可视化基于人群的训练 (PBT) 超参数优化#
假设: 读者对PBT算法有基本的了解,并希望更深入地探讨,并验证使用Ray的PBT实现的基础算法行为。本指南提供了获得一些背景知识的资源。
本教程将通过一个简单的例子,帮助您更好地理解在使用PBT进行算法调优时,PBT在幕后做了什么。请点击上方的火箭🚀图标启动笔记本,跟随操作。
我们将学习如何:
为PBT设置检查点和加载,使用可训练接口函数
配置Tune和PBT调度程序参数
可视化PBT算法行为以获得一些直观理解
设置玩具示例#
我们将使用的玩具示例优化问题来自PBT论文(有关更多详细信息,请参见图2)。目标是找到最大化二次函数的参数,同时仅访问依赖于一组超参数的估计器。一个实际的例子是最大化模型对所有可能输入的(未知)泛化能力,而只访问模型的经验损失,这依赖于超参数进行优化。
我们将从一些导入开始。
!pip install -U "ray[tune]"
注意:如果您在 Colab 上运行,请通过左侧的文件资源管理器将 这个辅助文件 复制到您的 Colab 挂载中,命名为 pbt_visualization_utils.py。
import numpy as np
import matplotlib.pyplot as plt
import os
import pickle
import tempfile
import time
import ray
from ray import train, tune
from ray.train import Checkpoint, FailureConfig, RunConfig
from ray.tune.schedulers import PopulationBasedTraining
from ray.tune.tune_config import TuneConfig
from ray.tune.tuner import Tuner
from pbt_visualization_utils import (
get_init_theta,
plot_parameter_history,
plot_Q_history,
make_animation,
)
具体来说,我们将使用论文中提供的定义(经过非常小的修改)来优化我们尝试优化的函数,以及我们所得到的估计器。
以下是我们将在示例中使用的概念列表,以及它们在实践中可能的类比:
示例中的概念 |
描述 |
实际类比 |
|---|---|---|
|
我们将在训练循环中更新的模型参数。 |
神经网络参数 |
|
PBT将优化的超参数。 |
学习率、批量大小等。 |
|
我们尝试最大化的二次函数。 |
对所有输入的泛化能力 |
|
我们得到的作为训练目标的估计器,依赖于( |
经验损失/奖励 |
下面是代码中的实现。
def Q(theta):
return 1.2 - (3 / 4 * theta[0] ** 2 + theta[1] ** 2)
def Qhat(theta, h):
return 1.2 - (h[0] * theta[0] ** 2 + h[1] * theta[1] ** 2)
def grad_Qhat(theta, h):
theta_grad = -2 * h * theta
theta_grad[0] *= 3 / 4
h_grad = -np.square(theta)
h_grad[0] *= 3 / 4
return {"theta": theta_grad, "h": h_grad}
theta_0 = get_init_theta()
print("Initial parameter values: theta = ", theta_0)
Initial parameter values: theta = [0.9 0.9]
定义可训练的函数#
我们将定义训练循环:
加载超参数配置
初始化模型,如果存在检查点,则从检查点恢复(这对于PBT很重要,因为当实验被利用时,调度程序将频繁暂停和恢复实验)。
运行训练循环并进行检查点。
def train_func(config):
# 加载Tuner传入的超参数配置
h0 = config.get("h0")
h1 = config.get("h1")
h = np.array([h0, h1]).astype(float)
lr = config.get("lr")
train_step = 1
checkpoint_interval = config.get("checkpoint_interval", 1)
# 初始化模型参数
theta = get_init_theta()
# 如果存在检查点,则加载它。
# This checkpoint could be a trial's own checkpoint to resume,
# or another trial's checkpoint placed by PBT that we will exploit
checkpoint = train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as checkpoint_dir:
with open(os.path.join(checkpoint_dir, "checkpoint.pkl"), "rb") as f:
checkpoint_dict = pickle.load(f)
# 加载模型(theta)
theta = checkpoint_dict["theta"]
last_step = checkpoint_dict["train_step"]
train_step = last_step + 1
# 主要训练循环(试验停止配置将在稍后进行)
while True:
# 执行梯度上升步骤
param_grads = grad_Qhat(theta, h)
theta_grad = np.asarray(param_grads["theta"])
theta = theta + lr * theta_grad
# 定义我们在试验结果中所需的定制指标
result = {
"Q": Q(theta),
"theta0": theta[0],
"theta1": theta[1],
"h0": h0,
"h1": h1,
"train_step": train_step,
}
# 每 `checkpoint_interval` 步进行一次检查点保存
should_checkpoint = train_step % checkpoint_interval == 0
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
if should_checkpoint:
checkpoint_dict = {
"h": h,
"train_step": train_step,
"theta": theta,
}
with open(
os.path.join(temp_checkpoint_dir, "checkpoint.pkl"), "wb"
) as f:
pickle.dump(checkpoint_dict, f)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
# 报告本次训练迭代的指标,并包含
# 包含当前参数的试验检查点
# 保存此列车步骤
train.report(result, checkpoint=checkpoint)
train_step += 1
备注
由于PBT会不断从最新的检查点恢复,因此在可训练函数中正确保存和加载train_step非常重要。确保如上所示,将加载的train_step增加一。 这样可以避免重复迭代,从而导致检查点和扰动间隔不同步。
配置 PBT 和调谐器#
我们首先初始化 ray(如果之前存在会话,则关闭它)。
if ray.is_initialized():
ray.shutdown()
ray.init()
2022-09-14 11:43:32,337 INFO worker.py:1517 -- Started a local Ray instance.
