备注
Ray 2.10.0 引入了 RLlib 的“新 API 栈”的 alpha 阶段。Ray 团队计划将算法、示例脚本和文档迁移到新的代码库中,从而在 Ray 3.0 之前的后续小版本中逐步替换“旧 API 栈”(例如,ModelV2、Policy、RolloutWorker)。
然而,请注意,到目前为止,只有 PPO(单代理和多代理)和 SAC(仅单代理)支持“新 API 堆栈”,并且默认情况下继续使用旧 API 运行。您可以继续使用现有的自定义(旧堆栈)类。
请参阅此处 以获取有关如何使用新API堆栈的更多详细信息。
关键概念#
在本页中,我们将介绍关键概念,以帮助您理解RLlib的工作原理以及如何使用它。在RLlib中,您使用 Algorithm 来学习如何解决 environments 问题。算法使用 policies 来选择动作。给定一个策略, environment 中的 rollouts 会产生经验的 sample batches (或 trajectories )。您还可以自定义RL实验的 training_step 。
环境#
解决RL中的问题始于一个**环境**。在RL的最简单定义中:
一个 智能体 与一个 环境 交互并接收一个奖励。
RL 中的环境是代理的世界,它是对要解决的问题的模拟。
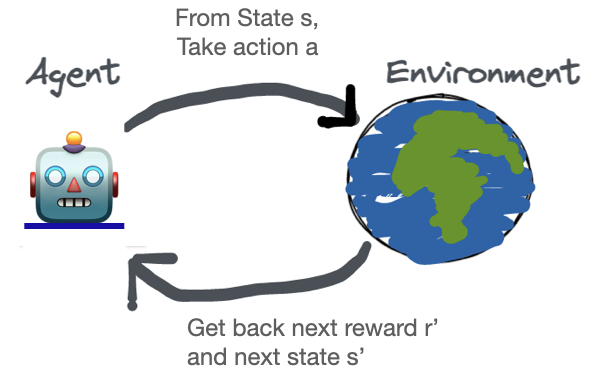
一个 RLlib 环境包括:
所有可能的动作 (动作空间)
环境的完整描述,没有任何隐藏(状态空间)
代理对状态的某些部分进行的观察(观察空间)
奖励,这是智能体每次行动唯一收到的反馈。
试图最大化所有未来奖励之和的模型被称为 策略。策略是一个将环境的观察映射到要采取的行动的函数,通常写作 π (s(t)) -> a(t)。下面是强化学习迭代学习过程的示意图。
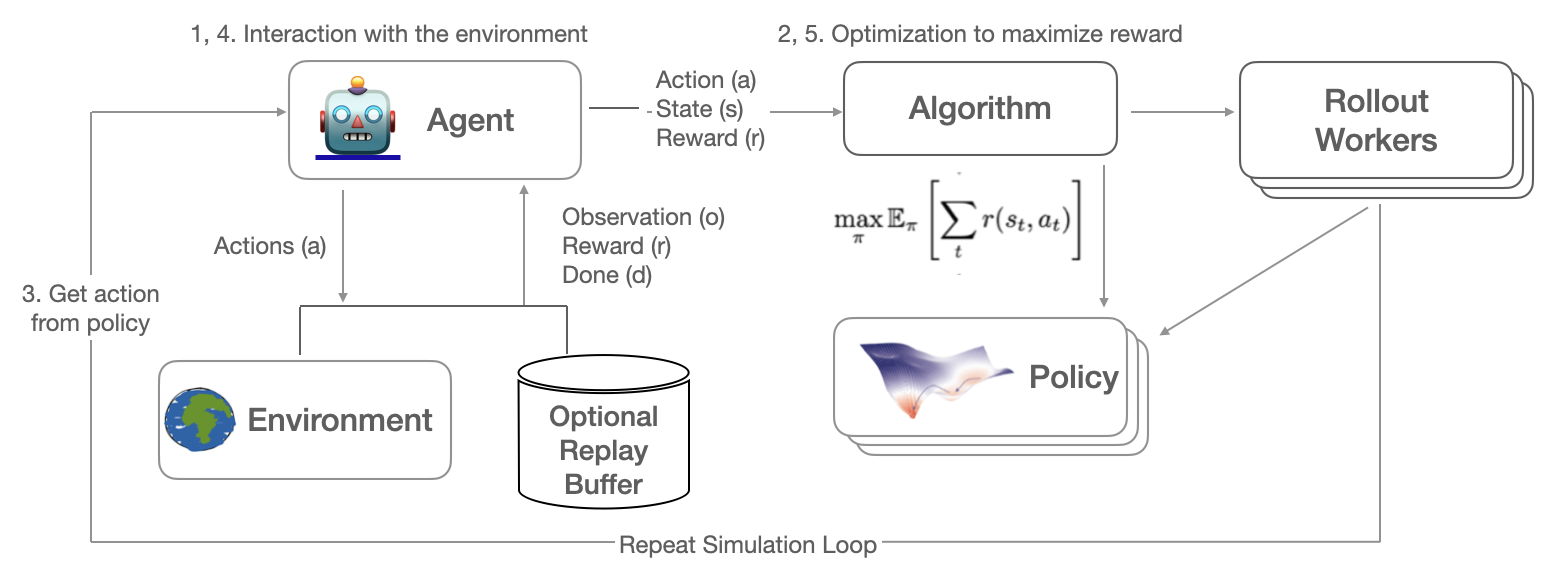
RL 模拟反馈循环反复收集数据,对于单个(单智能体情况)或多个(多智能体情况)策略,基于这些收集的数据训练策略,并确保策略的权重保持同步。因此,收集的环境数据包含观察结果、采取的行动、收到的奖励以及所谓的 完成 标志,这些标志指示了智能体在模拟中通过的不同剧集的边界。
