Ray Tune 常见问题解答#
这里我们尝试回答一些常见的问题。如果你在阅读此常见问题解答后仍有疑问,请告诉我们!
什么是超参数?#
什么是 超参数?它们与 模型参数 有什么不同?
在监督学习中,我们使用带标签的数据训练模型,以便模型能够正确识别新的数据值。模型的所有内容由一组参数定义,例如线性回归中的权重。这些是 模型参数;它们在训练过程中学习得到。
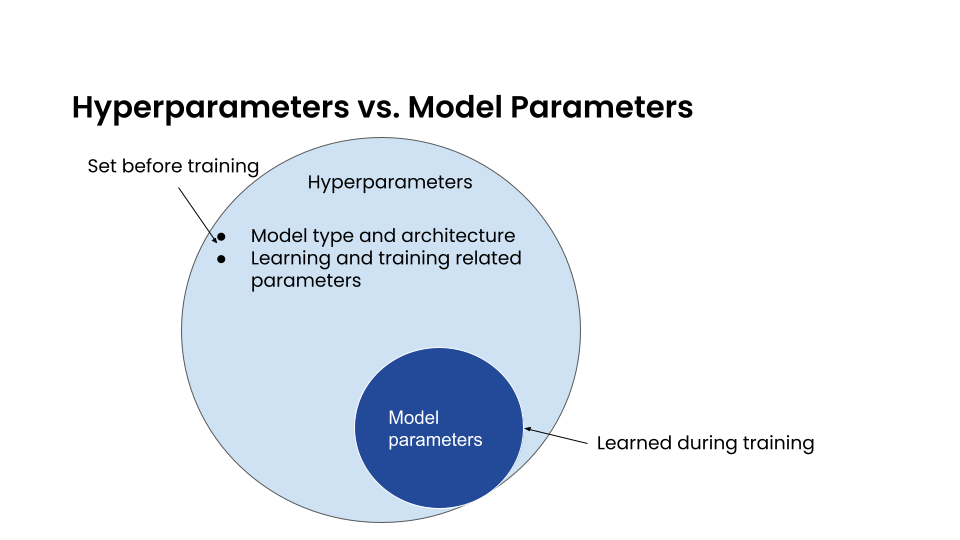
相比之下,超参数 定义了关于模型本身结构的具体细节,例如我们是否使用线性回归或分类,哪种架构最适合神经网络,有多少层,使用什么样的过滤器等。它们在训练之前定义,而不是学习得到的。
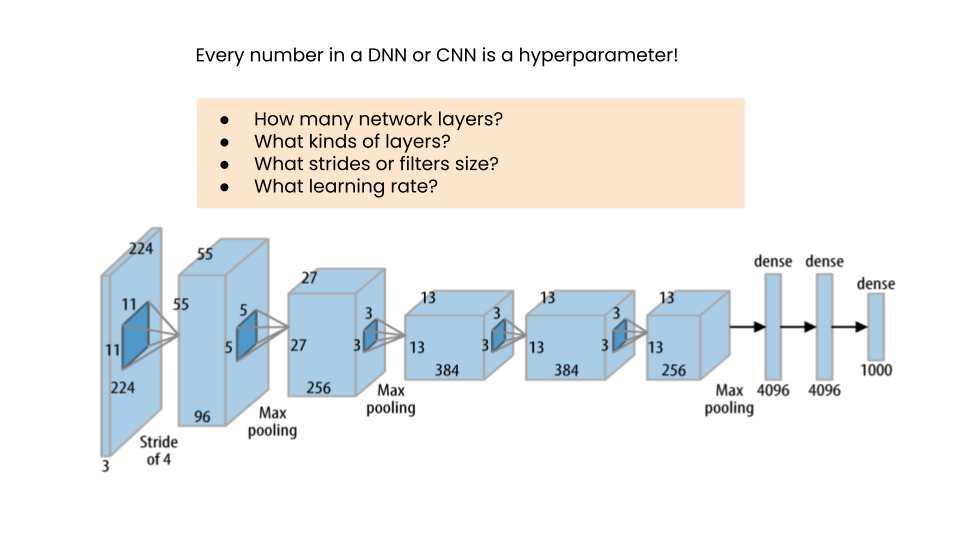
其他被视为 超参数 的量包括学习率、折扣率等。如果我们希望我们的训练过程和最终模型表现良好,我们首先需要确定一组最优或接近最优的 超参数。
我们如何确定最佳的 超参数 ?最直接的方法是执行一个循环,我们从一些合理包含可能值的列表中选择一组候选值,训练模型,将结果与之前的循环迭代进行比较,并选择表现最好的那组。这个过程称为 超参数调优 或 优化 (HPO)。而 超参数 是在一个配置和限制的搜索空间中指定的,每个 超参数 在 config 字典中集体定义。
我应该选择哪种搜索算法/调度器?#
Ray Tune 提供了 许多不同的搜索算法 和 调度器。决定使用哪一个主要取决于你的问题:
这是一个小问题还是大问题(训练需要多长时间?资源如GPU的成本有多高)?你能并行运行多个试验吗?
