为 Ray 文档做贡献#
有许多方式可以为 Ray 文档做出贡献,我们一直在寻找新的贡献者。即使你只是想修正一个错别字或扩展一个部分,请随时这样做!
本文档将引导您完成开始所需的一切。
编辑风格#
我们遵循 Google 开发者文档风格指南。以下是一些亮点:
编辑风格在CI中通过Vale强制执行。更多信息,请参见如何使用Vale。
构建 Ray 文档#
如果你想为 Ray 文档做贡献,你需要一种构建它的方法。不要在你计划用于构建文档的环境中安装 Ray。文档构建系统的要求通常与你运行 Ray 本身所需的要求不兼容。
按照以下说明构建文档:
Fork Ray#
克隆分叉的仓库到您的本地机器
接下来,切换到 ray/doc 目录:
cd ray/doc
安装依赖项#
如果你还没有这样做,创建一个与用于构建和运行 Ray 的 Python 环境分开的 Python 环境,最好使用最新版本的 Python。例如,如果你使用 conda:
conda create -n docs python=3.12
接下来,激活你正在使用的 Python 环境(例如,venv、conda 等)。使用 conda 的话,操作如下:
conda activate docs
使用以下命令安装文档依赖项:
pip install -r requirements-doc.txt
在此步骤中不要使用 -U。你不希望升级依赖项,因为 requirements-doc.txt 固定了构建文档所需的精确版本。
构建文档#
在构建之前,首先通过运行以下命令清理您的环境:
make clean
从以下2个选项中选择以在本地构建文档:
增量构建
完整构建
1. Incremental build with global cache and live rendering#
要使用此选项,您可以运行:
make local
如果你需要频繁进行简单的更改,推荐使用此选项。
在这种方法中,Sphinx 只构建你在分支中相对于上次从上游主分支拉取所做的更改。其余的文档通过从你上次从上游提交的预构建文档页面进行缓存(每次向 Ray 推送新提交时,CI 都会从该提交构建所有文档页面,并将它们存储在 S3 上作为缓存)。
构建首先追踪你的提交树,以找到CI已经在S3上缓存的最新提交。一旦构建找到该提交,它会从S3获取相应的缓存并将其解压到doc/目录中。同时,CI会追踪从该提交到当前HEAD的所有更改文件,包括任何未暂存的更改。
Sphinx 然后只重新构建受您更改影响的页面,其余部分从缓存中保持不变。
当构建完成后,文档页面会自动在您的浏览器中弹出。如果在 doc/ 目录中进行了任何更改,Sphinx 会自动重新构建并重新加载您的文档页面。您可以通过按 Ctrl+C 中断来停止它。