动作 -> 奖励 -> 下一状态 -> 训练 -> 重复,直到结束状态,这被称为一个 回合 ,或者在 RLlib 中,称为一个 回滚 。定义环境的最常见 API 是 Farama-Foundation Gymnasium API,这也是我们在大多数示例中使用的 API。
算法#
算法将所有 RLlib 组件结合在一起,使得通过 RLlib 的 Python API 可以轻松学习不同的任务。每个 Algorithm 类都由其相应的 AlgorithmConfig 管理,例如,要配置一个 PPO 实例,您应该使用 PPOConfig 类。Algorithm 设置其回滚工作者和优化器,并收集训练指标。Algorithms 还实现了 Tune Trainable API,以便于实验管理。
你有三种方式与算法交互。你可以使用基本的 Python API 或命令行来训练它,或者你可以使用 Ray Tune 来调整强化学习算法的超参数。以下示例展示了与 PPO 交互的三种等效方式,PPO 在 RLlib 中实现了近端策略优化算法。
# Configure.
from ray.rllib.algorithms.ppo import PPOConfig
config = PPOConfig().environment(env="CartPole-v1").training(train_batch_size=4000)
# Build.
algo = config.build()
# Train.
print(algo.train())
from ray import tune
# Configure.
from ray.rllib.algorithms.ppo import PPOConfig
config = PPOConfig().environment(env="CartPole-v1").training(train_batch_size=4000)