您想要调整多少个超参数?
超参数的有效值是什么?
**如果你的模型返回增量结果**(例如,深度学习中的每个epoch结果,GBDTs中每添加一棵树的结果等),使用早停通常允许采样更多配置,因为不理想的试验在它们完成整个过程之前就被剪枝了。请注意,并非所有搜索算法都可以使用来自剪枝试验的信息。没有增量结果就不能使用早停——在功能API的情况下,这意味着必须多次调用 session.report() ——通常在一个循环中。
如果你的模型很小,你通常可以尝试运行许多不同的配置。可以使用**随机搜索**来生成配置。你也可以在一些值上进行网格搜索。你可能仍然应该使用 :ref:`ASHA 来提前终止不良试验 <tune-scheduler-hyperband>`(如果你的问题支持提前停止)。
如果你的模型很大,你可以尝试使用 基于贝叶斯优化的搜索算法 如 贝叶斯优化 来在少量试验后获得良好的参数配置。Ax 类似但更能抵抗噪声数据。请注意,这些算法仅在 少量超参数 的情况下表现良好。或者,你可以使用 基于种群的训练,它在少量试验中表现良好,例如8次甚至4次。然而,这将输出一个超参数 时间表 而不是一组固定的超参数。
如果你有少量超参数,贝叶斯优化方法效果很好。可以查看 BOHB 或 Optuna 结合 ASHA 调度器,以结合贝叶斯优化的优势和提前停止的优点。
如果你只有超参数的连续值,这将与大多数贝叶斯优化方法很好地配合。离散或分类变量仍然有效,但随着类别数量的增加,效果会变差。
如果你有许多超参数的分类值,考虑使用随机搜索,或基于TPE的贝叶斯优化算法,如 Optuna 或 HyperOpt。
我们的首选解决方案 通常是使用 随机搜索 并结合 ASHA 用于早期停止 来解决较小的问题。对于 较大问题 且 超参数数量较少 的情况,使用 BOHB;如果可以接受学习计划,对于 较大问题 且 超参数数量较多 的情况,使用 基于种群的训练。
如何选择超参数范围?#
一个好的开始是查看介绍这些算法的论文,同时也可以看看其他人正在使用什么。
大多数算法也为它们的一些参数提供了合理的默认值。例如,XGBoost的参数概览 建议使用 max_depth=6 作为决策树的最大深度。在这里,2到10之间的任何值都可能是合理的(尽管这自然取决于你的问题)。
对于**学习率**,我们建议使用**对数均匀分布**在 1e-5 和 1e-1 之间:tune.loguniform(1e-5, 1e-1)。
对于 批量大小,我们建议尝试 2 的幂,例如,2, 4, 8, 16, 32, 64, 128, 256 等。大小取决于您的问题。对于数据量大的简单问题,使用较大的批量大小;对于数据量不多的复杂问题,使用较小的批量大小。
对于 层大小,我们也建议尝试 2的幂。对于小问题(例如 Cartpole),使用较小的层大小。对于较大的问题,尝试较大的层大小。
对于强化学习中的 折扣因子,我们建议在 0.9 到 1.0 之间均匀采样。根据问题的不同,一个更严格的范围,例如高于 0.97 甚至高于 0.99,可能是有意义的(例如,对于 Atari 游戏)。
如何使用嵌套/条件搜索空间?#
有时你可能需要定义依赖于其他参数值的参数。Ray Tune 提供了一些定义这些参数的方法。
嵌套空格#
你可以在子字典中嵌套超参数定义:
config = {"a": {"x": tune.uniform(0, 10)}, "b": tune.choice([1, 2, 3])}
试验配置将完全嵌套在输入配置中。
条件空间#
自定义和条件搜索空间在这里有详细解释。简而言之,你可以将自定义函数传递给 tune.sample_from(),这些函数可以返回依赖于其他值的值:
config = {
"a": tune.randint(5, 10),
"b": tune.sample_from(lambda spec: np.random.randint(0, spec.config.a)),
}
条件网格搜索#
如果你想对两个相互依赖的参数进行网格搜索,这可能无法直接实现。例如,假设 a 的值应在 5 到 10 之间,而 b 的值应在 0 到 a 之间。在这种情况下,我们不能使用 tune.sample_from,因为它不支持网格搜索。
这里的解决方案是借助一个辅助函数创建一个有效的 元组 列表,如下所示:
def _iter():
for a in range(5, 10):
for b in range(a):
yield a, b
config = {
"ab": tune.grid_search(list(_iter())),
}
然后,您的可训练对象可以执行类似 a, b = config["ab"] 的操作来拆分 a 和 b 变量并在之后使用它们。