2. Full build from scratch#
在完整构建选项中,Sphinx 会重新构建 doc/ 目录中的所有文件,忽略所有缓存和保存的环境。由于这种行为,你会得到一个非常干净的构建,但速度要慢得多。
make develop
在 _build 目录中找到文档构建。构建完成后,您可以简单地在浏览器中打开 _build/html/index.html 文件。检查构建的输出以确保一切按预期工作被认为是良好的实践。
在提交任何更改之前,请确保从 doc 文件夹中运行 linter ,使用 ../scripts/format.sh ,以确保您的更改格式正确。
代码补全和其他开发者工具#
如果你经常处理文档工作,你可能会发现 esbonio 语言服务器很有用。Esbonio 为 RST 文档提供了上下文感知的语法补全、定义、诊断、文档链接和其他信息。如果你不熟悉 语言服务器,它们是现代开发者工具包中的重要部分;如果你之前使用过 pylance 或 python-lsp-server,你会知道这些工具有多么有用。
Esbonio 还提供了一个包含实时预览的 vscode 扩展。只需安装 esbonio vscode 扩展即可开始使用该工具:
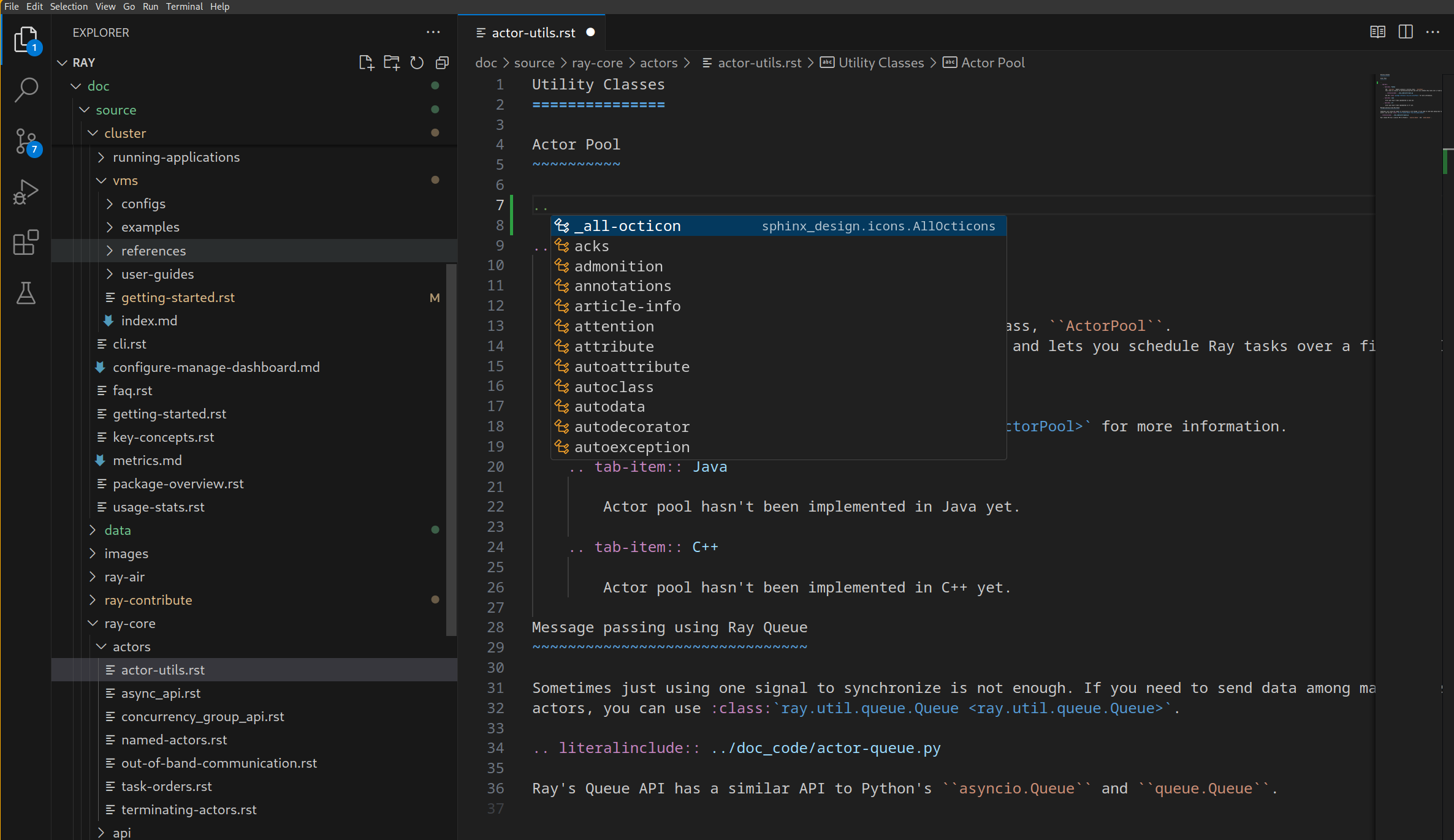
作为 Esbonio 自动补全功能的一个例子,你可以输入 .. 来调出所有 RST 指令的自动补全菜单:
Esbonio 也可以与 neovim 一起使用 - 查看 lspconfig 仓库获取安装说明。
我们的构建系统基础#
Ray 文档是使用 sphinx 构建系统构建的。我们使用 PyData Sphinx Theme 作为文档的主题。
我们使用 myst-parser 来允许你使用 Sphinx 的原生 reStructuredText (rST) 或 Markedly Structured Text (MyST) 编写 Ray 文档。这两种格式可以相互转换,因此选择权在你手中。尽管如此,重要的是要知道 MyST 是 common markdown 兼容的。过去的经验表明,大多数开发者熟悉 md 语法,因此如果你打算添加新文档,我们建议从 .md 文件开始。
Ray 文档也完全支持 Jupyter Notebooks 等可执行格式。我们的许多示例都是包含 MyST markdown 单元格 的笔记本。
贡献什么?#
以 Ray Tune 为例,你可以看到我们的文档由几种不同类型的文档组成,所有这些你都可以贡献:
这种结构在 Ray 文档源代码 中也有体现,因此你应该不会有任何问题找到你想要的内容。所有其他 Ray 项目共享类似的结构,但根据项目的不同可能会有细微的差异。