# Train via Ray Tune.
tune.run("PPO", config=config)
RLlib 算法类 协调运行回放和优化策略的分布式工作流程。算法类利用并行迭代器来实现所需的计算模式。下图展示了 同步采样 ,这是 这些模式 中最简单的一种:

同步采样(例如,A2C、PG、PPO)#
RLlib 使用 Ray actors 来将训练从单个核心扩展到集群中的数千个核心。你可以通过更改 num_env_runners 参数来 配置训练所用的并行度。更多详情请参见此 扩展指南。
RL 模块#
RLModules 是特定于框架的神经网络容器。简而言之,它们携带神经网络并定义在强化学习的三个阶段中如何使用它们:探索、推理和训练。一个最小的 RL Module 可以包含一个单一的神经网络,并定义其探索、推理和训练逻辑,仅将观察结果映射到动作。由于 RL Modules 可以将观察结果映射到动作,它们自然地在 RLlib 中实现了强化学习策略,因此可以在 RolloutWorker 中找到它们,在那里它们的探索和推理逻辑用于从环境中采样。RLlib 中 RL Modules 常见的第二个地方是 Learner,在那里它们的训练逻辑用于训练神经网络。RL Modules 扩展到多智能体情况,其中单个 MultiRLModule 包含多个 RL Modules。下图是上述内容在实践中可能的粗略草图:
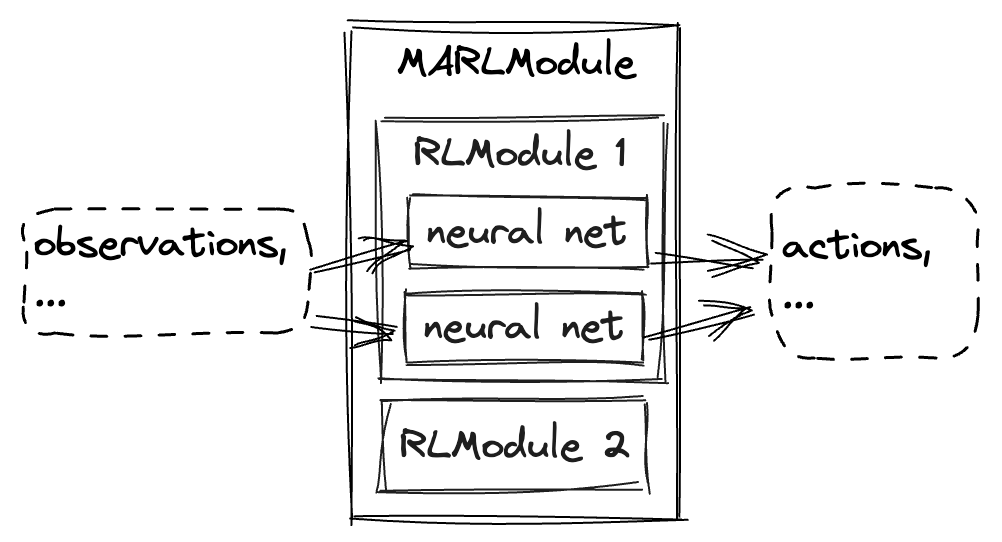
备注
RL 模块目前处于 alpha 阶段。它们被封装在旧版 Policy 对象中,以便在 RolloutWorker 中用于采样。这对用户应该是透明的,但以下 策略评估 部分仍然提到这些旧版策略对象。
策略评估#
给定一个环境和策略,策略评估会产生 批次 的经验。这是经典的“环境交互循环”。高效的策略评估可能难以正确实现,尤其是在利用向量化、RNN或在多智能体环境中操作时。RLlib 提供了一个 RolloutWorker 类来管理所有这些,并且这个类在大多数 RLlib 算法中被使用。
您可以使用独立的推出工作者来生成经验批次。这可以通过在工作者实例上调用 worker.sample() 来完成,或者在作为 Ray 角色的工作者实例上并行调用 ``worker.sample.remote()``(参见 EnvRunnerGroup)。
以下是一个创建一组推出工作线程并使用它们并行收集经验的示例。轨迹被连接起来,策略在轨迹批次上学习,然后我们将策略权重广播给工作线程以进行下一轮推出:
# Setup policy and rollout workers.
env = gym.make("CartPole-v1")
policy = CustomPolicy(env.observation_space, env.action_space, {})
workers = EnvRunnerGroup(
policy_class=CustomPolicy,
env_creator=lambda c: gym.make("CartPole-v1"),
num_env_runners=10)
while True:
# Gather a batch of samples.
T1 = SampleBatch.concat_samples(
ray.get([w.sample.remote() for w in workers.remote_workers()]))
# Improve the policy using the T1 batch.
policy.learn_on_batch(T1)