早期终止(例如 Hyperband/ASHA)是如何工作的?#
早期终止算法会查看中间报告的值,例如在每个训练周期后通过 session.report() 报告给它们的值。在经过一定数量的步骤后,它们会移除表现最差的试验,只保留表现最好的试验。试验的好坏通过目标指标(如准确率或损失)进行排序来确定。
在 ASHA 中,您可以决定有多少试验被提前终止。reduction_factor=4 意味着每次减少时只保留所有试验的 25%。通过 grace_period=n,您可以强制 ASHA 至少训练每个试验 n 个周期。
为什么我所有的试验都返回“1”次迭代?#
这很可能适用于 Tune 函数 API。
Ray Tune 在每次调用 session.report() 时都会在内部计算迭代次数。如果你只在训练结束时调用一次 session.report(),计数器只会增加一次。如果你使用的是类 API,计数器会在调用 step() 后增加。
请注意,报告指标的频率可能比一次更有意义。例如,如果你训练你的算法1000个时间步,考虑每100步报告一次中间性能值。这样,像Hyperband/ASHA这样的调度器可以提前终止表现不佳的试验。
这些额外的输出是什么?#
你会注意到 Ray Tune 不仅报告超参数(来自 config)或指标(传递给 session.report()),还报告一些其他输出。
Result for easy_objective_c64c9112:
date: 2020-10-07_13-29-18
done: false
experiment_id: 6edc31257b564bf8985afeec1df618ee
experiment_tag: 7_activation=tanh,height=-53.116,steps=100,width=13.885
hostname: ubuntu
iterations: 0
iterations_since_restore: 1
mean_loss: 4.688385317424468
neg_mean_loss: -4.688385317424468
node_ip: 192.168.1.115
pid: 5973
time_since_restore: 7.605552673339844e-05
time_this_iter_s: 7.605552673339844e-05
time_total_s: 7.605552673339844e-05
timestamp: 1602102558
timesteps_since_restore: 0
training_iteration: 1
trial_id: c64c9112
参见 如何在 Tune 中使用日志指标? 部分以获取术语表。
如何设置资源?#
如果你想为某个试验分配特定的资源,你可以使用 tune.with_resources 并将其包裹在你的可训练对象周围,同时使用一个字典或一个 PlacementGroupFactory 对象:
tuner = tune.Tuner(
tune.with_resources(
train_fn, resources={"cpu": 2, "gpu": 0.5, "custom_resources": {"hdd": 80}}
),
)
tuner.fit()
上面的例子展示了三件事:
cpu和gpu选项分别设置每个试验可用的CPU和GPU数量。**试验不能请求超过这些的资源**(例外:见3)。可以请求 部分GPU。值为0.5表示将GPU一半的内存分配给试验。您需要确保您的模型仍然适合部分内存。
您可以在启动集群时请求您提供给 Ray 的自定义资源。试验将仅安排在能够提供您请求的所有资源的单个节点上。
需要记住的一件重要事情是,每个 Ray 工作者(以及每个 Ray Tune 试验)将只会在 一台机器 上调度。这意味着,例如,如果你为一个试验请求了 2 个 GPU,但你的集群由 4 台每台有 1 个 GPU 的机器组成,该试验将永远不会被调度。
换句话说,您需要确保您的 Ray 集群拥有能够实际满足您资源请求的机器。
在某些情况下,您的可训练对象可能希望启动其他远程执行者,例如,如果您通过 Ray Train 利用分布式训练。在这些情况下,您可以使用 放置组 来请求额外的资源:
tuner = tune.Tuner(
tune.with_resources(
train_fn,
resources=tune.PlacementGroupFactory(
[
{"CPU": 2, "GPU": 0.5, "hdd": 80},
{"CPU": 1},
