性能分析#
剖析是诊断性能、内存不足、挂起或其他应用程序问题的最重要的调试工具之一。以下是调试Ray应用程序时可能使用的一些常见剖析工具列表。
CPU 分析
py-spy
内存分析
memray
GPU 分析
PyTorch 分析器
Nsight 系统
Ray 任务 / 执行者时间线
如果 Ray 与某些分析工具不兼容,尝试在没有 Ray 的情况下运行它们以调试问题。
CPU 分析#
分析驱动程序和工作进程的CPU使用情况。这有助于您了解不同进程的CPU使用情况,并调试意外的高或低使用率。
py-spy#
py-spy 是一个用于 Python 程序的采样分析器。Ray Dashboard 与 pyspy 有原生集成:
它允许你可视化你的Python程序在哪些方面花费了时间,而无需重新启动程序或以任何方式修改代码。
它转储运行进程的堆栈跟踪,以便您可以看到进程在某个时间点正在做什么。当程序挂起时,这非常有用。
备注
在使用 py-spy 时,您可能会遇到权限错误。要解决此问题:
如果你在Docker容器中手动启动Ray,请按照
py-spy文档_ 来解决这个问题。如果你是 KubeRay 用户,请按照 配置 KubeRay 的指南 来解决问题。
以下是使用 py-spy 与 Ray 和 Ray Dashboard 的 步骤。
cProfile#
cProfile 是 Python 的原生分析模块,用于分析您的 Ray 应用程序的性能。
以下是使用 cProfile 的步骤。
内存分析#
分析驱动程序和工作进程的内存使用情况。这有助于您分析应用程序中的内存分配,追踪内存泄漏,并调试高/低内存或内存不足问题。
memray#
memray 是一个 Python 的内存分析器。它可以跟踪 Python 代码、本地扩展模块以及 Python 解释器本身的内存分配。
Ray 仪表盘视图#
你现在可以通过点击 Ray Dashboard 中活动 Worker 进程、任务、角色和作业的驱动进程的“内存分析”操作,为 Ray 驱动程序或 Worker 进程进行内存分析。
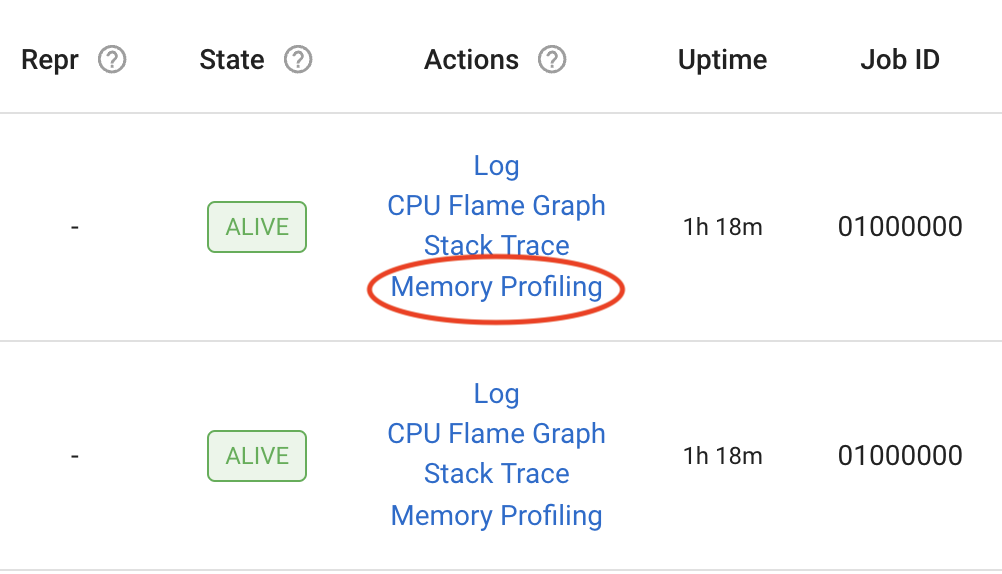
此外,您可以从仪表板视图指定以下 Memray 分析参数:
格式: 分析结果的格式。值可以是“flamegraph”或“table”
持续时间: 跟踪的持续时间(以秒为单位)
泄漏: 启用内存泄漏视图,该视图显示 Ray 未释放的内存,而不是峰值内存使用量
本地代码: 跟踪本地 (C/C++) 堆栈帧 (仅在 Linux 上支持)
