使用Ray进行高度可并行化任务#
虽然Ray可以用于非常复杂的并行化任务,但我们通常只想简单地并行处理一些事情。例如,我们可能有100,000个时间序列要使用完全相同的算法进行处理,每个序列的处理时间为一分钟。
显然,在单个处理器上运行这种任务是不可行的:这将需要70天。即使我们设法在一台机器上使用8个处理器,这也会缩短到9天。但如果我们可以使用8台每台有16个核心的机器,这件事大约可以在12小时内完成。
我们如何使用Ray来处理这些类型的任务呢?
我们以计算π的数字为简单示例。算法很简单:生成随机的x和y,如果x^2 + y^2 < 1,那么它就在圆内,我们就算它为“在内”。这实际上会得出π/4(记得你在高中学过的数学)。
以下代码(以及本笔记本)假设您已经设置好了Ray集群,并且您正在主节点上运行。有关如何设置Ray集群的更多详细信息,请参见Ray集群入门。
import ray
import random
import time
import math
from fractions import Fraction
# Let's start Ray
ray.init(address='auto')
我们使用 @ray.remote 装饰器来创建一个 Ray 任务。
任务类似于一个函数,不同之处在于结果是异步返回的。
它也可能不会在本地机器上运行,而是在集群的其他地方运行。
这样,你可以并行运行多个任务,超出你在单台机器上可以拥有的处理器数量的限制。
@ray.remote
def pi4_sample(sample_count):
"""pi4_sample 运行 sample_count 次实验,并返回圆内次数占总次数的比例。
"""
in_count = 0
for i in range(sample_count):
x = random.random()
y = random.random()
if x*x + y*y <= 1:
in_count += 1
return Fraction(in_count, sample_count)
要获取未来的结果,我们使用 ray.get(),该操作会阻塞,直到结果完成。
SAMPLE_COUNT = 1000 * 1000
start = time.time()
future = pi4_sample.remote(sample_count = SAMPLE_COUNT)
pi4 = ray.get(future)
end = time.time()
dur = end - start
print(f'Running {SAMPLE_COUNT} tests took {dur} seconds')
Running 1000000 tests took 1.4935967922210693 seconds
现在让我们看看我们的近似值有多好。
pi = pi4 * 4
float(pi)
3.143024
abs(pi-math.pi)/pi
0.0004554042254233261
哎呀。有点不对劲——这才刚好4位小数而已。
我们为什么不把它放大100,000倍呢?让我们做1000亿吧!
FULL_SAMPLE_COUNT = 100 * 1000 * 1000 * 1000 # 1000亿个样本!
BATCHES = int(FULL_SAMPLE_COUNT / SAMPLE_COUNT)
print(f'Doing {BATCHES} batches')
results = []
for _ in range(BATCHES):
results.append(pi4_sample.remote(sample_count = SAMPLE_COUNT))
output = ray.get(results)
Doing 100000 batches
注意到在上面,我们生成了一个包含100,000个future的列表。 现在我们要做的就是等待结果。
根据您的ray集群的大小,这可能需要几分钟。 但为了给您一个概念,如果我们在单台机器上执行, 当我运行这个时,花费了0.4秒。
在单核上,这意味着我们需要花费0.4 * 100000 = 大约11个小时。
以下是仪表板的外观:
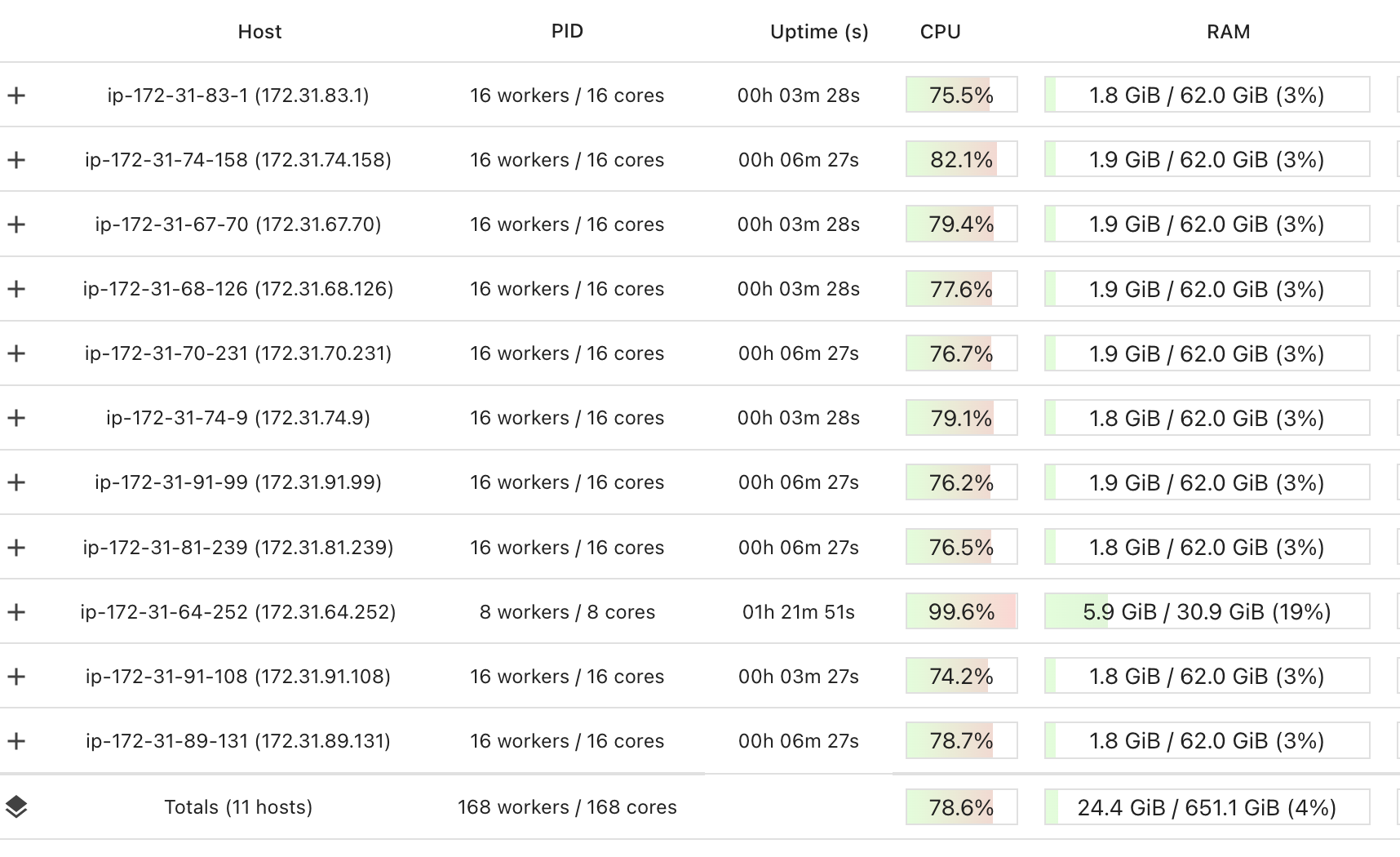
所以现在,不再只有单核在处理这个任务, 而是有168个核一起在进行这个任务。效率大约为80%。
pi = sum(output)*4/len(output)
float(pi)
3.14159518188
abs(pi-math.pi)/pi
8.047791203506436e-07
还不错 – 我们差了一百万分之一。