{"CPU": 1},
],
strategy="PACK",
),
)
)
tuner.fit()
在这里,您为远程任务请求了2个额外的CPU。这两个额外的执行者不一定必须与您的主可训练对象位于同一节点上。实际上,您可以通过``strategy``参数来控制这一点。在这个例子中,``PACK``将尝试将执行者安排在同一节点上,但也允许它们被安排在其他节点上。请参阅 放置组文档 以了解更多关于这些放置策略的信息。
你也可以通过lambda函数根据自定义规则为试验分配特定资源。例如,如果你想根据参数空间中的设置为试验分配GPU资源:
tuner = tune.Tuner(
tune.with_resources(
train_fn,
resources=lambda config: {"GPU": 1} if config["use_gpu"] else {"GPU": 0},
),
param_space={
"use_gpu": True,
},
)
tuner.fit()
为什么我的训练卡住了,Ray 报告说待处理的执行者或任务无法调度?#
这通常是由于 Ray 角色或任务在可训练资源未对其进行计数的情况下由可训练对象启动,从而导致死锁。这也可能是由于在可训练对象中使用了基于 Ray 的其他库(如 Modin)而“隐秘地”导致的。为了解决这个问题,请使用上述部分中概述的 放置组 为试验请求额外的资源。
例如,如果你的可训练对象正在使用 Modin 数据框,对这些数据框的操作将生成 Ray 任务。通过为试验分配额外的 CPU 资源包,这些任务将能够在不被资源匮乏的情况下运行。
def train_fn(config):
# some Modin operations here
# import modin.pandas as pd
train.report({"metric": metric})
tuner = tune.Tuner(
tune.with_resources(
train_fn,
resources=tune.PlacementGroupFactory(
[
{"CPU": 1}, # this bundle will be used by the trainable itself
{"CPU": 1}, # this bundle will be used by Modin
],
strategy="PACK",
),
)
)
tuner.fit()
如何将更多参数值传递给我的可训练对象?#
Ray Tune 期望你的可训练函数最多接受两个参数,config 和 checkpoint_dir。但有时你可能希望传递常量参数,比如运行的 epoch 数量,或用于训练的数据集。Ray Tune 提供了一个包装函数来实现这一点,称为 tune.with_parameters():
from ray import tune
import numpy as np
def train_func(config, num_epochs=5, data=None):
for i in range(num_epochs):
for sample in data:
# ... train on sample
pass
# Some huge dataset
data = np.random.random(size=100000000)
tuner = tune.Tuner(tune.with_parameters(train_func, num_epochs=5, data=data))
tuner.fit()
此函数的工作方式类似于 functools.partial,但它直接将参数存储在 Ray 对象存储中。这意味着即使传递像数据集这样的巨大对象,Ray 也能确保这些对象在集群机器上高效地存储和检索。
tune.with_parameters() 也适用于类训练器。更多详情和示例请参见 tune.with_parameters()。
我如何复现实验?#
重现实验和实验结果意味着当你反复运行一个实验时,你会得到完全相同的结果。为了实现这一点,每次运行实验的条件必须完全相同。在机器学习训练和调优方面,这主要涉及用于训练和调优生命周期中各个地方采样的随机数生成器。
随机数生成器用于创建随机性,例如为定义的参数采样超参数值。计算中没有真正的随机性,而是有复杂的算法生成看似随机的数字,并满足随机分布的所有属性。这些算法可以用初始状态进行 种子化 ,之后生成的随机数总是相同的。
import random
random.seed(1234)
output = [random.randint(0, 100) for _ in range(10)]