上述每种文档类型都有其各自的用途,但最终我们的文档归结为 两种类型 的文档:
修复拼写错误并改进解释#
如果你在任何文档中发现拼写错误,或者认为某个解释不够清晰,请考虑提交一个拉取请求。在这种情况下,只需按照上述说明运行linter,然后提交你的拉取请求。
添加API参考#
我们使用 Sphinx 的 autodoc 扩展 从我们的源代码生成 API 文档。如果我们遗漏了对某个函数或类的引用,请考虑将其添加到相关文档中。
例如,以下是如何使用 autofunction 和 autoclass 添加函数或类引用:
.. autofunction:: ray.tune.integration.docker.DockerSyncer
.. autoclass:: ray.tune.integration.keras.TuneReportCallback
上面的代码片段摘自 Tune API 文档,你可以参考该文档。
如果你想更改API文档的内容,你需要直接编辑源代码中的相应函数或类签名。例如,在上面的 autofunction 调用中,要更改 ray.tune.integration.docker.DockerSyncer 的API参考,你需要 更改以下源文件。
为了展示API的使用,在API文档中嵌入小的使用示例是很重要的。这些示例应该是自包含的,并且开箱即用,这样用户可以将它们复制粘贴到Python解释器中并进行试验(例如,如果适用,它们应该指向示例数据)。用户经常依赖这些示例来构建他们的应用程序。要了解更多关于编写示例的信息,请阅读如何编写代码片段。
向 .rST 或 .md 文件添加代码#
修改现有文档文件中的文本很容易,但在添加代码时需要小心。原因是我们要确保文档中的每个代码片段都经过测试。这要求我们有一个在文档中包含和测试代码片段的流程。要学习如何编写可测试的代码片段,请阅读 如何编写代码片段。
from ray import train
def objective(x, a, b): # Define an objective function.
return a * (x ** 0.5) + b
def trainable(config): # Pass a "config" dictionary into your trainable.
for x in range(20): # "Train" for 20 iterations and compute intermediate scores.
score = objective(x, config["a"], config["b"])
train.report({"score": score}) # Send the score to Tune.