Ray
| Python version: | 3.8.13 |
| Ray version: | 3.0.0.dev0 |
创建PBT调度器#
perturbation_interval = 4
pbt_scheduler = PopulationBasedTraining(
time_attr="training_iteration",
perturbation_interval=perturbation_interval,
metric="Q",
mode="max",
quantile_fraction=0.5,
resample_probability=0.5,
hyperparam_mutations={
"lr": tune.qloguniform(5e-3, 1e-1, 5e-4),
"h0": tune.uniform(0.0, 1.0),
"h1": tune.uniform(0.0, 1.0),
},
synch=True,
)
关于PBT配置的一些说明:
time_attr="training_iteration"结合perturbation_interval=4将决定一个试验是否应在每4个训练迭代中继续进行还是利用其他试验。metric="Q"和mode="max"指定了试验性能的排名方式。在这种情况下,表现良好的试验是报告最高Q指标的前50%的试验(由quantile_fraction=0.5设定)。请注意,我们也可以在TuneConfig中设置指标/模式。hyperparam_mutations指定学习率lr和其他超参数h0、h1应由PBT进行扰动,并定义了每个超参数的重采样分布(其中resample_probability=0.5意味着重采样和变异都有50%的概率发生)。synch=True意味着PBT将同步运行,这通过引入等待使算法变慢,但对于本教程而言,它产生了更易于理解的可视化效果。在同步PBT中,我们等到所有试验都达到下一个