# The output will always be the same.
assert output == [99, 56, 14, 0, 11, 74, 4, 85, 88, 10]
Python库中最常用的随机数生成器是原生 random 子模块和 numpy.random 模块中的那些。
# This should suffice to initialize the RNGs for most Python-based libraries
import random
import numpy as np
random.seed(1234)
np.random.seed(5678)
在你的调优和训练运行中,有几个地方会发生随机性,在这些地方我们都必须引入种子以确保我们得到相同的行为。
搜索算法:搜索算法需要在每次运行时生成相同的超参数配置,因此需要进行种子设定。一些搜索算法可以通过在构造函数中明确指定随机种子(查找
seed参数)来实例化。对于其他算法,尝试使用上述代码块。调度器:像基于种群的训练这样的调度器依赖于对某些参数进行重采样,这需要随机性。使用上面的代码块来设置初始种子。
训练函数:除了初始化配置外,训练函数本身还必须使用种子。这可能涉及到例如数据分割。你应该确保在训练函数开始时设置种子。
PyTorch 和 TensorFlow 使用它们自己的随机数生成器(RNGs),这些生成器也需要初始化:
import torch
torch.manual_seed(0)
import tensorflow as tf
tf.random.set_seed(0)
因此,您应该同时为 Ray Tune 的调度器和搜索算法以及训练代码设置种子。调度器和搜索算法应始终使用相同的种子进行初始化。对于训练代码也是如此,但通常在 不同的训练运行 之间使用不同的种子是有益的。
以下是关于如何在训练代码中实现这一切的蓝图:
import random
import numpy as np
from ray import tune
def trainable(config):
# config["seed"] is set deterministically, but differs between training runs
random.seed(config["seed"])
np.random.seed(config["seed"])
# torch.manual_seed(config["seed"])
# ... training code
config = {
"seed": tune.randint(0, 10000),
# ...
}
if __name__ == "__main__":
# Set seed for the search algorithms/schedulers
random.seed(1234)
np.random.seed(1234)
# Don't forget to check if the search alg has a `seed` parameter
tuner = tune.Tuner(trainable, param_space=config)
tuner.fit()
请注意,并非总是能够控制所有非确定性的来源。例如,如果你使用像ASHA或PBT这样的调度器,某些试验可能会比其他试验更早完成,从而影响调度器的行为。哪些试验首先完成可能取决于当前的系统负载、网络通信或其他我们无法通过随机种子控制的环境因素。对于贝叶斯优化等搜索算法也是如此,这些算法在采样新配置时会考虑之前的结果。这可以通过使用PBT和Hyperband的**同步模式**来解决,在这些模式中,调度器会等待所有试验完成一个epoch后再决定提升哪些试验。
我们强烈建议在依赖它进行更大规模的实验之前,先在小型的玩具问题上尝试重现。
我如何避免瓶颈?#
有时你可能会遇到这样的消息:
The `experiment_checkpoint` operation took 2.43 seconds to complete, which may be a performance bottleneck
最常见的是,experiment_checkpoint 操作会抛出此警告,但也可能是其他操作,例如 process_trial_result。
这些操作通常应在500毫秒内完成。如果持续时间更长,这可能表明存在问题或效率低下。要消除此消息,重要的是要了解其来源。
这些问题出现的主要原因如下:
试验配置非常大
如果你尝试通过 config 参数传递数据集或其他大型对象,就会出现这种情况。如果是这种情况,数据集会在实验检查点期间被序列化并多次写入磁盘,这会花费很长时间。
