int | None = <ray.rllib.utils.from_config._NotProvided object>, _deterministic_loss: bool | None = <ray.rllib.utils.from_config._NotProvided object>, _use_beta_distribution: bool | None = <ray.rllib.utils.from_config._NotProvided object>, num_steps_sampled_before_learning_starts: int | None = <ray.rllib.utils.from_config._NotProvided object>, **kwargs) SACConfig[源代码]#
设置与训练相关的配置。
- 参数:
twin_q – 使用两个 Q 网络(而不是一个)进行动作价值估计。注意:每个 Q 网络将拥有自己的目标网络。
q_model_config – Q 网络的模型配置。这些将覆盖 MODEL_DEFAULTS。这与在设置 Q 网络(如果 twin_q=True 则为 2 个)时处理顶级
model字典的方式相同。这意味着,您可以为不同的观察空间执行以下操作:obs=Box(1D)->Tuple(Box(1D) + Action)->concat->post_fcnetobs=Box(3D) -> Tuple(Box(3D) + Action) -> vision-net -> concat w/ action -> post_fcnet obs=Tuple(Box(1D), Box(3D)) -> Tuple(Box(1D), Box(3D), Action) -> vision-net -> concat w/ Box(1D) 和 action -> post_fcnet 您还可以通过在下面的字典中简单地指定custom_model子键,让 SAC 使用您的自定义模型作为 Q 模型(就像在顶级model字典中一样)。policy_model_config – 策略函数的模型选项(详见上面的
q_model_config)。与上面的q_model_config不同之处在于,在 post_fcnet 堆栈之前不会执行动作连接。tau – 通过 au * 策略 + (1 - au) * 目标策略 更新目标。
initial_alpha – 用于熵权重的初始值 alpha。
target_entropy – 目标熵下限。如果为“auto”,将被设置为 `-|A|`(例如,对于 Discrete(2) 为 -2.0,对于 Box(shape=(3,)) 为 -3.0)。这是奖励尺度的倒数,并将自动优化。
n_step – N步目标更新。如果 >1,轨迹中的 sars’ 元组将被后处理为 sa[折扣后的 R 总和][s t+n] 元组。一个整数将被解释为一个固定的 n 步值。如果在这里提供了一个由 2 个整数组成的元组,n 步值将从定义的闭区间
[n_step[0], n_step[1]]上的均匀分布中为训练批次中的每个样本抽取。store_buffer_in_checkpoints – 如果希望将缓冲区内容也存储在任何保存的检查点中,请将此设置为 True。如果出现以下情况,将生成警告:- 此项为 True 且从包含无缓冲区数据的检查点恢复。- 此项为 False 且从包含缓冲区数据的检查点恢复。
replay_buffer_config – 重放缓冲区配置。示例:{ “_enable_replay_buffer_api”: True, “type”: “MultiAgentReplayBuffer”, “capacity”: 50000, “replay_batch_size”: 32, “replay_sequence_length”: 1, } - 或 - { “_enable_replay_buffer_api”: True, “type”: “MultiAgentPrioritizedReplayBuffer”, “capacity”: 50000, “prioritized_replay_alpha”: 0.6, “prioritized_replay_beta”: 0.4, “prioritized_replay_eps”: 1e-6, “replay_sequence_length”: 1, } - 其中 - prioritized_replay_alpha:Alpha 参数控制缓冲区中优先级的程度。换句话说,当缓冲区样本具有更高的时序差分误差时,应该以多大的概率抽取该样本以更新参数化的 Q 网络。0.0 对应于均匀概率。设置远高于 1.0 可能会导致采样分布变得非常“尖锐”,熵值低。 prioritized_replay_beta:Beta 参数控制重要性采样的程度,抑制通过 alpha 参数和时序差分误差具有更高采样概率的样本的梯度更新的影响。 prioritized_replay_eps:Epsilon 参数设置采样的基准概率,以便当样本的时序差分误差为零时,仍有机会抽取该样本。
training_intensity – 更新模型的强度(相对于从环境中收集样本)。如果为 None,则使用“自然”值:
train_batch_size/ (rollout_fragment_lengthxnum_env_runnersxnum_envs_per_env_runner)。如果不为 None,将确保插入缓冲区和从缓冲区采样的步数之间的比率与给定值匹配。示例:training_intensity=1000.0 train_batch_size=250 rollout_fragment_length=1 num_env_runners=1(或 0)num_envs_per_env_runner=1 -> 自然值 = 250 / 1 = 250.0 -> 将确保重放+训练操作的执行频率是回放+插入操作的 4 倍(4 * 250 = 1000)。详见:rllib/algorithms/dqn/dqn.py::calculate_rr_weights。clip_actions – 是否裁剪动作。如果动作已经归一化,则应设置为 False。
grad_clip – 如果不是 None,在优化过程中在此值处裁剪梯度。
optimization_config – 优化配置字典。在此设置支持的键
actor_learning_rate、critic_learning_rate和entropy_learning_rate。actor_lr – 学习率(浮点数)或策略的学习率调度,格式为 [[时间步,学习率值], [时间步,学习率值], …]。如果是调度,中间的时间步将分配给线性插值的学习率值。调度配置的第一个条目必须从时间步 0 开始,即:[[0, 初始值], […]]。注意:通常的做法(双时间尺度方法)是使用比批评者更小的学习率来确保批评者提供足够值以改进策略。注意:如果您需要 a) 多个优化器(每个 RLModule),b) 非 Adam 的优化器类型,c) 不是如上所述的线性插值分段调度的学习率调度,或 d) 指定优化器的构造函数参数(例如 Adam 的 epsilon),那么您必须重写学习者的
configure_optimizer_for_module()方法并自行处理学习率调度。默认值为 3e-5,比批评者的学习率少一个小数位(见critic_lr)。critic_lr – 学习率(浮点数)或批评者的学习率计划,格式为 [[时间步,学习率值], [时间步,学习率值], …]。如果是计划,中间的时间步将分配给线性插值的学习率值。计划配置的第一个条目必须从时间步 0 开始,即:[[0, 初始值], […]]。注意:常见的做法(双时间尺度方法)是使用比批评者更小的学习率来确保批评者提供足够的值来改进策略。注意:如果您需要 a) 多个优化器(每个 RLModule),b) 非 Adam 的优化器类型,c) 不是如上所述的线性插值的分段学习率计划,或 d) 指定优化器的构造函数参数(例如 Adam 的 epsilon),那么您必须重写学习者的
configure_optimizer_for_module()方法并自行处理学习率调度。默认值为 3e-4,比演员(策略)的学习率(参见actor_lr)高一位小数。alpha_lr – 学习率(浮点数)或超参数 alpha 的学习率调度,格式为 [[时间步,学习率值], [时间步,学习率值], …]。如果是调度,中间的时间步将被分配为线性插值的学习率值。调度配置的第一个条目必须从时间步 0 开始,即:[[0, 初始值], […]]。注意:如果您需要 a) 多个优化器(每个 RLModule),b) 非 Adam 的优化器类型,c) 不是如上所述的线性插值分段调度,或者 d) 指定优化器的构造函数参数(例如 Adam 的 epsilon),那么您必须重写 Learner 的
configure_optimizer_for_module()方法并自行处理学习率调度。默认值为 3e-4,与评论家学习率 (lr) 相同。target_network_update_freq – 每
target_network_update_freq步更新一次目标网络。_deterministic_loss – 损失是否应确定性地计算(不包括随机动作采样步骤)。仅在连续动作和调试时为True才有用。
_use_beta_distribution – 对于有界连续动作空间,使用 Beta 分布代替 `SquashedGaussian`(不推荐;仅用于调试)。
- 返回:
这个更新的 AlgorithmConfig 对象。
高吞吐量 在线和离线策略#
重要性加权演员-学习者架构 (IMPALA)#