perturbation_interval,以决定哪些试验应继续,哪些试验应暂停并从其他试验的检查点开始。在两个试验的情况下,这意味着每个perturbation_interval将使表现较差的试验利用表现较好的试验。在异步PBT中并非总是如此,因为试验会逐个报告结果并决定是否继续或利用。这意味着一个试验可能会决定自己是表现最佳的,并选择继续,因为其他试验尚未有机会报告更好的结果。因此,我们并不总是在每个
perturbation_interval中看到试验进行利用。
创建调优器#
tuner = Tuner(
train_func,
param_space={
"lr": 0.05,
"h0": tune.grid_search([0.0, 1.0]),
"h1": tune.sample_from(lambda spec: 1.0 - spec.config["h0"]),
"num_training_iterations": 100,
# 将 `checkpoint_interval` 与 `perturbation_interval` 匹配
"checkpoint_interval": perturbation_interval,
},
tune_config=TuneConfig(
num_samples=1,
# 在此配置中设置PBT调度器
scheduler=pbt_scheduler,
),
run_config=RunConfig(
stop={"training_iteration": 100},
failure_config=FailureConfig(max_failures=3),
),
)
备注
我们建议将 checkpoint_interval 与 PBT 配置中的 perturbation_interval 匹配。
这确保了 PBT 算法实际上利用了最近一次迭代中的试验。
如果您的 perturbation_interval 较大并且希望更频繁地进行检查点,请将 perturbation_interval 设置为 checkpoint_interval 的倍数。
