入门指南#
使用 Ray 在您的笔记本电脑或云端扩展应用程序。为您的任务选择正确的指南。
扩展机器学习工作负载:Ray 库快速入门
扩展通用 Python 应用程序:Ray Core 快速入门
部署到云端:Ray 集群快速开始
调试和监控应用程序:调试和监控快速入门
Ray AI 库快速入门#
为机器学习工作负载使用单独的库。点击下方的工作负载下拉菜单。
 数据:适用于机器学习的可扩展数据集
数据:适用于机器学习的可扩展数据集
使用 Ray Data 扩展离线推理和训练数据摄取 – 一个专为机器学习设计的数据处理库。
了解更多信息,请参阅 离线批量推理 和 数据预处理与机器学习训练的数据摄取。
备注
要运行此示例,请安装 Ray Data:
pip install -U "ray[data]"
from typing import Dict
import numpy as np
import ray
# Create datasets from on-disk files, Python objects, and cloud storage like S3.
ds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv")
# Apply functions to transform data. Ray Data executes transformations in parallel.
def compute_area(batch: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:
length = batch["petal length (cm)"]
width = batch["petal width (cm)"]
batch["petal area (cm^2)"] = length * width
return batch
transformed_ds = ds.map_batches(compute_area)
# Iterate over batches of data.
for batch in transformed_ds.iter_batches(batch_size=4):
print(batch)
# Save dataset contents to on-disk files or cloud storage.
transformed_ds.write_parquet("local:///tmp/iris/")
了解更多关于 Ray Data
训练:分布式模型训练
Ray Train 抽象了设置分布式训练系统的复杂性。
此示例展示了如何将 Ray Train 与 PyTorch 一起使用。
要运行此示例,请安装 Ray Train 和 PyTorch 包:
备注
pip install -U "ray[train]" torch torchvision
设置您的数据集和模型。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
def get_dataset():
return datasets.FashionMNIST(
root="/tmp/data",
train=True,
download=True,
transform=ToTensor(),
)
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, inputs):
inputs = self.flatten(inputs)
logits = self.linear_relu_stack(inputs)
return logits
现在定义你的单工作者 PyTorch 训练函数。
def train_func():
num_epochs = 3
batch_size = 64
dataset = get_dataset()
dataloader = DataLoader(dataset, batch_size=batch_size)
model = NeuralNetwork()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
pred = model(inputs)
loss = criterion(pred, labels)
loss.backward()
optimizer.step()
print(f"epoch: {epoch}, loss: {loss.item()}")
此训练函数可以通过以下方式执行:
train_func()
将其转换为分布式多工作者训练函数。
使用 ray.train.torch.prepare_model 和 ray.train.torch.prepare_data_loader 实用函数来为分布式训练设置您的模型和数据。这会自动将模型用 DistributedDataParallel 包装并放置在正确的设备上,并为 DataLoaders 添加 DistributedSampler。
import ray.train.torch
def train_func_distributed():
num_epochs = 3
batch_size = 64
dataset = get_dataset()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
dataloader = ray.train.torch.prepare_data_loader(dataloader)
model = NeuralNetwork()
model = ray.train.torch.prepare_model(model)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(num_epochs):
if ray.train.get_context().get_world_size() > 1:
dataloader.sampler.set_epoch(epoch)
for inputs, labels in dataloader:
optimizer.zero_grad()
pred = model(inputs)
loss = criterion(pred, labels)
loss.backward()
optimizer.step()
print(f"epoch: {epoch}, loss: {loss.item()}")
使用4个工作线程实例化一个 TorchTrainer ,并使用它来运行新的训练函数。
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig
# For GPU Training, set `use_gpu` to True.
use_gpu = False
trainer = TorchTrainer(
train_func_distributed,
scaling_config=ScalingConfig(num_workers=4, use_gpu=use_gpu)
)
results = trainer.fit()
本示例展示了如何使用 Ray Train 来设置 使用 Keras 进行多工作者训练。
要运行此示例,请安装 Ray Train 和 Tensorflow 包:
备注
pip install -U "ray[train]" tensorflow
设置您的数据集和模型。
import sys
import numpy as np
if sys.version_info >= (3, 12):
# Tensorflow is not installed for Python 3.12 because of keras compatibility.
sys.exit(0)
else:
import tensorflow as tf
def mnist_dataset(batch_size):