IMPALA 架构: 在训练迭代中,IMPALA 异步请求所有 EnvRunner 的样本,收集到的 episode 样本作为 ray 引用(而不是本地 algo 进程上的实际对象)返回给主算法进程。这些 episode 引用随后被传递给学习者(Learner)进行模型的异步更新。为了解决这种异步设计导致 EnvRunner 在一定程度上偏离策略(模型在新权重版本可用后并不总是立即同步回 EnvRunner)的问题,IMPALA 使用了一种称为 v-trace 的过程,在论文中有详细描述。IMPALA 在两个维度上扩展,支持多个 EnvRunner 进行样本收集,以及多个基于 GPU 或 CPU 的学习者进行模型更新。#
调优示例:PongNoFrameskip-v4,向量化配置,多GPU配置,{BeamRider,Breakout,Qbert,SpaceInvaders}NoFrameskip-v4。
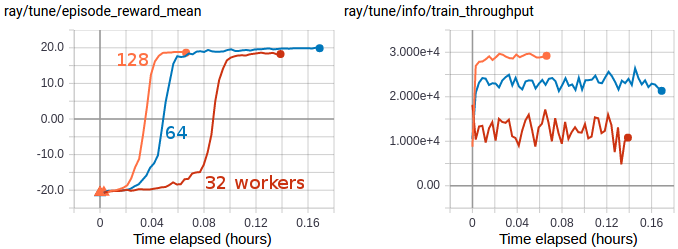
多GPU IMPALA 可以在大约3分钟内使用一对V100 GPU和128个CPU工作线程解决PongNoFrameskip-v4。达到的最大训练吞吐量约为每秒30k次转换(每秒约120k个环境帧)。#
IMPALA 特定的配置 (另见 通用配置):
- ray.rllib.algorithms.impala.impala.ImpalaConfig#
IMPALAConfig的别名
异步近端策略优化 (APPO)#