解决方案:使用 tune.with_parameters 通过对象存储将大型对象传递给函数可训练对象。对于类可训练对象,您可以通过 ray.put() 和 ray.get() 手动完成此操作。如果您需要传递类定义,请考虑传递一个指示符(例如字符串),并让可训练对象选择类。通常,您的配置字典应仅包含原始类型,如数字或字符串。
审判结果非常大
如果你通过类可训练对象中的 step() 方法的返回值或函数可训练对象中的 session.report() 返回对象、数据或其他大型对象,就会出现这种情况。其效果与上述相同:结果会被反复序列化并写入磁盘,这可能会花费很长时间。
解决方案:通过将数据写入可训练对象的当前工作目录来使用检查点。根据您是使用类还是函数式可训练API,有多种方法可以实现这一点。
你正在集群上训练大量试验,或者你正在保存巨大的检查点
解决方案:您可以使用 云检查点 将日志和检查点保存到指定的 storage_path。这是处理此问题的首选方法。所有同步操作都将自动处理,因为所有节点都能够访问云存储。此外,您的结果将是安全的,因此即使您在使用可抢占实例时,也不会丢失任何数据。
你报告结果的频率过高
每个结果都由搜索算法、试验调度器和回调函数(包括日志记录器和试验同步器)处理。如果你每试验报告大量结果(例如每秒多个结果),这可能需要很长时间。
解决方案:这里的解决方案很明显:只需减少报告结果的频率。在类训练中,step() 可能应该处理更大块的数据。在函数训练中,您可以只在训练循环的每第 n 次迭代时报告结果。尝试平衡您真正需要的结果数量以进行调度或搜索决策。如果您需要更细粒度的指标用于日志记录或跟踪,请考虑为此使用单独的日志记录机制,而不是 Ray Tune 提供的进度日志记录结果。
如何在本地开发和测试 Tune?#
首先,按照 构建 Ray (仅限 Python) 中的说明开发 Tune,而无需编译 Ray。设置好 Ray 后,运行 pip install -r ray/python/ray/tune/requirements-dev.txt 以安装 Tune 开发所需的所有包。现在,要运行所有 Tune 测试,只需运行:
pytest ray/python/ray/tune/tests/
如果你计划提交一个拉取请求,我们建议你在本地先运行单元测试,以加快审查过程。尽管我们有钩子自动为每个拉取请求运行单元测试,但通常先在你的机器上运行它们以避免任何明显的错误会更快。
我如何开始为 Tune 做贡献?#
我们使用 Github 来跟踪问题、功能请求和错误。查看标记为 “good first issue” 和 “help wanted” 的问题,作为开始的地方。寻找标题中带有 “[tune]” 的问题。
备注
如果提出与 Tune 相关的新问题或 PR,请确保在标题中包含“[tune]”,并添加一个 tune 标签。
对于项目组织,Tune 在 Tune Github 项目板 上保持了相对最新的问题组织。在这里,您可以跟踪和识别问题的组织方式。
如何使我的 Tune 实验可重复?#
机器学习运行的完全可重复性很难实现。在分布式环境中,这一点尤为明显,因为引入了更多的不确定性。例如,如果两个试验同时完成,搜索算法的收敛可能会受到哪个试验结果先被处理的影响。这取决于搜索器——对于随机搜索,这不应产生差异,但对于大多数其他搜索器来说,情况将有所不同。
如果你试图实现一定程度的可重复性,你需要在两个地方设置随机种子:
在驱动程序上,例如用于搜索算法。这将确保至少搜索算法建议的初始配置是相同的。
在可训练(如果需要)。神经网络通常用随机数初始化,许多经典的ML算法,如GBDTs,也利用了随机性。因此,您需要确保在这里设置一个种子,以便初始化始终相同。
这是一个总是会产生相同结果的例子(除了试验运行时间)。
import numpy as np
from ray import train, tune
def train_func(config):
# Set seed for trainable random result.
# If you remove this line, you will get different results
# each time you run the trial, even if the configuration
# is the same.
np.random.seed(config["seed"])
random_result = np.random.uniform(0, 100, size=1).item()
train.report({"result": random_result})