关于 Tuner 配置的其他几点说明:
param_space指定了我们训练函数的 初始config输入。在两个值上的grid_search将启动两个试验,使用特定的超参数集,并且随着训练的进行,PBT 将继续修改它们。h0和h1的初始超参数设置被配置为产生两个试验,一个为h = [1, 0],另一个为h = [0, 1]。这与论文实验相匹配,并将用于与去掉 PBT 调度器的grid_search基线进行比较。
运行实验#
我们通过调用 Tuner.fit 来启动试验。
pbt_results = tuner.fit()
可视化结果#
使用一些辅助函数 来自这里,我们可以创建一些可视化图形来帮助我们理解PBT的训练进展。
fig, axs = plt.subplots(1, 2, figsize=(13, 6), gridspec_kw=dict(width_ratios=[1.5, 1]))
colors = ["black", "red"]
labels = ["h = [1, 0]", "h = [0, 1]"]
plot_parameter_history(
pbt_results,
colors,
labels,
perturbation_interval=perturbation_interval,
fig=fig,
ax=axs[0],
)
plot_Q_history(pbt_results, colors, labels, ax=axs[1])
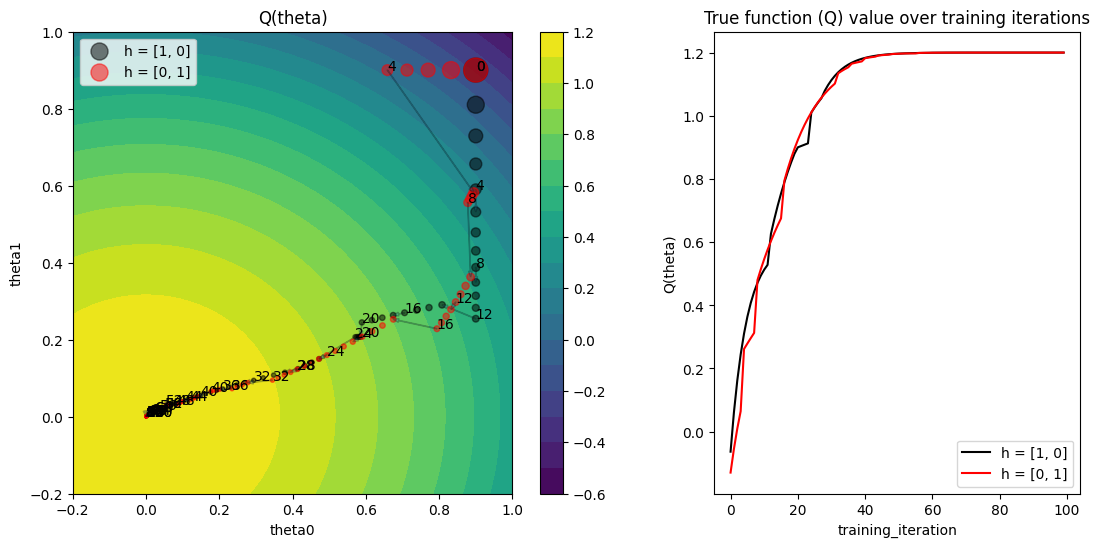
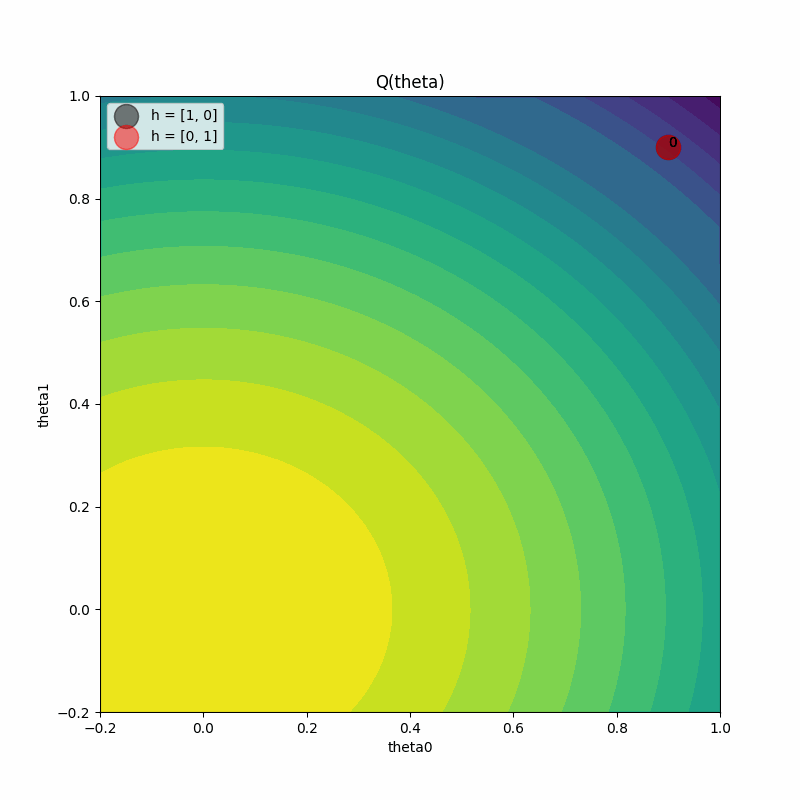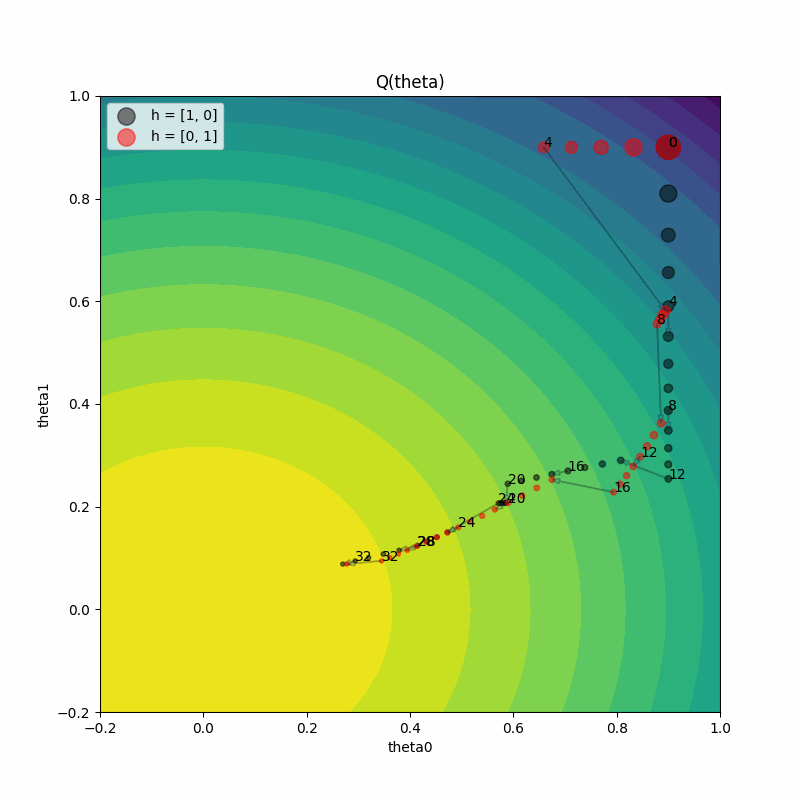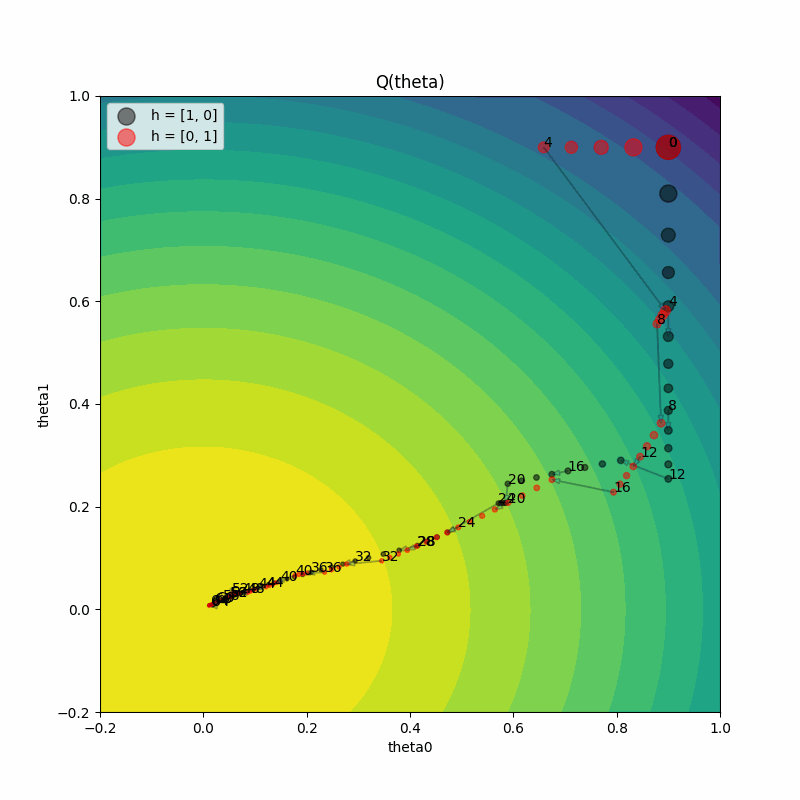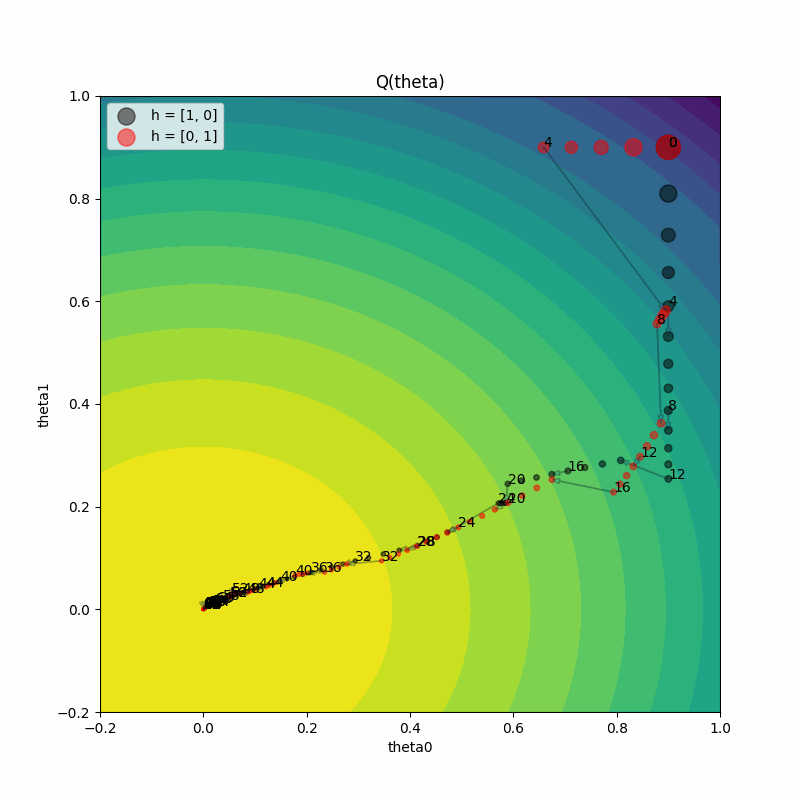