APPO 架构: APPO 是基于 IMPALA 架构的 近端策略优化 (PPO) 的异步变体,但使用带有剪裁的代理策略损失,允许在每个收集的训练批次中进行多次 SGD 传递。在训练迭代中,APPO 异步请求所有 EnvRunner 的样本,收集的剧集样本作为 ray 引用(而不是本地算法进程上的实际对象)返回到主算法进程。这些剧集引用随后传递给学习者,以异步更新模型。为了解决这种异步设计导致 EnvRunner 在某种程度上偏离策略的问题(模型并不总是在新权重版本可用后立即同步回 EnvRunner),APPO 使用了一种称为 v-trace 的过程,在 IMPALA 论文中描述。APPO 在两个轴上扩展,支持多个 EnvRunner 进行样本收集,以及多个基于 GPU 或 CPU 的学习者来更新模型。#
调优示例: PongNoFrameskip-v4
APPO 特定配置 (另见 通用配置):
- class ray.rllib.algorithms.appo.appo.APPOConfig(algo_class=None)[源代码]#
定义一个配置类,从中可以构建一个APPO算法。
from ray.rllib.algorithms.appo import APPOConfig config = APPOConfig().training(lr=0.01, grad_clip=30.0, train_batch_size=50) config = config.resources(num_gpus=0) config = config.env_runners(num_env_runners=1) config = config.environment("CartPole-v1") # Build an Algorithm object from the config and run 1 training iteration. algo = config.build() algo.train() del algo
from ray.rllib.algorithms.appo import APPOConfig from ray import air from ray import tune config = APPOConfig() # Update the config object. config = config.training(lr=tune.grid_search([0.001,])) # Set the config object's env. config = config.environment(env="CartPole-v1") # Use to_dict() to get the old-style python config dict # when running with tune. tune.Tuner( "APPO", run_config=air.RunConfig(stop={"training_iteration": 1}, verbose=0), param_space=config.to_dict(), ).fit()
- training(*, vtrace: bool | None = <ray.rllib.utils.from_config._NotProvided object>, use_critic: bool | None = <ray.rllib.utils.from_config._NotProvided object>, use_gae: bool | None = <ray.rllib.utils.from_config._NotProvided object>, lambda_: float | None = <ray.rllib.utils.from_config._NotProvided object>, clip_param: float | None = <ray.rllib.utils.from_config._NotProvided object>, use_kl_loss: bool | None = <ray.rllib.utils.from_config._NotProvided object>, kl_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, kl_target: float | None = <ray.rllib.utils.from_config._NotProvided object>, tau: float | None = <ray.rllib.utils.from_config._NotProvided object>, target_network_update_freq: int | None = <ray.rllib.utils.from_config._NotProvided object>, target_update_frequency=-1, **kwargs) APPOConfig[源代码]#
设置与训练相关的配置。
- 参数:
vtrace – 是否使用 V-trace 加权优势。如果为假,将使用 PPO GAE 优势。
use_critic – 应使用批评者作为基准(否则不要使用价值基准;使用GAE时需要)。仅在vtrace=False时适用。
use_gae – 如果为真,使用广义优势估计器 (GAE) 和价值函数,参见 https://arxiv.org/pdf/1506.02438.pdf。仅在 vtrace=False 时适用。
lambda – GAE (lambda) 参数。
clip_param – PPO 代理滑移参数。
use_kl_loss – 是否在损失函数中使用KL项。
kl_coeff – 用于加权 KL-loss 项的系数。
kl_target – KL-term 的目标值(通过自动调整
kl_coeff达到)。tau – 更新目标策略网络向当前策略网络的因子。范围在0到1之间。例如,updated_param = tau * current_param + (1 - tau) * target_param
target_network_update_freq – 更新目标策略和调整训练期间使用的kl损失系数的频率。设置此参数后,算法将等待至少
target_network_update_freq * minibatch_size * num_sgd_iter数量的样本被学习者组训练后,再更新目标网络和调整训练期间使用的kl损失系数。注意:此参数仅在使用学习者API时适用(enable_rl_module_and_learner=True)。
- 返回:
这个更新的 AlgorithmConfig 对象。
基于模型的强化学习#
DreamerV3#