# The local worker acts as a "parameter server" here.
# We put the weights of its `policy` into the Ray object store once (`ray.put`)...
weights = ray.put({"default_policy": policy.get_weights()})
for w in workers.remote_workers():
# ... so that we can broacast these weights to all rollout-workers once.
w.set_weights.remote(weights)
样品批次#
无论是在单个进程中运行还是在一个 大型集群 中运行,RLlib 中的所有数据都以 样本批次 的形式进行交换。样本批次编码一个或多个轨迹片段。通常,RLlib 从回放缓存工作者收集大小为 rollout_fragment_length 的批次,并将一个或多个这样的批次连接成大小为 train_batch_size 的批次,这是 SGD 的输入。
一个典型的样本批次在总结时看起来如下所示。由于所有值都保存在数组中,这允许在网络上进行高效的编码和传输:
sample_batch = { 'action_logp': np.ndarray((200,), dtype=float32, min=-0.701, max=-0.685, mean=-0.694),
'actions': np.ndarray((200,), dtype=int64, min=0.0, max=1.0, mean=0.495),
'dones': np.ndarray((200,), dtype=bool, min=0.0, max=1.0, mean=0.055),
'infos': np.ndarray((200,), dtype=object, head={}),
'new_obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.018),
'obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.016),
'rewards': np.ndarray((200,), dtype=float32, min=1.0, max=1.0, mean=1.0),
't': np.ndarray((200,), dtype=int64, min=0.0, max=34.0, mean=9.14)
}
在 多智能体模式 中,样本批次是分别为每个单独的策略收集的。这些批次被包装在一起形成一个 MultiAgentBatch ,作为各个智能体样本批次的容器。
训练步骤方法 (Algorithm.training_step())#
备注
在阅读本节之前,对基本的 ray 核心方法 有良好的理解是非常重要的。此外,我们使用了诸如 SampleBatch``(及其更高级的兄弟:``MultiAgentBatch)、RolloutWorker 和 Algorithm 等概念,这些内容可以在本页和 rollout worker 参考文档 中阅读。
这是什么?#
Algorithm 类的 training_step() 方法定义了任何算法核心的可重复执行逻辑。可以将其视为研究论文中算法伪代码的 Python 实现。您可以使用 training_step() 来表达如何协调从环境中收集样本、将这些数据移动到算法的其他部分,以及在不同分布式组件之间更新和管理策略权重的操作。
简而言之,如果开发者想要对现有算法进行自定义修改、从头编写自己的算法,或实现某篇论文中的算法,他们需要重写/修改 ``training_step`` 方法。
training_step() 何时被调用?#
Algorithm 的 training_step() 方法被调用:
当调用
Algorithm的train()方法时(例如,由构建了Algorithm实例的用户“手动”调用)。当一个 RLlib 算法由 Ray Tune 运行时,
training_step()将持续被调用,直到满足 ray tune 停止标准。
关键子概念#
在下文中,我们将以 VPG(“vanilla policy gradient”)为例,尝试说明如何使用 training_step() 方法在 RLlib 中实现该算法。VPG 算法可以被视为一系列重复的步骤,或称为 数据流:
采样(从环境中收集数据)
更新策略(以学习行为)
广播更新后的策略权重(以确保所有分布式单元再次拥有相同的权重)
指标报告(返回与性能和运行时相关的所有上述操作的相关统计数据)
VPG 的一个示例实现可能如下所示:
def training_step(self) -> ResultDict:
# 1. Sampling.
train_batch = synchronous_parallel_sample(
worker_set=self.env_runner_group,
max_env_steps=self.config["train_batch_size"]
)
# 2. Updating the Policy.
train_results = train_one_step(self, train_batch)
# 3. Synchronize worker weights.
self.env_runner_group.sync_weights()
