分析 Tune 实验结果#
在本指南中,我们将逐步介绍在使用 tuner.fit() 运行 Tune 实验后,您可能希望执行的一些常见分析工作流程。
从目录加载 Tune 实验结果
基本的 实验级别 分析:快速了解试验的表现
基本的 试验级别 分析:访问单个试验的超参数配置和最后报告的指标
绘制单个试验报告指标的全部历史
访问保存的检查点(假设您已启用检查点)并加载到模型中进行测试推理
result_grid: ResultGrid = tuner.fit()
best_result: Result = result_grid.get_best_result()
tuner.fit() 的输出是一个 ResultGrid,它是多个 Result 对象的集合。有关可用属性的更多详细信息,请参见上述链接的文档参考 ResultGrid 和 Result。
让我们开始使用 MNIST PyTorch 示例进行超参数搜索。训练函数定义在 此处,我们将其传递给一个 Tuner,以开始并行运行试验。
import os
from ray import train, tune
from ray.tune.examples.mnist_pytorch import train_mnist
from ray.tune import ResultGrid
storage_path = "/tmp/ray_results"
exp_name = "tune_analyzing_results"
tuner = tune.Tuner(
train_mnist,
param_space={
"lr": tune.loguniform(0.001, 0.1),
"momentum": tune.grid_search([0.8, 0.9, 0.99]),
"should_checkpoint": True,
},
run_config=train.RunConfig(
name=exp_name,
stop={"training_iteration": 100},
checkpoint_config=train.CheckpointConfig(
checkpoint_score_attribute="mean_accuracy",
num_to_keep=5,
),
storage_path=storage_path,
),
tune_config=tune.TuneConfig(mode="max", metric="mean_accuracy", num_samples=3),
)
result_grid: ResultGrid = tuner.fit()
Tune Status
| Current time: | 2023-08-25 17:42:39 |
| Running for: | 00:00:12.43 |
| Memory: | 27.0/64.0 GiB |
System Info
Using FIFO scheduling algorithm.Logical resource usage: 1.0/10 CPUs, 0/0 GPUs
Trial Status
| Trial name | status | loc | lr | momentum | acc | iter | total time (s) |
|---|---|---|---|---|---|---|---|
| train_mnist_6e465_00000 | TERMINATED | 127.0.0.1:94903 | 0.0188636 | 0.8 | 0.925 | 100 | 8.81282 |
| train_mnist_6e465_00001 | TERMINATED | 127.0.0.1:94904 | 0.0104137 | 0.9 | 0.9625 | 100 | 8.6819 |
| train_mnist_6e465_00002 | TERMINATED | 127.0.0.1:94905 | 0.00102317 | 0.99 | 0.953125 | 100 | 8.67491 |
| train_mnist_6e465_00003 | TERMINATED | 127.0.0.1:94906 | 0.0103929 | 0.8 | 0.94375 | 100 | 8.92996 |
| train_mnist_6e465_00004 | TERMINATED | 127.0.0.1:94907 | 0.00808686 | 0.9 | 0.95625 | 100 | 8.75311 |
| train_mnist_6e465_00005 | TERMINATED | 127.0.0.1:94908 | 0.00172525 | 0.99 | 0.95625 | 100 | 8.76523 |
| train_mnist_6e465_00006 | TERMINATED | 127.0.0.1:94909 | 0.0507692 | 0.8 | 0.946875 | 100 | 8.94565 |
| train_mnist_6e465_00007 | TERMINATED | 127.0.0.1:94910 | 0.00978134 | 0.9 | 0.965625 | 100 | 8.77776 |
| train_mnist_6e465_00008 | TERMINATED | 127.0.0.1:94911 | 0.00368709 | 0.99 | 0.934375 | 100 | 8.8495 |
2023-08-25 17:42:27,603 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
(ImplicitFunc pid=94906) StorageContext on SESSION (rank=None):
(ImplicitFunc pid=94906) StorageContext<
(ImplicitFunc pid=94906) storage_path=/tmp/ray_results
(ImplicitFunc pid=94906) storage_local_path=/Users/justin/ray_results
(ImplicitFunc pid=94906) storage_filesystem=<pyarrow._fs.LocalFileSystem object at 0x149b763b0>
(ImplicitFunc pid=94906) storage_fs_path=/tmp/ray_results
(ImplicitFunc pid=94906) experiment_dir_name=tune_analyzing_results
(ImplicitFunc pid=94906) trial_dir_name=train_mnist_6e465_00003_3_lr=0.0104,momentum=0.8000_2023-08-25_17-42-27
(ImplicitFunc pid=94906) current_checkpoint_index=0
(ImplicitFunc pid=94906) >
(train_mnist pid=94907) Checkpoint successfully created at: Checkpoint(filesystem=local, path=/tmp/ray_results/tune_analyzing_results/train_mnist_6e465_00004_4_lr=0.0081,momentum=0.9000_2023-08-25_17-42-27/checkpoint_000000)