# Set seed for Ray Tune's random search.
# If you remove this line, you will get different configurations
# each time you run the script.
np.random.seed(1234)
tuner = tune.Tuner(
train_func,
tune_config=tune.TuneConfig(
num_samples=10,
search_alg=tune.search.BasicVariantGenerator(),
),
param_space={"seed": tune.randint(0, 1000)},
)
tuner.fit()
一些搜索器使用它们自己的随机状态来采样新的配置。这些搜索器通常接受一个 seed 参数,可以在初始化时传递。其他搜索器使用 Numpy 的 np.random 接口 - 这些种子可以通过 np.random.seed() 来设置。我们没有在搜索器类中提供一个接口来执行此操作,因为全局设置随机种子可能会产生副作用。例如,它可能会影响数据集的分割方式。因此,我们将其留给用户来进行这些全局配置更改。
如何在 Tune 中使用大型数据集?#
你通常会希望在驱动程序上计算一个大型对象(例如,训练数据、模型权重),并在每个试验中使用该对象。
Tune 提供了一个包装函数 tune.with_parameters(),它允许你将大型对象广播到你的可训练对象。通过此包装器传递的对象将存储在 Ray 对象存储 中,并将自动获取并作为参数传递给你的可训练对象。
from ray import train, tune
import numpy as np
def f(config, data=None):
pass
# use data
data = np.random.random(size=100000000)
tuner = tune.Tuner(tune.with_parameters(f, data=data))
tuner.fit()
我如何将我的 Tune 结果上传到云存储?#
参见 使用云存储(AWS S3,Google Cloud Storage)配置Tune。
确保工作节点对云存储有写入权限。未能做到这一点会导致类似 错误信息 (1): 致命错误: 无法定位凭证 的错误信息。对于 AWS 设置,这涉及到为工作节点添加 IamInstanceProfile 配置。请 参见此处获取更多提示。
我如何使用 Tune 与 Kubernetes?#
你应该配置共享存储。请参阅此用户指南:如何在 Ray Tune 中配置持久存储。
我如何使用 Tune 与 Docker?#
你应该配置共享存储。请参阅此用户指南:如何在 Ray Tune 中配置持久存储。
如何配置搜索空间?#
你可以通过传递给 Tuner(param_space=...) 的字典来指定网格搜索或采样分布。
parameters = {
"qux": tune.sample_from(lambda spec: 2 + 2),
"bar": tune.grid_search([True, False]),
"foo": tune.grid_search([1, 2, 3]),
"baz": "asd", # a constant value
}
tuner = tune.Tuner(train_fn, param_space=parameters)
tuner.fit()
默认情况下,每个随机变量和网格搜索点只采样一次。要进行多次随机采样,请在实验配置中添加 num_samples: N。如果提供了 grid_search 作为参数,网格将被重复 num_samples 次。
# num_samples=10 repeats the 3x3 grid search 10 times, for a total of 90 trials
tuner = tune.Tuner(
train_fn,
run_config=train.RunConfig(
name="my_trainable",
),
param_space={
"alpha": tune.uniform(100, 200),
"beta": tune.sample_from(lambda spec: spec.config.alpha * np.random.normal()),
"nn_layers": [
tune.grid_search([16, 64, 256]),
tune.grid_search([16, 64, 256]),
],
},
tune_config=tune.TuneConfig(
num_samples=10,
),
)
请注意,搜索空间在不同的搜索算法之间可能不具有互操作性。例如,对于许多搜索算法,您将无法使用 grid_search 或 sample_from 参数。请在 搜索空间 API 页面中阅读有关此内容的更多信息。
如何在 Tune 训练函数中访问相对文件路径?#
假设你从 ~/code 内部使用 my_script.py 启动了一个 Tune 实验。默认情况下,Tune 会将每个工作者的当前工作目录更改为其相应的试验目录(例如 ~/ray_results/exp_name/trial_0000x)。这确保了每个工作者进程都有单独的工作目录,避免了在保存试验特定输出时的冲突。
你可以通过设置 RAY_CHDIR_TO_TRIAL_DIR=0 环境变量来配置这个。这明确告诉 Tune 不要将工作目录更改为试验目录,从而允许访问相对于原始工作目录的路径。一个需要注意的是,工作目录现在在工作者之间共享,因此应使用 train.get_context().get_trial_dir() API 来获取保存试验特定输出的路径。
def train_func(config):
# Read from relative paths
print(open("./read.txt").read())