# 4. Return results.
return train_results
备注
请注意,training_step 方法是与深度学习框架无关的。这意味着你不应该在这个模块内编写特定于 PyTorch 或 TensorFlow 的代码,从而实现严格的责任分离,并使我们能够为算法的 TF 和 PyTorch 版本使用相同的 training_step() 方法。特定于 DL 框架的代码应仅添加到 :ref:`策略 <rllib-policy-walkthrough>`(例如在其损失函数中)和 :ref:`模型 <rllib-models-walkthrough>`(例如 tf.keras 或 torch.nn 神经网络代码)类中。
让我们进一步分解上面的 training_step() 代码。在第一步中,我们从环境中收集轨迹数据:
train_batch = synchronous_parallel_sample(
worker_set=self.env_runner_group,
max_env_steps=self.config["train_batch_size"]
)
在这里,self.env_runner_group 是一组在 Algorithm 的 setup() 方法中创建的 EnvRunners``(在调用 ``training_step() 之前)。这个 EnvRunnerGroup 在 EnvRunnerGroup 文档页面 中有更深入的介绍。实用函数 synchronous_parallel_sample 可以用于在多个回放缓存工作器之间以阻塞方式进行并行采样(一旦所有回放缓存工作器完成采样,即返回)。它返回一个最终的 MultiAgentBatch,该结果是通过连接 n 个较小的 MultiAgentBatches(每个远程回放缓存工作器恰好一个)得到的。
然后,train_batch 被传递给另一个实用函数:train_one_step。
train_results = train_one_step(self, train_batch)
像 train_one_step 和 multi_gpu_train_one_step 这样的方法用于训练我们的策略。更多带有示例的文档可以在 训练操作文档页面 找到。
策略的训练更新仅应用于 self.env_runner 内部的版本。请注意,每个 EnvRunnerGroup 有 n 个远程 EnvRunner 实例,并且恰好有一个“本地工作者”,所有 EnvRunner(远程和本地)都持有一个策略的副本。
既然我们已经更新了本地策略(位于 self.env_runner_group.local_env_runner 中的副本),我们需要确保所有远程工作者的副本(self.env_runner_group.remote_workers)的权重与本地副本同步:
self.env_runner_group.sync_weights()
通过调用 self.env_runner_group.sync_weights(),权重从本地工作器广播到远程工作器。更多详情请参阅 rollout worker 参考文档。
return train_results
预期返回一个包含训练更新结果的字典。它将类型为 str 的键映射到类型为 float 的值,或映射到相同形式的字典,从而允许嵌套结构。
例如,一个结果字典可以将 policy_ids 映射到该策略的学习和采样统计信息:
{
'policy_1': {
'learner_stats': {'policy_loss': 6.7291455},
'num_agent_steps_trained': 32
},
'policy_2': {
'learner_stats': {'policy_loss': 3.554927},
'num_agent_steps_trained': 32
},
}
训练步骤方法工具#
RLlib 提供了一系列工具,用于抽象化 RL 训练中的常见任务。特别是,如果你想使用各种 training_step 方法或实现自己的方法,建议首先熟悉以下概念:
样本批次: SampleBatch 和 MultiAgentBatch 是我们用于在 RLlib 中存储轨迹数据的两种类型。我们所有的 RLlib 抽象(策略、重放缓冲区等)都操作这两种类型。
Rollout Workers: Rollout workers 是一个封装了策略(或多智能体情况下的多个策略)和环境的抽象。从高层次来看,我们可以通过调用它们的 sample() 方法从环境中收集经验,并通过调用它们的 learn_on_batch() 方法来训练它们的策略。默认情况下,在 RLlib 中,我们创建一组可以用于采样和训练的 workers。我们在 setup 中创建了一个 EnvRunnerGroup 对象,当 RLlib 算法被创建时会调用这个 setup。EnvRunnerGroup 有一个 local_worker 和 remote_workers,如果实验配置中的 num_env_runners > 0。在 RLlib 中,我们通常使用 local_worker 进行训练,使用 remote_workers 进行采样。
训练操作: 这些是改进策略和更新工作者的方法。最基本的操作符 train_one_step 接收一批经验作为输入,并输出包含指标的 ResultDict。对于使用GPU进行训练,请使用 multi_gpu_train_one_step。这些方法使用回滚工作者的 learn_on_batch 方法来完成训练更新。