2023-08-25 17:42:30,460 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:30,868 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:31,252 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:31,684 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:32,050 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:32,422 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:32,836 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:33,238 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:33,599 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:33,987 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:34,358 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:34,768 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
(ImplicitFunc pid=94905) StorageContext on SESSION (rank=None): [repeated 8x across cluster] (Ray deduplicates logs by default. Set RAY_DEDUP_LOGS=0 to disable log deduplication, or see https://docs.ray.io/en/master/ray-observability/ray-logging.html#log-deduplication for more options.)
(ImplicitFunc pid=94905) StorageContext< [repeated 8x across cluster]
(ImplicitFunc pid=94905) storage_path=/tmp/ray_results [repeated 8x across cluster]
(ImplicitFunc pid=94905) storage_local_path=/Users/justin/ray_results [repeated 8x across cluster]
(ImplicitFunc pid=94905) storage_filesystem=<pyarrow._fs.LocalFileSystem object at 0x13e75e070> [repeated 8x across cluster]
(ImplicitFunc pid=94905) storage_fs_path=/tmp/ray_results [repeated 8x across cluster]
(ImplicitFunc pid=94905) experiment_dir_name=tune_analyzing_results [repeated 8x across cluster]
(ImplicitFunc pid=94905) current_checkpoint_index=0 [repeated 16x across cluster]
(ImplicitFunc pid=94905) > [repeated 8x across cluster]
2023-08-25 17:42:35,127 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
(train_mnist pid=94906) Checkpoint successfully created at: Checkpoint(filesystem=local, path=/tmp/ray_results/tune_analyzing_results/train_mnist_6e465_00003_3_lr=0.0104,momentum=0.8000_2023-08-25_17-42-27/checkpoint_000050) [repeated 455x across cluster]
2023-08-25 17:42:35,508 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:35,899 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:36,277 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:36,662 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:37,065 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:37,455 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:37,857 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:38,237 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:38,639 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:39,019 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:39,400 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:39,773 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:39,879 WARNING experiment_state.py:371 -- Experiment checkpoint syncing has been triggered multiple times in the last 30.0 seconds. A sync will be triggered whenever a trial has checkpointed more than `num_to_keep` times since last sync or if 300 seconds have passed since last sync. If you have set `num_to_keep` in your `CheckpointConfig`, consider increasing the checkpoint frequency or keeping more checkpoints. You can supress this warning by changing the `TUNE_WARN_EXCESSIVE_EXPERIMENT_CHECKPOINT_SYNC_THRESHOLD_S` environment variable.
2023-08-25 17:42:39,882 INFO tune.py:1147 -- Total run time: 12.52 seconds (12.42 seconds for the tuning loop).