此代码由 literalinclude 从名为 doc_code/key_concepts.py 的文件中导入。doc_code 目录中的每个 Python 文件都将由我们的 CI 系统自动测试,但请确保先在本地运行您更改(或新添加)的脚本。您不需要在本地运行测试框架。
在极少数情况下,当你添加 明显 的伪代码来演示一个概念时,可以将其直接添加到你的 .rST 或 .md 文件中,例如使用 .. code-cell:: python 指令。但如果你的代码是应该运行的,那么它需要经过测试。
从头开始创建新文档#
有时你可能想为 Ray 文档添加一个全新的文档,比如添加一个新的用户指南或一个新的示例。
为了使其生效,您需要确保将新文档明确添加到父文档的 toctree 中,这决定了 Ray 文档的结构。更多信息请参见 Sphinx 文档。
根据您添加的文档类型,您可能还需要对现有的概览页面进行更改,该页面会整理相关文档列表。例如,对于 Ray Tune,每个用户指南都会作为一个面板添加到 用户指南概览页面,同样的情况也适用于 所有 Tune 示例。始终检查您正在处理的 Ray 子项目的结构,以了解如何在现有结构中整合它。在某些情况下,您可能需要为面板选择一张图片。图片位于 doc/source/images。
创建一个笔记本示例#
要在 Ray 文档中添加一个新的可执行示例,您可以从我们的 MyST 笔记本模板 或 Jupyter 笔记本模板 开始。您也可以直接下载您正在阅读的文档(点击本页顶部的相应下载按钮以获取 .ipynb 文件)并开始修改它。Ray Tune 中的所有示例笔记本都会由我们的 CI 系统自动测试,前提是您将它们放置在 examples 文件夹 中。如果您在为其他 Ray 子项目贡献时对如何测试您的笔记本有疑问,请确保在 Ray 社区 Slack 中提问,或在提交拉取请求时直接在 GitHub 上提问。
要基于现有示例进行工作,您还可以查看 Ray Tune Hyperopt 示例(.ipynb) 或 Ray Serve 文本分类指南(.md)。我们建议您从 .md 文件开始,并在过程结束时将您的文件转换为 .ipynb 笔记本。我们将在下面带您完成这个过程。
这些笔记本与其他文档的不同之处在于,它们将代码和文本结合在一个文档中,并且可以在浏览器中启动。我们还确保在将它们添加到我们的文档之前,它们已经通过了我们的CI系统的测试。为了实现这一点,笔记本需要定义一个 内核规范 ,以告诉笔记本服务器如何解释和运行代码。例如,以下是一个Python笔记本的内核规范:
---
jupytext:
text_representation:
extension: .md
format_name: myst
kernelspec:
display_name: Python 3
language: python
name: python3
---
如果你在 .md 格式中编写笔记本,你需要在文件顶部添加这个 YAML 前言。要在你的笔记本中添加代码,你可以使用 code-cell 指令。以下是一个示例:
```python
import ray
import ray.rllib.agents.ppo as ppo
from ray import serve
def train_ppo_model():
trainer = ppo.PPOTrainer(
config={"framework": "torch", "num_workers": 0},
env="CartPole-v0",
)
# Train for one iteration
trainer.train()
trainer.save("/tmp/rllib_checkpoint")