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
# The `x` arrays are in uint8 and have values in the [0, 255] range.
# You need to convert them to float32 with values in the [0, 1] range.
x_train = x_train / np.float32(255)
y_train = y_train.astype(np.int64)
train_dataset = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(60000).repeat().batch(batch_size)
return train_dataset
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(28, 28)),
tf.keras.layers.Reshape(target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
return model
现在定义你的单工作者 TensorFlow 训练函数。
def train_func():
batch_size = 64
single_worker_dataset = mnist_dataset(batch_size)
single_worker_model = build_and_compile_cnn_model()
single_worker_model.fit(single_worker_dataset, epochs=3, steps_per_epoch=70)
此训练函数可以通过以下方式执行:
train_func()
现在将其转换为分布式多工作者训练函数。
设置 全局 批量大小 - 每个工作进程处理与单工作进程代码中相同大小的批量。
选择你的 TensorFlow 分布式训练策略。此示例使用
MultiWorkerMirroredStrategy。
import json
import os
def train_func_distributed():
per_worker_batch_size = 64
# This environment variable will be set by Ray Train.
tf_config = json.loads(os.environ['TF_CONFIG'])
num_workers = len(tf_config['cluster']['worker'])
strategy = tf.distribute.MultiWorkerMirroredStrategy()
global_batch_size = per_worker_batch_size * num_workers
multi_worker_dataset = mnist_dataset(global_batch_size)
with strategy.scope():
# Model building/compiling need to be within `strategy.scope()`.
multi_worker_model = build_and_compile_cnn_model()
multi_worker_model.fit(multi_worker_dataset, epochs=3, steps_per_epoch=70)
使用4个工作线程实例化一个 TensorflowTrainer ,并使用它来运行新的训练函数。
from ray.train.tensorflow import TensorflowTrainer
from ray.train import ScalingConfig
# For GPU Training, set `use_gpu` to True.
use_gpu = False
trainer = TensorflowTrainer(train_func_distributed, scaling_config=ScalingConfig(num_workers=4, use_gpu=use_gpu))
trainer.fit()
了解更多关于 Ray Train
Tune: 大规模超参数调优
Tune 是一个用于任何规模的超参数调优的库。使用 Tune,你可以在不到 10 行代码中启动一个多节点分布式超参数扫描。Tune 支持任何深度学习框架,包括 PyTorch、TensorFlow 和 Keras。
备注
要运行此示例,请安装 Ray Tune:
pip install -U "ray[tune]"
此示例使用迭代训练函数运行一个小型网格搜索。
from ray import train, tune
def objective(config): # ①
score = config["a"] ** 2 + config["b"]
return {"score": score}
search_space = { # ②
"a": tune.grid_search([0.001, 0.01, 0.1, 1.0]),
"b": tune.choice([1, 2, 3]),
}
tuner = tune.Tuner(objective, param_space=search_space) # ③
results = tuner.fit()
print(results.get_best_result(metric="score", mode="min").config)
如果安装了 TensorBoard,自动可视化所有试验结果:
tensorboard --logdir ~/ray_results
了解更多关于 Ray Tune
Serve: 可扩展模型服务
Ray Serve 是一个基于 Ray 构建的可扩展模型服务库。
备注
要运行此示例,请安装 Ray Serve 和 scikit-learn:
pip install -U "ray[serve]" scikit-learn
此示例运行一个 scikit-learn 梯度提升分类器。
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")
# Query it!
sample_request_input = {"vector": [1.2, 1.0, 1.1, 0.9]}
response = requests.get(
"http://localhost:8000/iris", json=sample_request_input)
print(response.text)
结果你会看到 {"result": "versicolor"}。
了解更多关于 Ray Serve
RLlib: 行业级强化学习
RLlib 是一个基于 Ray 构建的强化学习(RL)工业级库。RLlib 提供了高扩展性和统一的 API,适用于各种工业和研究应用。
备注
要运行此示例,请安装 rllib 以及 tensorflow 或 pytorch:
pip install -U "ray[rllib]" tensorflow # or torch
import gymnasium as gym
from ray.rllib.algorithms.ppo import PPOConfig
# Define your problem using python and Farama-Foundation's gymnasium API:
class SimpleCorridor(gym.Env):
"""Corridor in which an agent must learn to move right to reach the exit.
---------------------
| S | 1 | 2 | 3 | G | S=start; G=goal; corridor_length=5
---------------------
Possible actions to chose from are: 0=left; 1=right
Observations are floats indicating the current field index, e.g. 0.0 for
starting position, 1.0 for the field next to the starting position, etc..
Rewards are -0.1 for all steps, except when reaching the goal (+1.0).