DreamerV3 架构: DreamerV3 通过使用真实环境交互(从重放缓冲区中采样)以监督方式训练一个递归的 WORLD_MODEL。WORLD_MODEL 的目标是正确预测 RL 环境的转换动态:下一个观察、奖励和一个布尔继续标志。随后,ACTOR 和 CRITIC 网络仅在由 WORLD_MODEL “梦想”合成的轨迹上进行训练。DreamerV3 在两个轴上进行扩展,支持多个 EnvRunners 进行样本收集和多个基于 GPU 或 CPU 的学习者进行模型更新。它还可以用于不同类型的环境,包括基于图像或向量的观察、连续或离散的动作,以及稀疏或密集的奖励函数。#
调优示例: Atari 100k, Atari 200M, DeepMind Control Suite
Pong-v5 结果 (1, 2, 和 4 个GPU):

Pong-v5 环境的剧集平均奖励(在“100k”设置下,仅允许100k环境步数):请注意,尽管样本效率稳定——通过每个环境步数的恒定学习性能显示——但随着我们从1到4个GPU的变化,墙时间几乎呈线性改善。左:环境时间步采样下的剧集奖励。右:墙时间下的剧集奖励。#
Atari 100k 结果 (1 vs 4 GPUs):

在1 vs 4 GPUs上各种Atari 100k任务的剧集平均奖励。左侧:按环境时间步采样的剧集奖励。右侧:按墙钟时间采样的剧集奖励。#
DeepMind 控制套件(视觉)结果(1 vs 4 GPU):

在1 vs 4 GPUs上各种Atari 100k任务的剧集平均奖励。左侧:按环境时间步采样的剧集奖励。右侧:按墙钟时间采样的剧集奖励。#
离线强化学习与模仿学习#
行为克隆 (BC)#

BC 架构: RLlib 的行为克隆 (BC) 使用 Ray Data 来利用其并行数据处理能力。在一次训练迭代中,n 个 DataWorker 并行地从离线(例如 JSON)文件中读取剧集。然后,这些剧集被预处理成训练批次,并直接作为数据迭代器发送给 n 个 Learner,它们执行前向和后向传递以及优化器步骤。RLlib 的 (BC) 实现直接源自 MARWIL 实现,唯一的区别在于 beta 参数(设置为 0.0)。这使得 BC 尝试匹配生成离线数据的行为策略,而忽略任何产生的奖励。#
调优示例: CartPole-v1 Pendulum-v1
BC 特定配置 (另见 通用配置):
- class ray.rllib.algorithms.bc.bc.BCConfig(algo_class=None)[源代码]#
定义一个配置类,从中可以构建一个新的 BC 算法
from ray.rllib.algorithms.bc import BCConfig # Run this from the ray directory root. config = BCConfig().training(lr=0.00001, gamma=0.99) config = config.offline_data( input_="./rllib/tests/data/cartpole/large.json") # Build an Algorithm object from the config and run 1 training iteration. algo = config.build() algo.train()
from ray.rllib.algorithms.bc import BCConfig from ray import tune config = BCConfig() # Print out some default values. print(config.beta) # Update the config object. config.training( lr=tune.grid_search([0.001, 0.0001]), beta=0.75 ) # Set the config object's data path. # Run this from the ray directory root. config.offline_data( input_="./rllib/tests/data/cartpole/large.json" ) # Set the config object's env, used for evaluation. config.environment(env="CartPole-v1") # Use to_dict() to get the old-style python config dict # when running with tune. tune.Tuner( "BC", param_space=config.to_dict(), ).fit()
- training(*, beta: float | None = <ray.rllib.utils.from_config._NotProvided object>, bc_logstd_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, moving_average_sqd_adv_norm_update_rate: float | None = <ray.rllib.utils.from_config._NotProvided object>, moving_average_sqd_adv_norm_start: float | None = <ray.rllib.utils.from_config._NotProvided object>, vf_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, grad_clip: float | None = <ray.rllib.utils.from_config._NotProvided object>, **kwargs) MARWILConfig#
设置与训练相关的配置。
- 参数:
beta – 以指数形式放大优势。当 beta 为 0.0 时,MARWIL 简化为行为克隆(模仿学习);请参见同一目录中的 bc.py 算法。
bc_logstd_coeff – 一个系数,用于鼓励更高的动作分布熵以进行探索。
moving_average_sqd_adv_norm_start – 平方移动平均优势范数的起始值 (c^2)。
vf_coeff – 平衡价值估计损失和策略优化损失。moving_average_sqd_adv_norm_update_rate: 平方移动平均优势范数(c^2)的更新率。
grad_clip – 如果指定,则按此数量裁剪梯度的全局范数。
- 返回:
这个更新的 AlgorithmConfig 对象。
单调优势重新加权模仿学习 (MARWIL)#

