使用 Ray Tune 运行分布式实验#
Tune 通常用于大规模分布式超参数优化。本页将概述如何设置和启动分布式实验,以及在运行分布式实验时 Tune 的 常用命令。
摘要#
要使用 Tune 运行分布式实验,您需要:
首先,如果你还没有启动,请 启动一个 Ray 集群。
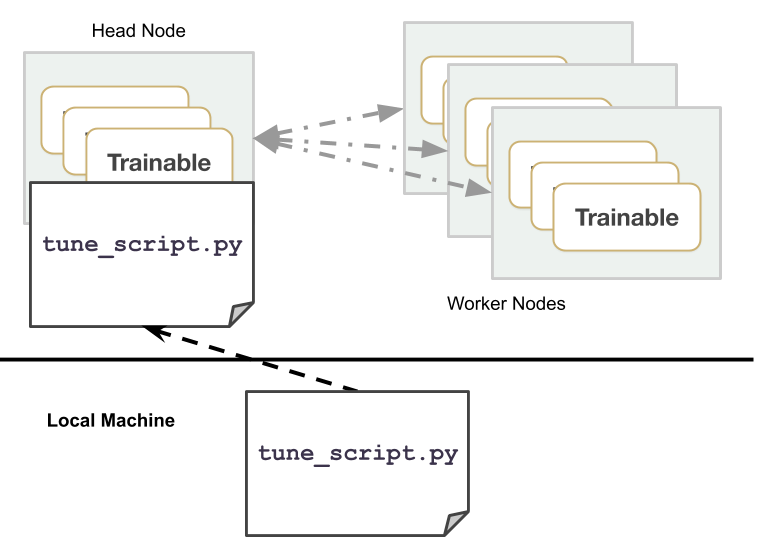
在头节点上运行脚本,或使用 ray submit,或使用 Ray Job Submission。
示例:在 AWS 虚拟机上进行分布式调优#
按照以下说明在AWS上启动节点(使用深度学习AMI)。请参阅 集群设置文档 。保存以下集群配置(tune-default.yaml):
cluster_name: tune-default
provider: {type: aws, region: us-west-2}
auth: {ssh_user: ubuntu}
min_workers: 3
max_workers: 3
# Deep Learning AMI (Ubuntu) Version 21.0
available_node_types:
head_node:
node_config: {InstanceType: c5.xlarge, ImageId: ami-0b294f219d14e6a82}
worker_nodes:
node_config: {InstanceType: c5.xlarge, ImageId: ami-0b294f219d14e6a82}
head_node_type: head_node
setup_commands: # Set up each node.
- pip install ray torch torchvision tensorboard
ray up 在节点集群上启动 Ray。
ray up tune-default.yaml
ray submit --start 根据给定的集群配置YAML文件启动一个集群,将 tune_script.py 上传到集群,并运行 python tune_script.py [args]。
ray submit tune-default.yaml tune_script.py --start -- --ray-address=localhost:6379
通过在远程头节点上启动 TensorBoard 来分析您的结果。
# Go to http://localhost:6006 to access TensorBoard.
ray exec tune-default.yaml 'tensorboard --logdir=~/ray_results/ --port 6006' --port-forward 6006
请注意,您可以通过指定 RunConfig(storage_path=..) 来自定义结果目录,该参数由 Tuner 接收。然后,您可以将 TensorBoard 指向该目录以可视化结果。您还可以使用 awless 在 AWS 上轻松进行集群管理。
运行分布式 Tune 实验#
运行分布式(多节点)实验需要Ray已经启动。你可以在本地机器或云上进行此操作。
在您的机器上,Tune 将自动检测 GPU 和 CPU 的数量,而无需您管理 CUDA_VISIBLE_DEVICES。
要执行分布式实验,请在 Tuner.fit() 之前调用 ray.init(address=XXX),其中 XXX 是 Ray 地址,默认为 localhost:6379。Tune 的 Python 脚本应在 Ray 集群的头节点上执行。
修改现有的 Tune 实验以实现分布式的一种常见方法是设置一个 argparse 变量,以便在分布式和单节点之间切换是无缝的。
import ray
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--address")
args = parser.parse_args()
ray.init(address=args.address)
tuner = tune.Tuner(...)
tuner.fit()
# On the head node, connect to an existing ray cluster
$ python tune_script.py --ray-address=localhost:XXXX
如果你使用了集群配置(通过 ray up 或 ray submit --start 启动集群),请使用:
ray submit tune-default.yaml tune_script.py -- --ray-address=localhost:6379
小技巧
在示例中,常用的 Ray 地址是
localhost:6379。如果Ray集群已经启动,您应该不需要在worker节点上运行任何东西。
分布式Tune运行中的存储选项#
在分布式实验中,您应尝试使用 云端检查点 以减少同步开销。为此,您只需在 RunConfig 中指定一个远程 storage_path。
my_trainable 是以下示例中的用户定义 Tune 可训练对象:
from ray import train, tune
from my_module import my_trainable
tuner = tune.Tuner(
my_trainable,
run_config=train.RunConfig(
name="experiment_name",
storage_path="s3://bucket-name/sub-path/",
)
)
tuner.fit()
更多详情或自定义设置,请参阅我们的 分布式Tune实验中配置存储的指南。
Tune 运行在可抢占实例上#
在竞价实例(或可抢占实例)上运行可以降低实验成本。您可以通过以下配置修改在AWS中启用竞价实例:
# Provider-specific config for worker nodes, e.g. instance type.
worker_nodes:
InstanceType: m5.large
ImageId: ami-0b294f219d14e6a82 # Deep Learning AMI (Ubuntu) Version 21.0
# Run workers on spot by default. Comment this out to use on-demand.
InstanceMarketOptions:
MarketType: spot
SpotOptions:
MaxPrice: 1.0 # Max Hourly Price
在GCP中,您可以使用以下配置修改:
worker_nodes:
machineType: n1-standard-2
disks:
- boot: true
autoDelete: true
type: PERSISTENT
initializeParams:
diskSizeGb: 50
# See https://cloud.google.com/compute/docs/images for more images
sourceImage: projects/deeplearning-platform-release/global/images/family/tf-1-13-cpu
# Run workers on preemtible instances.
scheduling:
- preemptible: true
竞价实例在试验仍在运行时可能会突然被抢占。Tune 允许你通过 检查点 保存模型训练的进度来减轻这种影响。
search_space = {
"lr": tune.sample_from(lambda spec: 10 ** (-10 * np.random.rand())),
"momentum": tune.uniform(0.1, 0.9),
}
tuner = tune.Tuner(
TrainMNIST,
run_config=train.RunConfig(stop={"training_iteration": 10}),
param_space=search_space,
)
results = tuner.fit()
使用 Spot 实例(AWS)的 Tune 示例#
以下是在竞价实例上运行 Tune 的示例。这假设您的 AWS 凭证已经设置好(aws configure):
在这里下载一个完整的Tune实验脚本示例。这包括一个带有检查点的可训练对象:
mnist_pytorch_trainable.py。要运行此示例,您需要安装以下内容:
$ pip install ray torch torchvision filelock
在此下载示例集群yaml文件:
tune-default.yaml运行
ray submit如下所示以在这些节点上运行 Tune。如果集群尚未启动,请附加[--start]。运行后自动关闭节点,请附加[--stop]。
ray submit tune-default.yaml mnist_pytorch_trainable.py --start -- --ray-address=localhost:6379
在AWS或GCP上进行测试时,您可以选择使用以下命令在所有工作节点启动后终止一个随机的工作节点
$ ray kill-random-node tune-default.yaml --hard
总结一下,以下是需要运行的命令:
wget https://raw.githubusercontent.com/ray-project/ray/master/python/ray/tune/examples/mnist_pytorch_trainable.py
wget https://raw.githubusercontent.com/ray-project/ray/master/python/ray/tune/tune-default.yaml
ray submit tune-default.yaml mnist_pytorch_trainable.py --start -- --ray-address=localhost:6379
# wait a while until after all nodes have started
ray kill-random-node tune-default.yaml --hard
你应该会看到 Tune 最终在不同的工作节点上继续试验。更多详情请参见 容错 部分。
你也可以在 RunConfig 中指定 storage_path=...,这是 Tuner 接受的参数,用于将结果上传到 S3 等云存储,以便在你想要自动启动和停止集群时持久化结果。
Tune 运行的容错性#
在试验失败的情况下(如果 max_failures != 0),Tune 会自动重启试验,无论是在单节点还是分布式环境中。
例如,假设一个节点在试验仍在该节点上执行时被抢占或崩溃。假设该试验存在检查点(并且在分布式设置中,配置了某种形式的持久存储以访问试验的检查点),Tune 会等待可用资源再次开始执行试验,从上次中断的地方继续。如果没有找到检查点,试验将从头开始重新启动。有关检查点的信息,请参见 这里。
如果试验或执行者被放置在不同的节点上,Tune 会自动将之前的检查点文件推送到该节点并恢复远程试验执行者的状态,即使在失败后也能从最新的检查点恢复试验。
从故障中恢复#
Tune 自动保存你整个实验的进度(一个 Tuner.fit() 会话),因此如果实验崩溃或被其他原因取消,可以通过 restore() 恢复。
常用调音命令#
以下是一些常用的提交实验命令。请参阅 集群页面 以查看更多全面的命令文档。
# Upload `tune_experiment.py` from your local machine onto the cluster. Then,
# run `python tune_experiment.py --address=localhost:6379` on the remote machine.
$ ray submit CLUSTER.YAML tune_experiment.py -- --address=localhost:6379
# Start a cluster and run an experiment in a detached tmux session,
# and shut down the cluster as soon as the experiment completes.
# In `tune_experiment.py`, set `RunConfig(storage_path="s3://...")`
# to persist results
$ ray submit CLUSTER.YAML --tmux --start --stop tune_experiment.py -- --address=localhost:6379
# To start or update your cluster:
$ ray up CLUSTER.YAML [-y]
# Shut-down all instances of your cluster:
$ ray down CLUSTER.YAML [-y]
# Run TensorBoard and forward the port to your own machine.
$ ray exec CLUSTER.YAML 'tensorboard --logdir ~/ray_results/ --port 6006' --port-forward 6006
# Run Jupyter Lab and forward the port to your own machine.
$ ray exec CLUSTER.YAML 'jupyter lab --port 6006' --port-forward 6006
# Get a summary of all the experiments and trials that have executed so far.
$ ray exec CLUSTER.YAML 'tune ls ~/ray_results'
# Upload and sync file_mounts up to the cluster with this command.
$ ray rsync-up CLUSTER.YAML
# Download the results directory from your cluster head node to your local machine on ``~/cluster_results``.
$ ray rsync-down CLUSTER.YAML '~/ray_results' ~/cluster_results
# Launching multiple clusters using the same configuration.
$ ray up CLUSTER.YAML -n="cluster1"
$ ray up CLUSTER.YAML -n="cluster2"
$ ray up CLUSTER.YAML -n="cluster3"
故障排除#
有时,您的程序可能会卡住。运行此命令以在不运行任何安装命令的情况下重启 Ray 集群。
$ ray up CLUSTER.YAML --restart-only