"""
def __init__(self, config):
self.end_pos = config["corridor_length"]
self.cur_pos = 0
self.action_space = gym.spaces.Discrete(2) # left and right
self.observation_space = gym.spaces.Box(0.0, self.end_pos, shape=(1,))
def reset(self, *, seed=None, options=None):
"""Resets the episode.
Returns:
Initial observation of the new episode and an info dict.
"""
self.cur_pos = 0
# Return initial observation.
return [self.cur_pos], {}
def step(self, action):
"""Takes a single step in the episode given `action`.
Returns:
New observation, reward, terminated-flag, truncated-flag, info-dict (empty).
"""
# Walk left.
if action == 0 and self.cur_pos > 0:
self.cur_pos -= 1
# Walk right.
elif action == 1:
self.cur_pos += 1
# Set `terminated` flag when end of corridor (goal) reached.
terminated = self.cur_pos >= self.end_pos
truncated = False
# +1 when goal reached, otherwise -1.
reward = 1.0 if terminated else -0.1
return [self.cur_pos], reward, terminated, truncated, {}
# Create an RLlib Algorithm instance from a PPOConfig object.
config = (
PPOConfig().environment(
# Env class to use (here: our gym.Env sub-class from above).
env=SimpleCorridor,
# Config dict to be passed to our custom env's constructor.
# Use corridor with 20 fields (including S and G).
env_config={"corridor_length": 28},
)
# Parallelize environment rollouts.
.env_runners(num_env_runners=3)
)
# Construct the actual (PPO) algorithm object from the config.
algo = config.build()
# Train for n iterations and report results (mean episode rewards).
# Since we have to move at least 19 times in the env to reach the goal and
# each move gives us -0.1 reward (except the last move at the end: +1.0),
# Expect to reach an optimal episode reward of `-0.1*18 + 1.0 = -0.8`.
for i in range(5):
results = algo.train()
print(f"Iter: {i}; avg. return={results['env_runners']['episode_return_mean']}")
# Perform inference (action computations) based on given env observations.
# Note that we are using a slightly different env here (len 10 instead of 20),
# however, this should still work as the agent has (hopefully) learned
# to "just always walk right!"
env = SimpleCorridor({"corridor_length": 10})
# Get the initial observation (should be: [0.0] for the starting position).
obs, info = env.reset()
terminated = truncated = False
total_reward = 0.0
# Play one episode.
while not terminated and not truncated:
# Compute a single action, given the current observation
# from the environment.
action = algo.compute_single_action(obs)
# Apply the computed action in the environment.
obs, reward, terminated, truncated, info = env.step(action)
# Sum up rewards for reporting purposes.
total_reward += reward
# Report results.
print(f"Played 1 episode; total-reward={total_reward}")
了解更多关于 Ray RLlib
Ray 核心快速入门#

使用简单的原语,轻松将函数和类转换为 Ray 任务和参与者,适用于 Python 和 Java,用于构建和运行分布式应用程序。
核心: 使用 Ray 任务并行化函数
备注
要运行此示例,请安装 Ray Core:
pip install -U "ray"
导入 Ray 并使用 ray.init() 初始化它。然后使用 @ray.remote 装饰函数,以声明你希望远程运行此函数。最后,使用 .remote() 调用函数,而不是正常调用。此远程调用会返回一个未来,即 Ray 的 对象引用,你可以使用 ray.get 获取它。
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures)) # [0, 1, 4, 9]
备注
要运行此示例,请在您的项目中添加 ray-api 和 ray-runtime 依赖项。
使用 Ray.init 初始化 Ray 运行时。然后使用 Ray.task(...).remote() 将任何 Java 静态方法转换为 Ray 任务。该任务在远程工作进程中异步运行。remote 方法返回一个 ObjectRef,你可以使用 get 获取实际结果。
import io.ray.api.ObjectRef;
import io.ray.api.Ray;
import java.util.ArrayList;
import java.util.List;
public class RayDemo {
public static int square(int x) {
return x * x;
}
public static void main(String[] args) {
// Intialize Ray runtime.
Ray.init();
List<ObjectRef<Integer>> objectRefList = new ArrayList<>();
// Invoke the `square` method 4 times remotely as Ray tasks.
// The tasks will run in parallel in the background.
for (int i = 0; i < 4; i++) {
objectRefList.add(Ray.task(RayDemo::square, i).remote());
}
// Get the actual results of the tasks.