# The working directory shouldn't have changed from the original
# NOTE: The `TUNE_ORIG_WORKING_DIR` environment variable is deprecated.
assert os.getcwd() == os.environ["TUNE_ORIG_WORKING_DIR"]
# Write to the Tune trial directory, not the shared working dir
tune_trial_dir = Path(train.get_context().get_trial_dir())
with open(tune_trial_dir / "write.txt", "w") as f:
f.write("trial saved artifact")
os.environ["RAY_CHDIR_TO_TRIAL_DIR"] = "0"
tuner = tune.Tuner(train_func)
tuner.fit()
警告
TUNE_ORIG_WORKING_DIR 环境变量是访问相对于原始工作目录路径的原始解决方案。此环境变量已被弃用,应改用上述 RAY_CHDIR_TO_TRIAL_DIR 环境变量。
如何在同一个集群上同时运行多个 Ray Tune 作业(多租户)?#
在同一集群上同时运行多个 Ray Tune 运行是不被官方支持的。我们不测试这种工作流程,我们建议为每个调优作业使用一个单独的集群。
其原因如下:
当多个 Ray Tune 作业同时运行时,它们会竞争资源。一个作业可能会同时运行其所有试验,而另一个作业则需要等待很长时间,直到获得资源来运行第一个试验。
如果在您的基础设施上启动一个新的 Ray 集群很容易,那么运行一个大型集群而不是多个较小的集群通常没有成本优势。例如,运行一个包含 32 个实例的集群所产生的成本几乎与运行 4 个每个包含 8 个实例的集群相同。
并发作业更难调试。如果作业 A 的试验填满了磁盘,同一节点上作业 B 的试验也会受到影响。实际上,如果出现问题,很难从日志中推断出这些条件。
之前,Ray Tune 中的一些内部实现假设你一次只运行一个任务。一个症状是当来自任务 A 的试验使用了任务 B 中指定的参数,导致意外的结果。
如果您遇到此问题,请参考 [这个 GitHub 问题](ray-project/ray#30091) 以获取更多上下文和解决方法。
如何继续训练一个已经完成的 Tune 实验,使其运行更长时间并使用新的配置(迭代实验)?#
假设我有一个Tune实验已经完成,其配置如下:
import os
import tempfile
import torch
from ray import train, tune
from ray.train import Checkpoint
import random
def trainable(config):
for epoch in range(1, config["num_epochs"]):
# Do some training...
with tempfile.TemporaryDirectory() as tempdir:
torch.save(
{"model_state_dict": {"x": 1}}, os.path.join(tempdir, "model.pt")
)
train.report(
{"score": random.random()},
checkpoint=Checkpoint.from_directory(tempdir),
)
tuner = tune.Tuner(
trainable,
param_space={"num_epochs": 10, "hyperparam": tune.grid_search([1, 2, 3])},
tune_config=tune.TuneConfig(metric="score", mode="max"),
)
result_grid = tuner.fit()
best_result = result_grid.get_best_result()
best_checkpoint = best_result.checkpoint
现在,我想从一个由之前的实验生成的检查点(例如,最好的那个)继续训练,并在一个新的超参数搜索空间中进行搜索,再训练 10 个周期。
如何在 Ray Tune 中启用容错 解释说,使用 Tuner.restore 的目的是为了恢复一个在中间被中断的 未完成 实验,根据初始训练运行中提供的 确切配置。
因此,Tuner.restore 不适合我们的期望行为。这种“迭代实验”的方式应该通过 新 的 Tune 实验来完成,而不是反复恢复并修改单个实验的规范。
请参见以下示例,了解如何创建一个基于旧实验的新实验:
import ray
def trainable(config):
# Add logic to handle the initial checkpoint.
checkpoint: Checkpoint = config["start_from_checkpoint"]
with checkpoint.as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
# Initialize a model from the checkpoint...
# model = ...
# model.load_state_dict(model_state_dict)
for epoch in range(1, config["num_epochs"]):
# Do some more training...
...
train.report({"score": random.random()})
new_tuner = tune.Tuner(
trainable,
param_space={
"num_epochs": 10,
"hyperparam": tune.grid_search([4, 5, 6]),
"start_from_checkpoint": best_checkpoint,
},
tune_config=tune.TuneConfig(metric="score", mode="max"),
)
result_grid = new_tuner.fit()