Python 分配器追踪: 记录由 pymalloc 分配器进行的分配
GPU 分析#
GPU 和 GRAM 分析用于您的 GPU 工作负载,如分布式训练。这有助于您分析性能和调试内存问题。
当与 Ray Train 一起使用时,PyTorch 分析器是开箱即用的。
NVIDIA Nsight System 在 Ray 上原生支持。
PyTorch 分析器#
PyTorch Profiler 是一个工具,允许在训练和推理期间收集性能指标(特别是GPU指标)。
以下是使用 PyTorch Profiler 与 Ray Train 或 Ray Data 的 步骤。
Nsight 系统分析器#
安装#
首先,按照 Nsight 用户指南 安装 Nsight System CLI。
确认你已正确安装 Nsight:
$ nsys --version
# NVIDIA Nsight Systems version 2022.4.1.21-0db2c85
在 Ray 上运行 Nsight#
要启用GPU分析,请在 runtime_env 中按如下方式指定配置:
import torch
import ray
ray.init()
@ray.remote(num_gpus=1, runtime_env={ "nsight": "default"})
class RayActor:
def run():
a = torch.tensor([1.0, 2.0, 3.0]).cuda()
b = torch.tensor([4.0, 5.0, 6.0]).cuda()
c = a * b
print("Result on GPU:", c)
ray_actor = RayActor.remote()
# The Actor or Task process runs with : "nsys profile [default options] ..."
ray.get(ray_actor.run.remote())
你可以在 nsight.py 中找到 "default" 配置。
自定义选项#
你也可以通过指定一个选项值的字典来为 Nsight System Profiler 添加 自定义选项,这将覆盖 默认 配置,然而,Ray 保留了默认配置的 --output 选项。
import torch
import ray
ray.init()
@ray.remote(
num_gpus=1,
runtime_env={ "nsight": {
"t": "cuda,cudnn,cublas",