从目录加载实验结果#
尽管我们在内存中拥有 result_grid 对象,因为我们刚刚运行了上面的调优实验,但我们可能是在初始训练脚本退出后进行此分析。我们可以从 恢复的 Tuner 中检索 ResultGrid,传入实验目录,该目录应类似于 ~/ray_results/{exp_name}。如果你在 RunConfig 中未指定实验 name,实验名称将自动生成,且可以在实验的日志中找到。
experiment_path = os.path.join(storage_path, exp_name)
print(f"Loading results from {experiment_path}...")
restored_tuner = tune.Tuner.restore(experiment_path, trainable=train_mnist)
result_grid = restored_tuner.get_results()
Loading results from /tmp/ray_results/tune_analyzing_results...
实验级分析:使用 ResultGrid#
我们首先想要检查的是是否有任何错误的试验。
# 检查是否有错误
if result_grid.errors:
print("One of the trials failed!")
else:
print("No errors!")
No errors!
注意到 ResultGrid 是一个可迭代的对象,我们可以访问它的长度并通过索引来访问单个 Result 对象。
在这个例子中我们应该有 9 个结果,因为我们对每个 3 个网格搜索值有 3 个样本。
num_results = len(result_grid)
print("Number of results:", num_results)
Number of results: 9
# 遍历结果
for i, result in enumerate(result_grid):
if result.error:
print(f"Trial #{i} had an error:", result.error)
continue
print(
f"Trial #{i} finished successfully with a mean accuracy metric of:",
result.metrics["mean_accuracy"]
)
Trial #0 finished successfully with a mean accuracy metric of: 0.953125
Trial #1 finished successfully with a mean accuracy metric of: 0.9625
Trial #2 finished successfully with a mean accuracy metric of: 0.95625
Trial #3 finished successfully with a mean accuracy metric of: 0.946875
Trial #4 finished successfully with a mean accuracy metric of: 0.925
Trial #5 finished successfully with a mean accuracy metric of: 0.934375
Trial #6 finished successfully with a mean accuracy metric of: 0.965625
Trial #7 finished successfully with a mean accuracy metric of: 0.95625
Trial #8 finished successfully with a mean accuracy metric of: 0.94375
在上面,我们通过遍历 result_grid 打印了所有试验的最后报告的 mean_accuracy 指标。我们可以在一个 pandas DataFrame 中访问所有试验的相同指标。
results_df = result_grid.get_dataframe()
results_df[["training_iteration", "mean_accuracy"]]
| training_iteration | mean_accuracy | |
|---|---|---|
| 0 | 100 | 0.953125 |
| 1 | 100 | 0.962500 |
| 2 | 100 | 0.956250 |
| 3 | 100 | 0.946875 |
| 4 | 100 | 0.925000 |
| 5 | 100 | 0.934375 |
| 6 | 100 | 0.965625 |
| 7 | 100 | 0.956250 |
| 8 | 100 | 0.943750 |
print("Shortest training time:", results_df["time_total_s"].min())
print("Longest training time:", results_df["time_total_s"].max())
Shortest training time: 8.674914598464966