return "/tmp/rllib_checkpoint/checkpoint_000001/checkpoint-1"
checkpoint_path = train_ppo_model()
```
将此Markdown块放入文档中,将在浏览器中呈现如下:
import ray
import ray.rllib.agents.ppo as ppo
from ray import serve
def train_ppo_model():
trainer = ppo.PPOTrainer(
config={"framework": "torch", "num_workers": 0},
env="CartPole-v0",
)
# Train for one iteration
trainer.train()
trainer.save("/tmp/rllib_checkpoint")
return "/tmp/rllib_checkpoint/checkpoint_000001/checkpoint-1"
checkpoint_path = train_ppo_model()
测试笔记本#
删除单元格对于计算密集型的笔记本来说特别有趣。我们希望你贡献的笔记本使用 真实 的值,而不仅仅是玩具示例。同时,我们希望我们的笔记本能被CI系统测试,并且运行它们不应花费太长时间。你可以做的是,首先让用户看到带有你希望他们看到的参数的笔记本单元格:
```{code-cell} python3
num_workers = 8
num_gpus = 2
```
在浏览器中将呈现如下:
num_workers = 8
num_gpus = 2
但在你的笔记本中,你随后跟了一个 removed 单元格,它不会被渲染,但具有更小的值并使笔记本运行更快:
```{code-cell} python3
:tags: [remove-cell]
num_workers = 0
num_gpus = 0
```
将Markdown笔记本转换为ipynb#
完成示例编写后,您可以使用 jupytext 将其转换为 .ipynb 笔记本:
jupytext your-example.md --to ipynb
同样地,你可以使用 --to myst 将 .ipynb 笔记本转换为 .md 笔记本。如果你想将你的笔记本转换为 Python 文件,例如测试你的整个脚本是否能在没有错误的情况下运行,你可以使用 --to py 代替。
如何使用 Vale#
什么是 Vale?#
Vale 检查您的写作是否符合 Google 开发者文档风格指南。它仅在 Ray Data 文档中强制执行。
Vale 捕捉拼写和语法错误。它还强制执行风格规则,如“使用缩写”和“使用第二人称”。有关规则的完整列表,请参阅 Ray 仓库中的配置。
如何运行 Vale?#
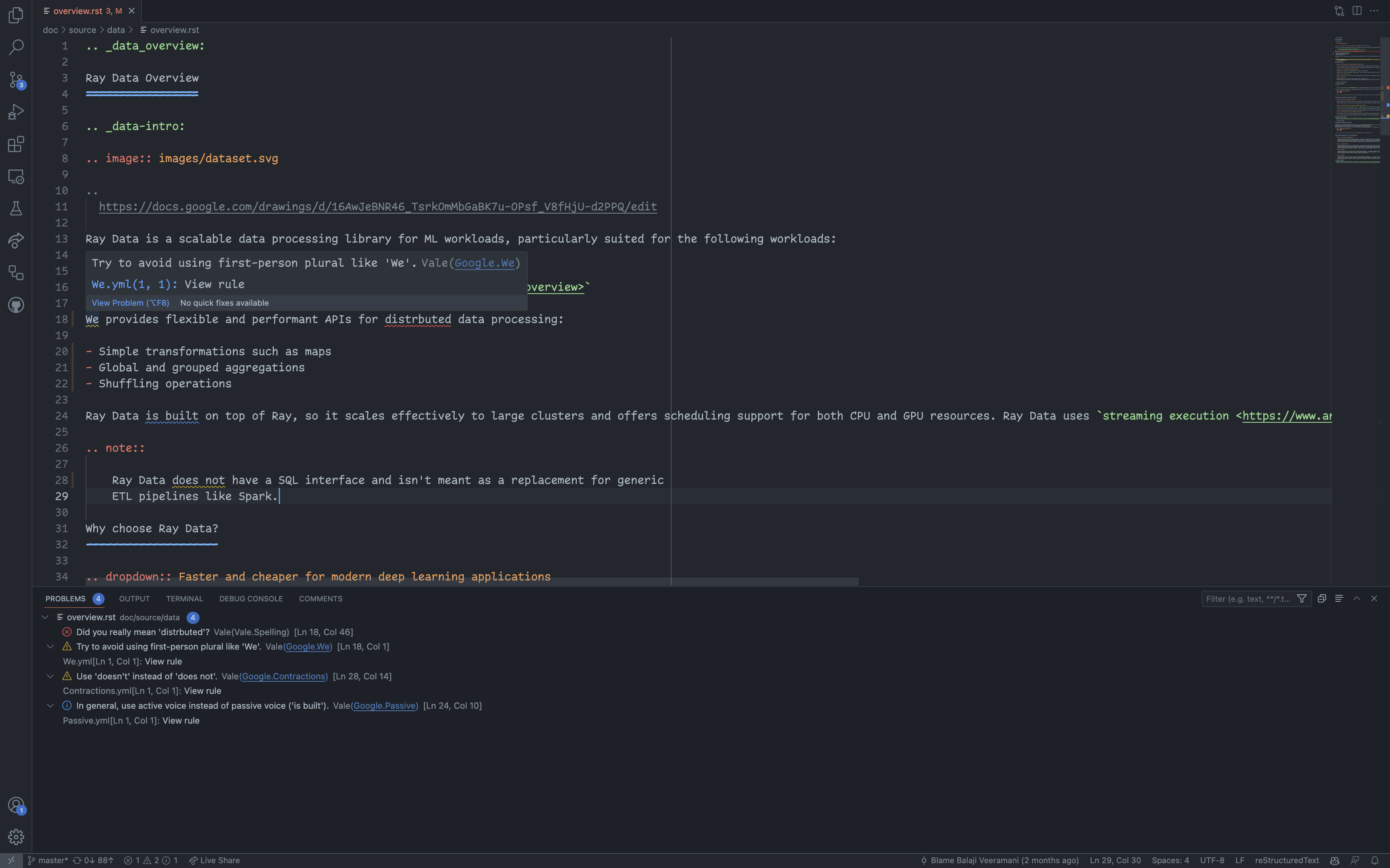
如何使用 VSCode 扩展#
如何在命令行中运行 Vale#
安装 Vale。如果你使用 macOS,使用 Homebrew。
brew install vale
否则,使用 PyPI。
pip install vale
有关安装的更多信息,请参阅 Vale 文档。
在终端中运行 Vale
vale doc/source/data/overview.rstVale 应在您的终端中显示警告。