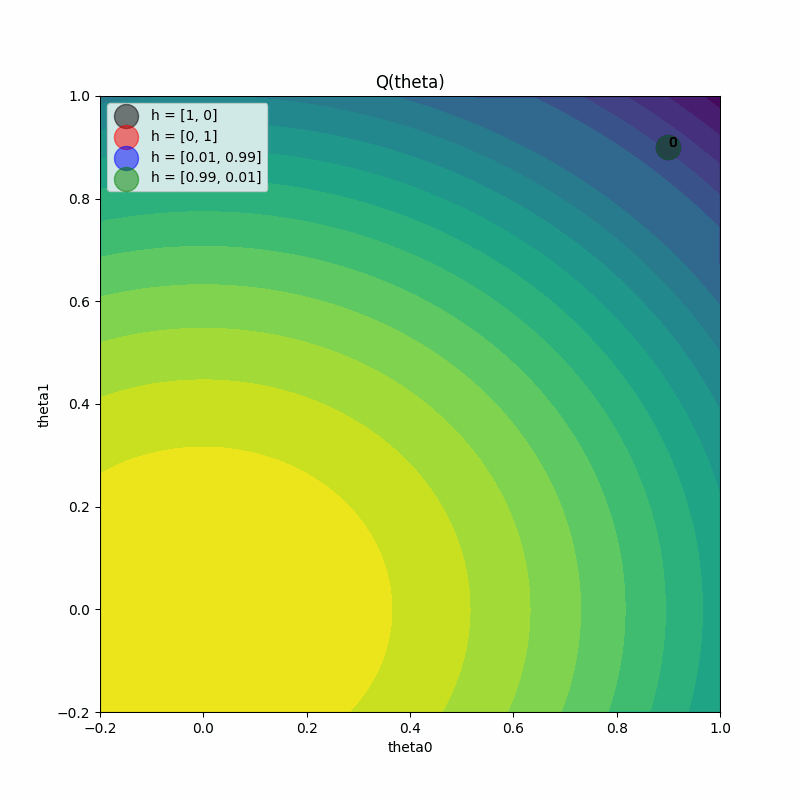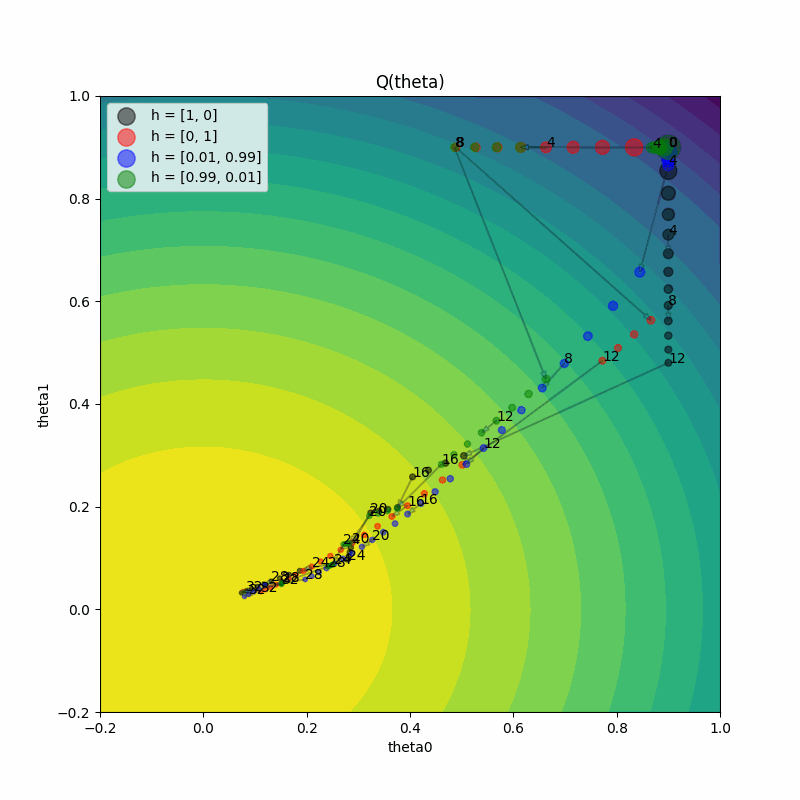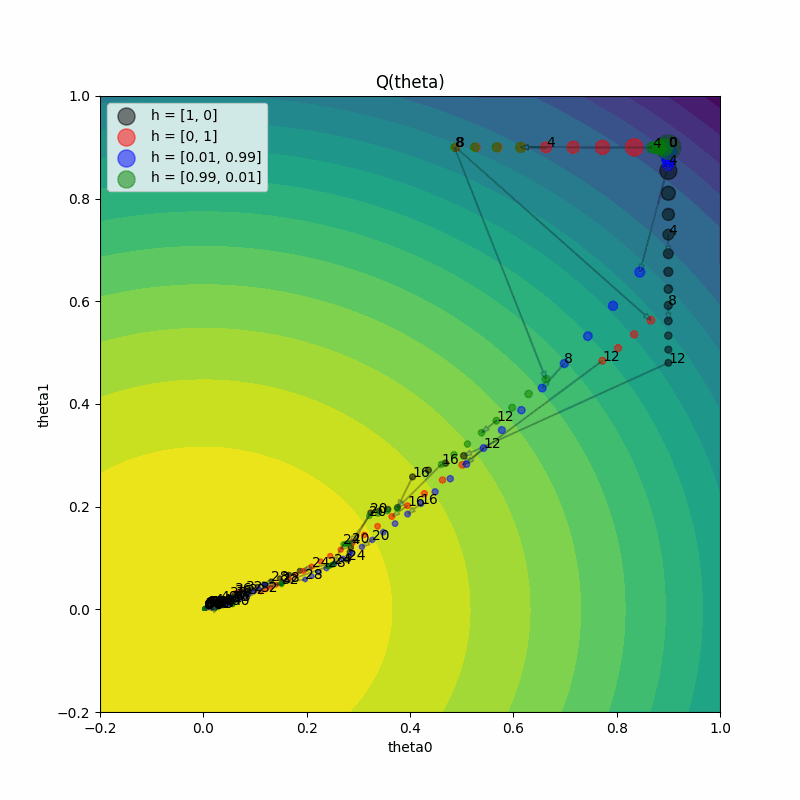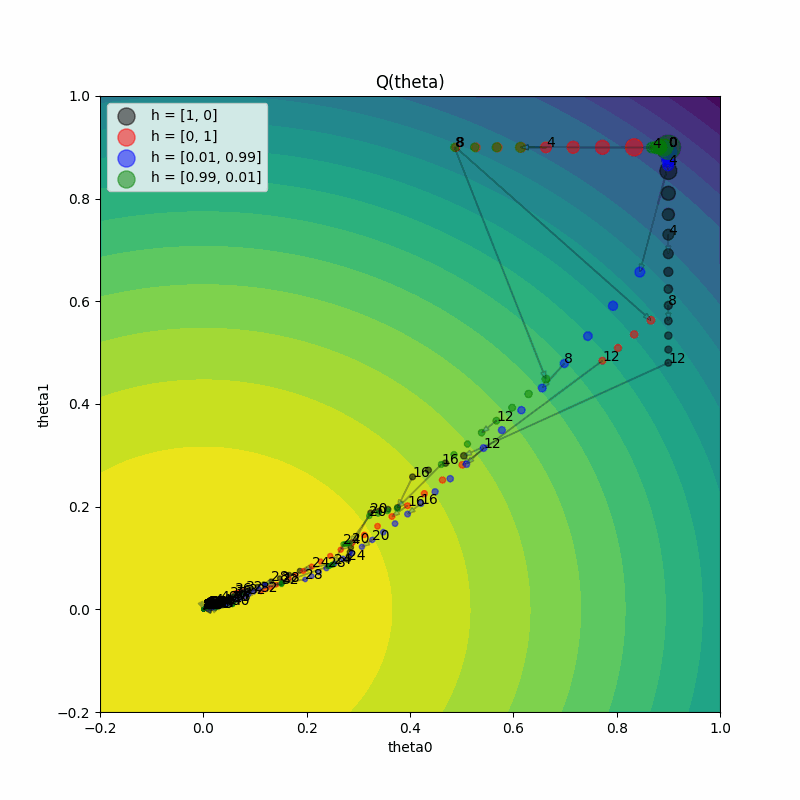
右侧的图显示了随着训练进展,两个试验的真实函数值 Q(theta)。两个试验都达到了最大值 1.2。
以下是如何理解左侧图表:
左侧的图显示了每次训练迭代中参数值
(theta0, theta1),适用于两个试验。随着训练迭代的增加,点的大小变得更小。我们在每个
perturbation_interval训练迭代的点旁边看到标注的迭代次数。让我们放大从第4次迭代到第5次迭代的过渡,观察两个试验的情况。我们看到一个试验要么 继续(请注意黑色试验从第4次到第5次就继续训练)要么 利用并扰动另一个试验,然后执行一个训练步骤(请注意红色试验从第4次到第5次跳到了黑色试验的参数值)。
在这一阶段,黑色试验的梯度方向也发生了变化,因为超参数在PBT的利用和探索步骤之间发生了改变。请记住,估计器
Qhat的梯度依赖于超参数(h0, h1)。训练迭代之间跳跃大小的变化表明学习率也在变化,因为我们将
lr包含在需要突变的超参数集合中。
动画化训练进度#
make_animation(
pbt_results,
colors,
labels,
perturbation_interval=perturbation_interval,
filename="pbt.gif",
)
我们还可以对训练进度进行动画处理,以观察模型参数在每一步的变化情况。
网格搜索比较#
本论文包括了对两个试验的网格搜索比较,使用与PBT实验相同的初始超参数配置(h = [1, 0], h = [0, 1])。下面代码的唯一区别是从TuneConfig中移除了PBT调度器。