Longest training time: 8.945653676986694
最后报告的指标可能不包含每个试验所达到的最佳准确率。如果我们想要获取每个试验在整个训练过程中报告的最大准确率,可以通过使用 get_dataframe() 来实现,指定一个指标和模式以筛选每个试验的训练历史。
best_result_df = result_grid.get_dataframe(
filter_metric="mean_accuracy", filter_mode="max"
)
best_result_df[["training_iteration", "mean_accuracy"]]
| training_iteration | mean_accuracy | |
|---|---|---|
| 0 | 50 | 0.968750 |
| 1 | 55 | 0.975000 |
| 2 | 95 | 0.975000 |
| 3 | 71 | 0.978125 |
| 4 | 65 | 0.959375 |
| 5 | 77 | 0.965625 |
| 6 | 82 | 0.975000 |
| 7 | 80 | 0.968750 |
| 8 | 92 | 0.975000 |
试验级分析:处理单个 Result#
让我们来看一下以最佳 mean_accuracy 指标结束的结果。默认情况下,get_best_result 将使用上述 TuneConfig 中定义的相同指标和模式。不过,也可以指定一个新的指标/结果排序方式。
from ray.train import Result
# 获取测试集`mean_accuracy`最高的那个结果
best_result: Result = result_grid.get_best_result()
# 获取具有最小 `mean_accuracy` 的结果
worst_performing_result: Result = result_grid.get_best_result(
metric="mean_accuracy", mode="min"
)
我们可以检查最佳 Result 的一些属性。有关所有可访问属性的列表,请参见 API 参考。
首先,我们可以通过 Result.config 访问最佳结果的超参数配置。
best_result.config
{'lr': 0.009781335971854077, 'momentum': 0.9, 'should_checkpoint': True}
接下来,我们可以通过 Result.path 访问试验目录。结果 path 提供了试验级别的目录,其中包含检查点(如果您报告了任何)和记录的指标,以便手动加载或使用像 Tensorboard 这样的工具进行检查(见 result.json,progress.csv)。
best_result.path
'/tmp/ray_results/tune_analyzing_results/train_mnist_6e465_00007_7_lr=0.0098,momentum=0.9000_2023-08-25_17-42-27'
您也可以通过 Result.checkpoint 直接获取特定试验的最新检查点。
# 获取与表现最佳的试验相关联的最后一个检查点
best_result.checkpoint
Checkpoint(filesystem=local, path=/tmp/ray_results/tune_analyzing_results/train_mnist_6e465_00007_7_lr=0.0098,momentum=0.9000_2023-08-25_17-42-27/checkpoint_000099)
您还可以通过 Result.metrics 获取与特定试验相关的最新报告指标。
# 获取最新报告的一组指标
best_result.metrics
{'mean_accuracy': 0.965625,
'timestamp': 1693010559,
'should_checkpoint': True,
'done': True,
'training_iteration': 100,
'trial_id': '6e465_00007',
'date': '2023-08-25_17-42-39',
'time_this_iter_s': 0.08028697967529297,
'time_total_s': 8.77775764465332,
'pid': 94910,
'node_ip': '127.0.0.1',
'config': {'lr': 0.009781335971854077,
'momentum': 0.9,
'should_checkpoint': True},
'time_since_restore': 8.77775764465332,
'iterations_since_restore': 100,
'checkpoint_dir_name': 'checkpoint_000099',
'experiment_tag': '7_lr=0.0098,momentum=0.9000'}
访问Result的所有报告指标的历史记录,作为一个pandas DataFrame:
result_df = best_result.metrics_dataframe
result_df[["training_iteration", "mean_accuracy", "time_total_s"]]