MARWIL 架构: MARWIL 是一种结合了模仿学习和策略梯度算法的混合算法,适用于在批量历史数据上进行训练。当 beta 超参数设置为零时,MARWIL 目标简化为纯模仿学习(参见 BC)。MARWIL 使用 Ray Data 来利用其并行数据处理能力。在一次训练迭代中,剧集通过 n 个 DataWorkers 从离线(例如 JSON)文件中并行读取。然后,这些剧集被预处理成训练批次,并直接作为数据迭代器发送给 n 个 Learners,这些 Learners 执行前向和后向传递以及优化器步骤。#
调优示例: CartPole-v1
MARWIL 特定配置 (另见 通用配置):
- class ray.rllib.algorithms.marwil.marwil.MARWILConfig(algo_class=None)[源代码]#
定义一个配置类,从中可以构建一个MARWIL算法。
示例
>>> from ray.rllib.algorithms.marwil import MARWILConfig >>> # Run this from the ray directory root. >>> config = MARWILConfig() >>> config = config.training(beta=1.0, lr=0.00001, gamma=0.99) >>> config = config.offline_data( ... input_=["./rllib/tests/data/cartpole/large.json"]) >>> print(config.to_dict()) ... >>> # Build an Algorithm object from the config and run 1 training iteration. >>> algo = config.build() >>> algo.train()
示例
>>> from ray.rllib.algorithms.marwil import MARWILConfig >>> from ray import tune >>> config = MARWILConfig() >>> # Print out some default values. >>> print(config.beta) >>> # Update the config object. >>> config.training(lr=tune.grid_search( ... [0.001, 0.0001]), beta=0.75) >>> # Set the config object's data path. >>> # Run this from the ray directory root. >>> config.offline_data( ... input_=["./rllib/tests/data/cartpole/large.json"]) >>> # Set the config object's env, used for evaluation. >>> config.environment(env="CartPole-v1") >>> # Use to_dict() to get the old-style python config dict >>> # when running with tune. >>> tune.Tuner( ... "MARWIL", ... param_space=config.to_dict(), ... ).fit()
- training(*, beta: float | None = <ray.rllib.utils.from_config._NotProvided object>, bc_logstd_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, moving_average_sqd_adv_norm_update_rate: float | None = <ray.rllib.utils.from_config._NotProvided object>, moving_average_sqd_adv_norm_start: float | None = <ray.rllib.utils.from_config._NotProvided object>, vf_coeff: float | None = <ray.rllib.utils.from_config._NotProvided object>, grad_clip: float | None = <ray.rllib.utils.from_config._NotProvided object>, **kwargs) MARWILConfig[源代码]#
设置与训练相关的配置。
- 参数:
beta – 以指数形式放大优势。当 beta 为 0.0 时,MARWIL 简化为行为克隆(模仿学习);请参见同一目录中的 bc.py 算法。
bc_logstd_coeff – 一个系数,用于鼓励更高的动作分布熵以进行探索。
moving_average_sqd_adv_norm_start – 平方移动平均优势范数的起始值 (c^2)。
vf_coeff – 平衡价值估计损失和策略优化损失。moving_average_sqd_adv_norm_update_rate: 平方移动平均优势范数(c^2)的更新率。
grad_clip – 如果指定,则按此数量裁剪梯度的全局范数。
- 返回:
这个更新的 AlgorithmConfig 对象。
算法扩展和插件#
由自我监督预测驱动的探索好奇心#

ICM(内在好奇心模型)架构: ICM 背后的主要思想是训练一个世界模型(与“主要”策略并行)来预测环境的动态。世界模型的损失是将被添加到环境奖励中的内在奖励。这确保了当处于环境中的相对未知区域(世界模型在预测接下来发生的事情时表现不佳)时,人工内在奖励很大,并且代理被激励去探索这些未知区域。RLlib 的好奇心实现适用于 RLlib 的任何算法。请参阅这些链接以获取基于 PPO 和 DQN 的示例实现。ICM 使用所选算法的 training_step() 保持不变,但在 LearnerGroup.update 期间执行以下额外步骤:复制“主要”策略的训练批次,并将其用于执行 ICM 的自我监督更新。使用 ICM 计算内在奖励,并将这些奖励添加到外在(环境)奖励中。然后继续更新“主要”策略。#
调优示例: 12x12 FrozenLake-v1