if ray.is_initialized():
ray.shutdown()
ray.init()
tuner = Tuner(
train_func,
param_space={
"lr": tune.qloguniform(1e-2, 1e-1, 5e-3),
"h0": tune.grid_search([0.0, 1.0]),
"h1": tune.sample_from(lambda spec: 1.0 - spec.config["h0"]),
},
tune_config=TuneConfig(
num_samples=1,
metric="Q",
mode="max",
),
run_config=RunConfig(
stop={"training_iteration": 100},
failure_config=FailureConfig(max_failures=3),
),
)
grid_results = tuner.fit()
if grid_results.errors:
raise RuntimeError
正如我们所看到的,两个试验都没有达到最佳值,因为超参数配置停留在其原始值上。
fig, axs = plt.subplots(1, 2, figsize=(13, 6), gridspec_kw=dict(width_ratios=[1.5, 1]))
colors = ["black", "red"]
labels = ["h = [1, 0]", "h = [0, 1]"]
plot_parameter_history(
grid_results,
colors,
labels,
perturbation_interval=perturbation_interval,
fig=fig,
ax=axs[0],
)
plot_Q_history(grid_results, colors, labels, ax=axs[1])
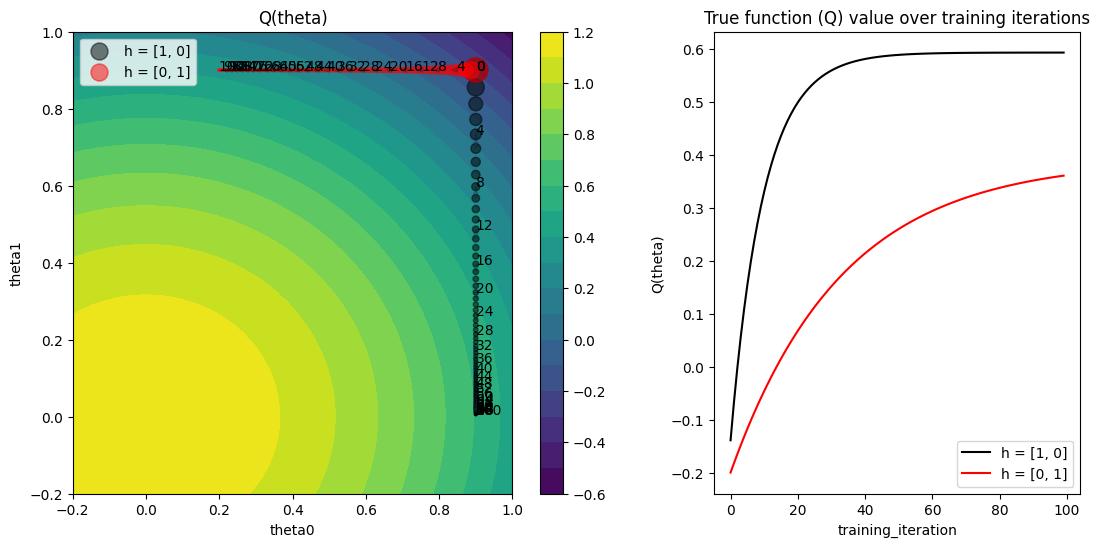
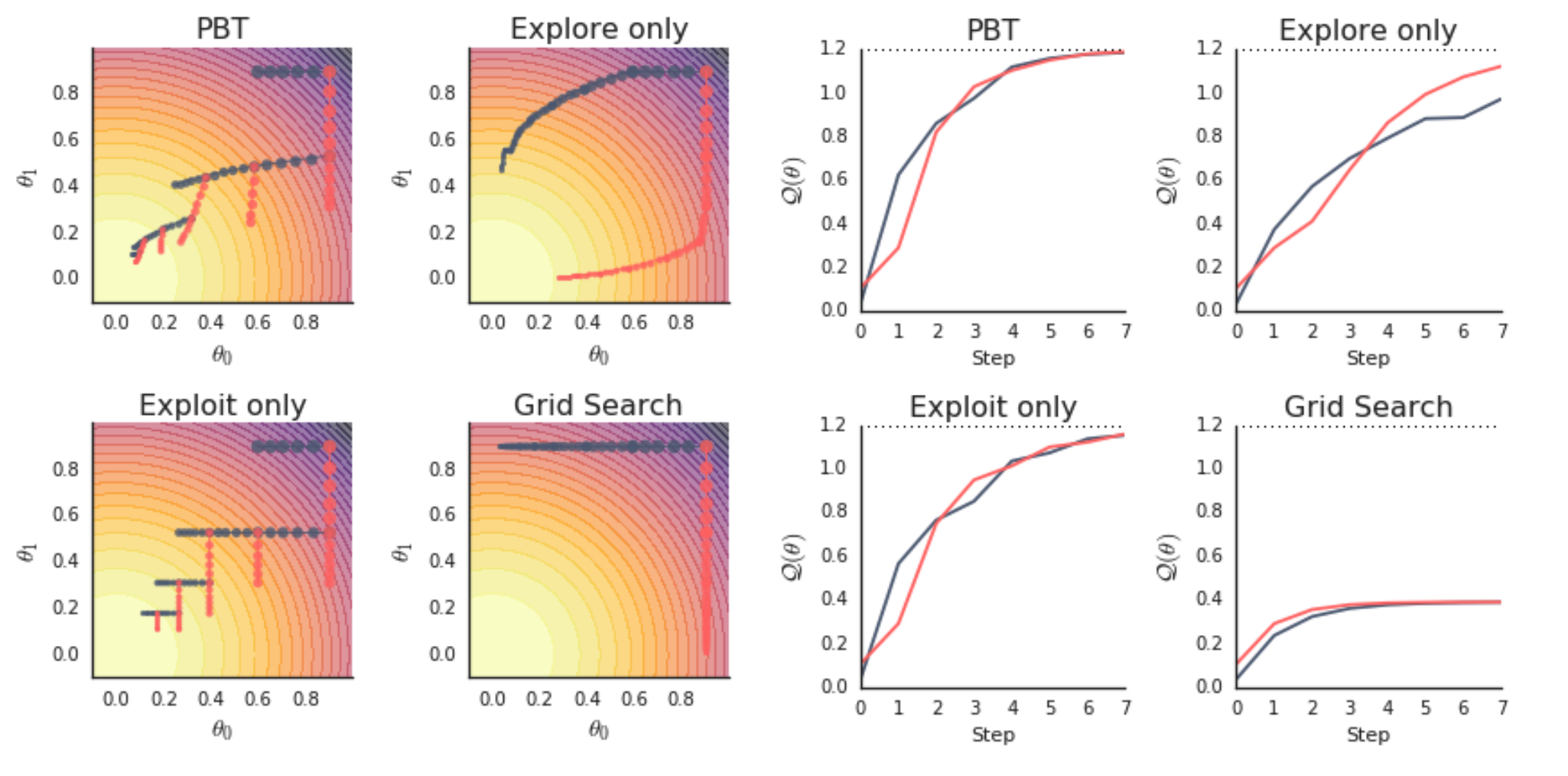
比较我们生成的两个图与PBT论文中的图2(特别是,我们生成了左上角和右下角的图)。
增加PBT种群规模#
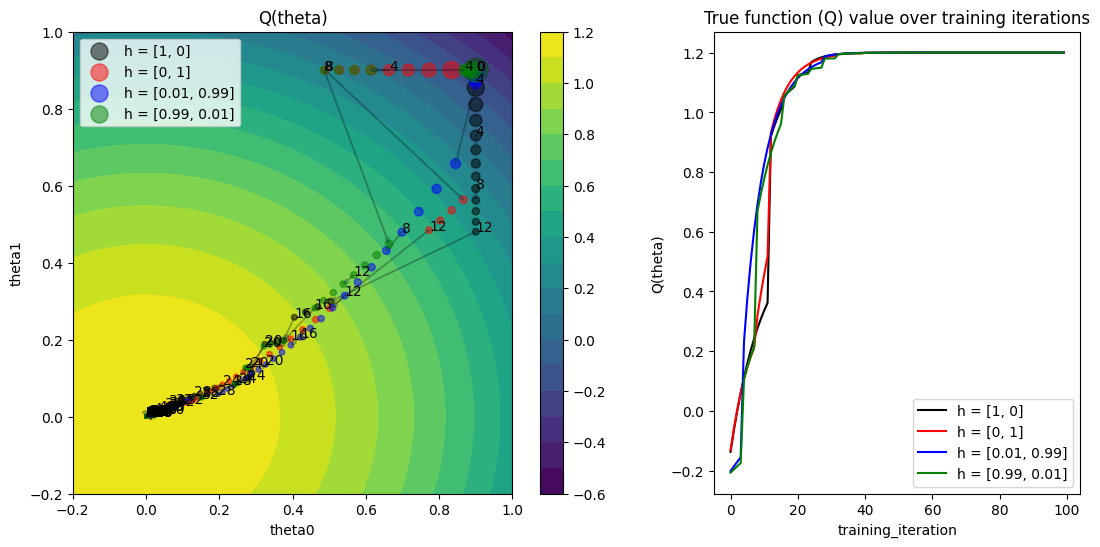
最后一个实验:如果我们增加PBT种群规模,会是什么样子?现在,表现较差的试验将从多个表现优异的试验中随机选择一个进行利用,这应该会导致一些更有趣的行为。
if ray.is_initialized():
ray.shutdown()
ray.init()
perturbation_interval = 4
pbt_scheduler = PopulationBasedTraining(
time_attr="training_iteration",
perturbation_interval=perturbation_interval,
quantile_fraction=0.5,
resample_probability=0.5,
hyperparam_mutations={
"lr": tune.qloguniform(5e-3, 1e-1, 5e-4),
"h0": tune.uniform(0.0, 1.0),
"h1": tune.uniform(0.0, 1.0),
},
synch=True,
)
tuner = Tuner(
train_func,
param_space={
"lr": tune.qloguniform(5e-3, 1e-1, 5e-4),
"h0": tune.grid_search([0.0, 1.0, 0.01, 0.99]), # 4项试验
"h1": tune.sample_from(lambda spec: 1.0 - spec.config["h0"]),
"num_training_iterations": 100,
"checkpoint_interval": perturbation_interval,
},
tune_config=TuneConfig(
num_samples=1,
metric="Q",
mode="max",
# 在此配置中设置PBT调度器
scheduler=pbt_scheduler,
),
run_config=RunConfig(
stop={"training_iteration": 100},
failure_config=FailureConfig(max_failures=3),
),
)
pbt_4_results = tuner.fit()
fig, axs = plt.subplots(1, 2, figsize=(13, 6), gridspec_kw=dict(width_ratios=[1.5, 1]))
colors = ["black", "red", "blue", "green"]
labels = ["h = [1, 0]", "h = [0, 1]", "h = [0.01, 0.99]", "h = [0.99, 0.01]"]
plot_parameter_history(
pbt_4_results,
colors,
labels,
perturbation_interval=perturbation_interval,
fig=fig,
ax=axs[0],
)
plot_Q_history(pbt_4_results, colors, labels, ax=axs[1])
make_animation(
pbt_4_results,
colors,
labels,
perturbation_interval=perturbation_interval,
filename="pbt4.gif",
)
摘要#
希望本指南能帮助您更好地理解PBT算法。如果在运行此笔记本时遇到任何问题,请提交问题,并在Ray Slack上提出您可能遇到的任何问题。