❯ vale doc/source/data/overview.rst doc/source/data/overview.rst 18:1 warning Try to avoid using Google.We first-person plural like 'We'. 18:46 error Did you really mean Vale.Spelling 'distrbuted'? 24:10 suggestion In general, use active voice Google.Passive instead of passive voice ('is built'). 28:14 warning Use 'doesn't' instead of 'does Google.Contractions not'. ✖ 1 error, 2 warnings and 1 suggestion in 1 file.
如何处理错误的 Vale.Spelling 错误#
要添加自定义术语,请完成以下步骤:
如果目录还不存在,请在
.vale/styles/Vocab中为您的团队创建一个目录。例如,.vale/styles/Vocab/Data。如果尚不存在,请创建一个名为
accept.txt的文本文件。例如,.vale/styles/Vocab/Data/accept.txt。将您的术语添加到
accept.txt中。Vale 接受正则表达式。
更多信息,请参阅 Vale 文档中的 词汇表。
如何处理虚假的 Google.WordList 错误#
如果你使用了一个不在 Google 的词汇表 中的单词,Vale 会报错。
304:52 error Use 'select' instead of Google.WordList
'check'.
如果你想无论如何都要使用这个词,请修改 WordList 配置 中的相应字段。
故障排除#
如果在构建文档时遇到问题,按照以下步骤可以帮助隔离或解决大多数问题:
清理构建产物。 使用
make clean清理工作目录中的文档构建产物。Sphinx 使用缓存来避免重复工作,这有时会导致问题。特别是在你构建文档后,执行git pull origin master拉取最新更改,然后再次尝试构建文档时,这种情况尤为明显。检查你的环境。 使用
pip list检查已安装的依赖项。将它们与doc/requirements-doc.txt进行比较。文档构建系统与 Ray 的依赖要求不同。你不需要运行机器学习模型或在分布式系统上执行代码来构建文档。事实上,最好使用一个完全独立的文档构建环境,而不是你用来运行 Ray 的环境,以避免依赖冲突。安装要求时,执行pip install -r doc/requirements-doc.txt。不要使用-U,因为在安装过程中你不希望升级任何依赖项。确保使用现代版本的Python。 文档构建系统并不保持与Ray相同的依赖和Python版本要求。在构建文档时,请使用现代版本的Python。较新的Python版本可能比之前的版本快得多。有关最新版本支持信息,请参阅 https://endoflife.date/python。
在 Sphinx 中启用断点。在
doc/Makefile中向SPHINXOPTS添加 -P,以告诉sphinx在遇到断点时停止,并移除-j auto以禁用并行构建。现在你可以在你尝试导入的模块中,或者在sphinx代码本身中设置断点,这有助于隔离顽固的构建问题。[增量构建] 侧边导航栏不反映新页面 如果你在添加新页面,它们应该总是显示在索引页面的侧边导航栏中。然而,使用
make local的增量构建会跳过重建许多其他页面,因此 Sphinx 不会更新这些页面上的侧边导航栏。要在所有页面上构建带有正确侧边导航栏的文档,请考虑使用make develop。
接下来去哪里?#
除了文档之外,还有许多其他方式可以为 Ray 做出贡献。更多信息请参见 我们的贡献者指南。