"cuda-memory-usage": "true",
"cuda-graph-trace": "graph",
}})
class RayActor:
def run():
a = torch.tensor([1.0, 2.0, 3.0]).cuda()
b = torch.tensor([4.0, 5.0, 6.0]).cuda()
c = a * b
print("Result on GPU:", c)
ray_actor = RayActor.remote()
# The Actor or Task process runs with :
# "nsys profile -t cuda,cudnn,cublas --cuda-memory-usage=True --cuda-graph-trace=graph ..."
ray.get(ray_actor.run.remote())
注意: 默认的报告文件名 (-o, --output) 是日志目录中的 worker_process_{pid}.nsys-rep。
性能分析结果#
在 /tmp/ray/session_*/logs/{profiler_name} 目录下查找分析结果。此特定目录位置未来可能会更改。您可以从 Ray 仪表盘 下载分析报告。
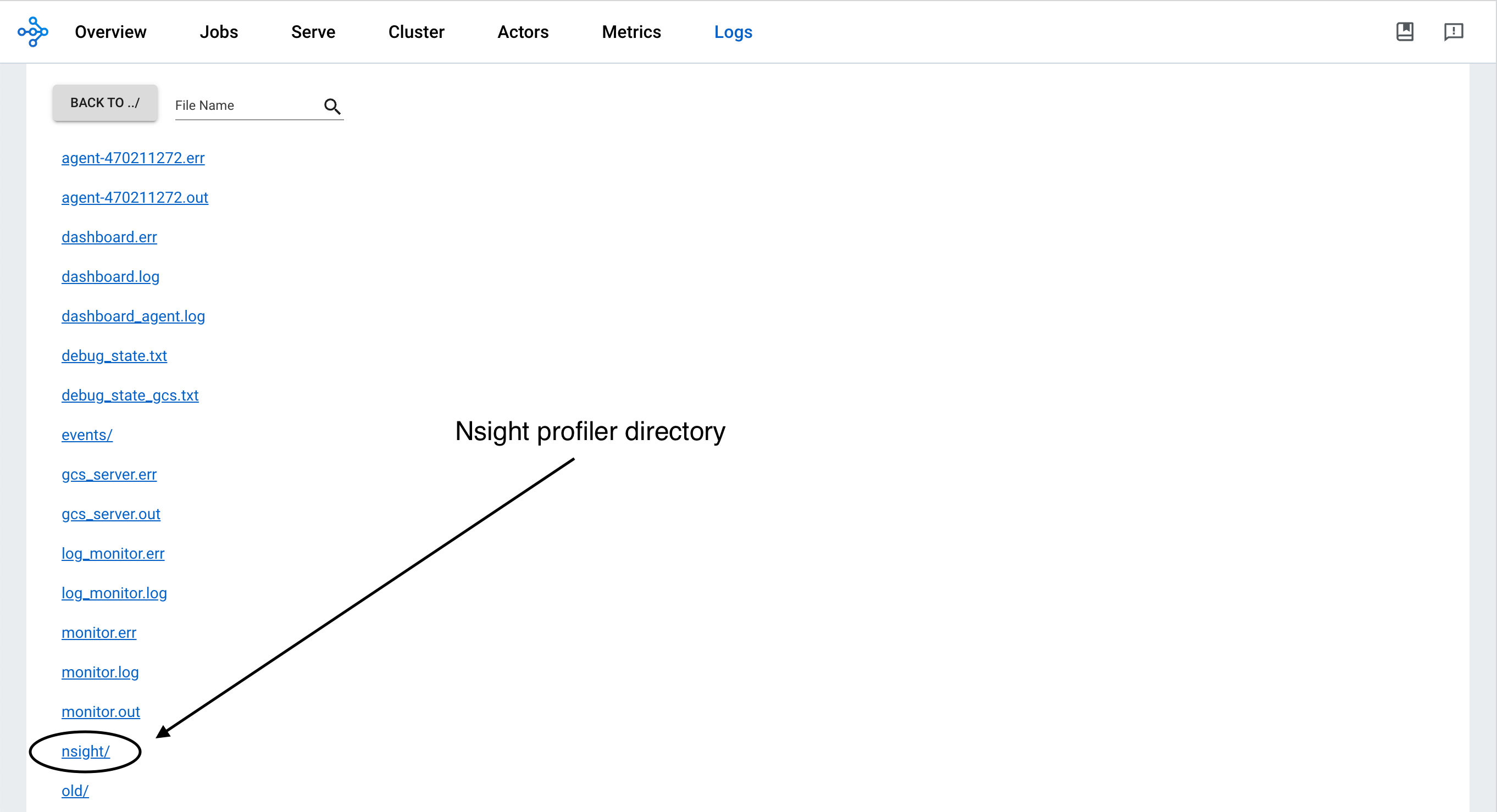
要可视化结果,请在您的笔记本电脑上安装 Nsight System GUI,它将成为主机。将 .nsys-rep 文件传输到您的主机并使用 GUI 打开它。现在您可以查看可视化的性能分析信息。
注意:Nsight System Profiler 输出(-o, –output)选项允许您设置文件路径。Ray 使用日志目录作为基础,并将输出选项附加到其上。例如:
--output job_name/ray_worker -> /tmp/ray/session_*/logs/nsight/job_name/ray_worker
--output /Users/Desktop/job_name/ray_worker -> /Users/Desktop/job_name/ray_worker
最佳实践是在输出选项中仅指定文件名。
Ray 任务或参与者时间线#
Ray Timeline 记录了 Ray 任务和角色的执行时间。这有助于你分析性能,识别滞后者,并理解工作负载的分布。
在 Ray 仪表盘中打开您的 Ray 作业,并按照 下载和可视化 Ray Timeline 生成的跟踪文件的说明。