| training_iteration | mean_accuracy | time_total_s | |
|---|---|---|---|
| 0 | 1 | 0.168750 | 0.111393 |
| 1 | 2 | 0.609375 | 0.195086 |
| 2 | 3 | 0.800000 | 0.283543 |
| 3 | 4 | 0.840625 | 0.388538 |
| 4 | 5 | 0.840625 | 0.479402 |
| ... | ... | ... | ... |
| 95 | 96 | 0.946875 | 8.415694 |
| 96 | 97 | 0.943750 | 8.524299 |
| 97 | 98 | 0.956250 | 8.606126 |
| 98 | 99 | 0.934375 | 8.697471 |
| 99 | 100 | 0.965625 | 8.777758 |
100 rows × 3 columns
绘制指标#
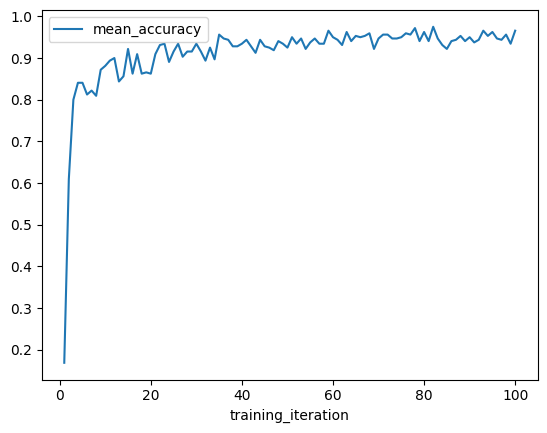
我们可以使用指标数据框快速可视化学习曲线。首先,让我们绘制最佳结果的平均准确率与训练迭代次数的关系图。
best_result.metrics_dataframe.plot("training_iteration", "mean_accuracy")
<AxesSubplot:xlabel='training_iteration'>
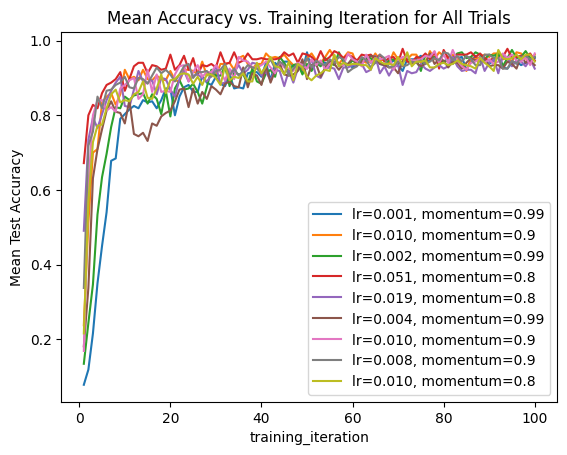
我们还可以遍历整个结果集,并创建一个所有试验的组合图,其中超参数作为标签。
ax = None
for result in result_grid:
label = f"lr={result.config['lr']:.3f}, momentum={result.config['momentum']}"
if ax is None:
ax = result.metrics_dataframe.plot("training_iteration", "mean_accuracy", label=label)
else:
result.metrics_dataframe.plot("training_iteration", "mean_accuracy", ax=ax, label=label)
ax.set_title("Mean Accuracy vs. Training Iteration for All Trials")
ax.set_ylabel("Mean Test Accuracy")
Text(0, 0.5, 'Mean Test Accuracy')
访问检查点及加载进行测试推断#
我们之前看到Result包含与试验相关的最后一个检查点。现在我们来看如何使用这个检查点加载一个模型,以便对一些示例MNIST图像进行推断。
import torch
from ray.tune.examples.mnist_pytorch import ConvNet, get_data_loaders
model = ConvNet()
with best_result.checkpoint.as_directory() as checkpoint_dir:
# 训练函数已将模型状态字典保存于 `model.pt` 文件中。
# 从 `ray.tune.examples.mnist_pytorch` 导入
model.load_state_dict(torch.load(os.path.join(checkpoint_dir, "model.pt")))
请参阅训练循环定义 here,了解我们是如何保存检查点的。
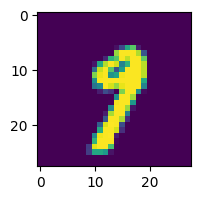
接下来,让我们使用一个样本数据点测试我们的模型,并打印出预测的类别。
import matplotlib.pyplot as plt
_, test_loader = get_data_loaders()
test_img = next(iter(test_loader))[0][0]
predicted_class = torch.argmax(model(test_img)).item()
print("Predicted Class =", predicted_class)
# 需要重塑为 (批量大小, 通道数, 宽度, 高度)
test_img = test_img.numpy().reshape((1, 1, 28, 28))
plt.figure(figsize=(2, 2))
plt.imshow(test_img.reshape((28, 28)))
Predicted Class = 9
<matplotlib.image.AxesImage at 0x31ddd2fd0>
考虑使用 Ray Data,如果您想要对大规模推理使用检查点模型!
总结#
在本指南中,我们查看了一些可以使用 Tuner.fit 返回的 ResultGrid 输出执行的常见分析工作流程。这些包括:从实验目录加载结果、探索实验级和试验级结果、绘制记录的指标,以及访问试验检查点进行推断。
请查看 Tune 的实验跟踪集成,了解您可以通过一些回调函数在 Tune 实验中构建的更多分析工具!