System.out.println(Ray.get(objectRefList)); // [0, 1, 4, 9]
}
}
在上面的代码块中,我们定义了一些 Ray 任务。虽然这些对于无状态操作非常有用,但有时您必须维护应用程序的状态。您可以使用 Ray 角色来实现这一点。
了解更多关于 Ray Core
核心:使用 Ray Actors 并行化类
Ray 提供了 actors 来允许你在 Python 或 Java 中并行化一个类的实例。当你实例化一个 Ray actor 类时,Ray 将在集群中启动该类的远程实例。这个 actor 可以执行远程方法调用并维护其自己的内部状态。
备注
要运行此示例,请安装 Ray Core:
pip install -U "ray"
import ray
ray.init() # Only call this once.
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
[c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures)) # [1, 1, 1, 1]
备注
要运行此示例,请在您的项目中添加 ray-api 和 ray-runtime 依赖项。
import io.ray.api.ActorHandle;
import io.ray.api.ObjectRef;
import io.ray.api.Ray;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class RayDemo {
public static class Counter {
private int value = 0;
public void increment() {
this.value += 1;
}
public int read() {
return this.value;
}
}
public static void main(String[] args) {
// Intialize Ray runtime.
Ray.init();
List<ActorHandle<Counter>> counters = new ArrayList<>();
// Create 4 actors from the `Counter` class.
// They will run in remote worker processes.
for (int i = 0; i < 4; i++) {
counters.add(Ray.actor(Counter::new).remote());
}
// Invoke the `increment` method on each actor.
// This will send an actor task to each remote actor.
for (ActorHandle<Counter> counter : counters) {
counter.task(Counter::increment).remote();
}
// Invoke the `read` method on each actor, and print the results.
List<ObjectRef<Integer>> objectRefList = counters.stream()
.map(counter -> counter.task(Counter::read).remote())
.collect(Collectors.toList());
System.out.println(Ray.get(objectRefList)); // [1, 1, 1, 1]
}
}
了解更多关于 Ray Core
Ray 集群快速入门#
在AWS、GCP、Azure等Ray集群上部署您的应用程序,通常只需对现有代码进行最小的更改。
集群:在 AWS 上启动 Ray 集群
Ray 程序可以在单台机器上运行,也可以无缝扩展到大型集群。
备注
要运行此示例,请安装以下内容:
pip install -U "ray[default]" boto3
如果你还没有配置,请按照 https://boto3.amazonaws.com/v1/documentation/api/latest/guide/credentials.html#guide-credentials[boto3 文档] 中的描述配置你的凭证。
以这个简单的例子为例,它等待单个节点加入集群。
你也可以从 GitHub 仓库 下载这个示例。将其存储在本地一个名为 example.py 的文件中。
要在云中执行此脚本,请下载 此配置文件,或在此处复制它:
假设你已经将此配置存储在一个名为 cluster.yaml 的文件中,你现在可以按如下方式启动一个 AWS 集群:
ray submit cluster.yaml example.py --start
了解更多关于在AWS、GCP、Azure等平台上启动Ray集群的信息
集群:在 Kubernetes 上启动 Ray 集群
Ray 程序可以在单节点 Kubernetes 集群上运行,也可以无缝扩展到更大的集群。
了解更多关于在 Kubernetes 上启动 Ray 集群的信息
调试与监控快速入门#
使用内置的可观测性工具来监控和调试 Ray 应用程序和集群。
Ray 仪表盘:用于监控和调试 Ray 的 Web GUI
Ray 仪表板提供了一个可视化界面,显示实时系统指标、节点级资源监控、作业分析和任务可视化。该仪表板旨在帮助用户了解其 Ray 应用程序的性能并识别潜在问题。
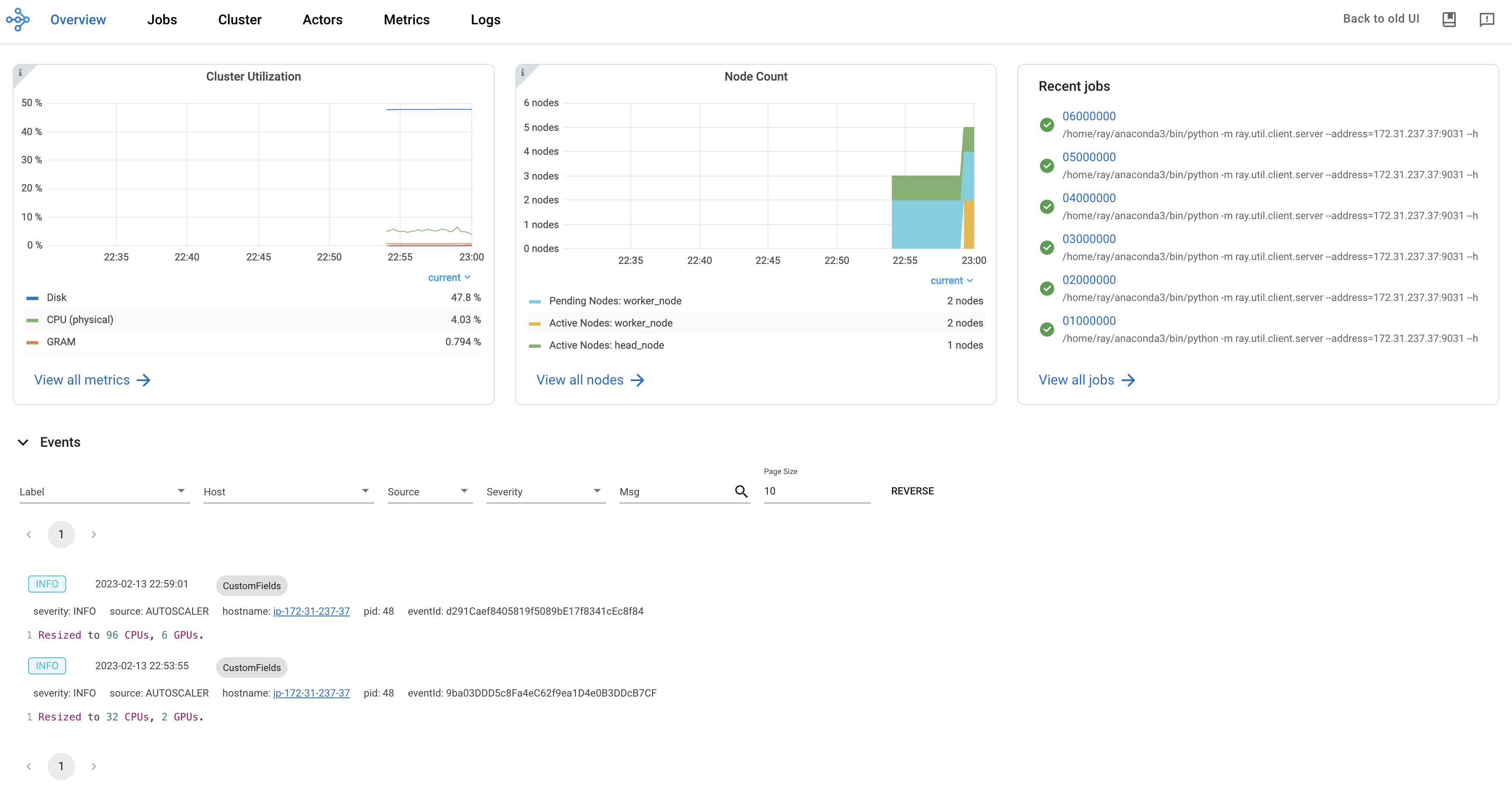
备注
要开始使用仪表板,请按如下方式安装默认安装:
pip install -U "ray[default]"
通过默认URL访问仪表板,http://localhost:8265。
了解更多关于 Ray 仪表盘的内容
Ray 状态 API:访问集群状态的 CLI
Ray 状态 API 允许用户通过 CLI 或 Python SDK 方便地访问 Ray 的当前状态(快照)。
备注
要开始使用状态API,请按照以下方式安装默认安装:
pip install -U "ray[default]"
运行以下代码。
import ray
import time
ray.init(num_cpus=4)
@ray.remote
def task_running_300_seconds():
print("Start!")
time.sleep(300)
@ray.remote
class Actor:
def __init__(self):
print("Actor created")
# Create 2 tasks
tasks = [task_running_300_seconds.remote() for _ in range(2)]
# Create 2 actors
actors = [Actor.remote() for _ in range(2)]
ray.get(tasks)
使用 ray summary tasks 查看 Ray 任务的汇总统计数据。
ray summary tasks
======== Tasks Summary: 2022-07-22 08:54:38.332537 ========
Stats:
------------------------------------
total_actor_scheduled: 2
total_actor_tasks: 0
total_tasks: 2
Table (group by func_name):
------------------------------------
FUNC_OR_CLASS_NAME STATE_COUNTS TYPE
0 task_running_300_seconds RUNNING: 2 NORMAL_TASK
1 Actor.__init__ FINISHED: 2 ACTOR_CREATION_TASK
了解更多关于 Ray State API
了解更多#
以下是一些涉及 Ray 及其库的演讲、论文和媒体报道。如果以下链接中有任何损坏,或者您想添加自己的演讲,请提出问题!