Ray Train 概述#
要有效地使用 Ray Train,你需要理解四个主要概念:
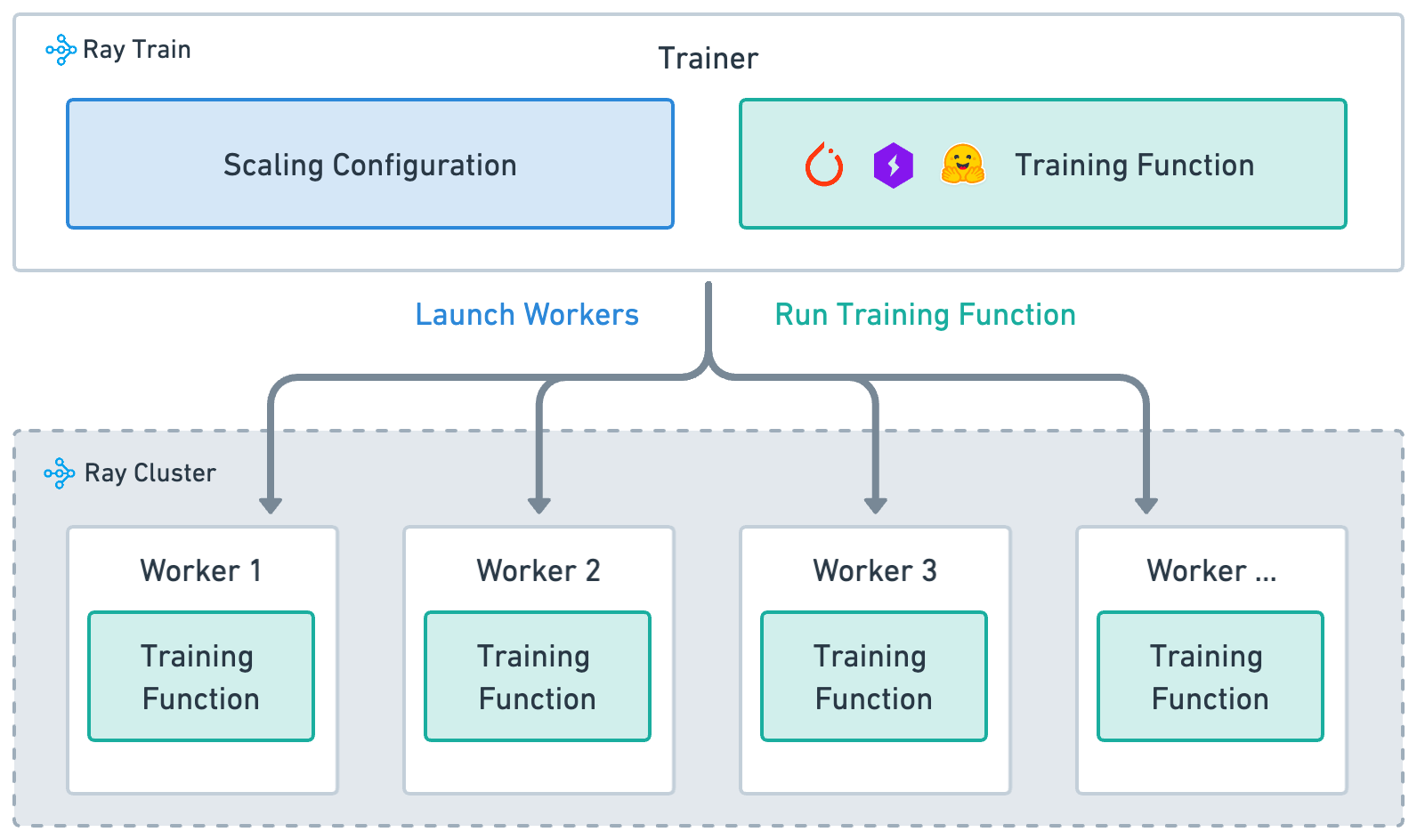
训练函数: 包含模型训练逻辑的Python函数。
Worker: 运行训练函数的进程。
扩展配置: 工作节点数量和计算资源(例如,CPU或GPU)的配置。
训练器: 一个Python类,它将训练函数、工作节点和扩展配置绑定在一起,以执行分布式训练任务。
训练函数#
训练函数是一个用户定义的Python函数,包含端到端的模型训练循环逻辑。当启动分布式训练任务时,每个工作节点执行此训练函数。
Ray Train 文档使用以下约定:
train_func是一个包含训练代码的用户定义函数。train_func被传递到 Trainer 的train_loop_per_worker参数中。
def train_func():
"""User-defined training function that runs on each distributed worker process.
This function typically contains logic for loading the model,
loading the dataset, training the model, saving checkpoints,
and logging metrics.
"""
...
工人#
Ray Train 将模型训练计算分布到集群中的各个工作进程。每个工作进程都是一个执行 train_func 的进程。工作进程的数量决定了训练作业的并行性,并在 ScalingConfig 中配置。
扩展配置#
The ScalingConfig 是定义训练任务规模的机制。为工作器并行性和计算资源指定两个基本参数:
num_workers: 为分布式训练任务启动的工作者数量。use_gpu: 每个工作线程是否应使用GPU或CPU。
from ray.train import ScalingConfig
# Single worker with a CPU
scaling_config = ScalingConfig(num_workers=1, use_gpu=False)
# Single worker with a GPU
scaling_config = ScalingConfig(num_workers=1, use_gpu=True)
# Multiple workers, each with a GPU
scaling_config = ScalingConfig(num_workers=4, use_gpu=True)
训练师#
Trainer 将前三个概念结合起来,以启动分布式训练任务。Ray Train 提供了不同框架的 训练器类。调用 fit() 方法通过以下步骤执行训练任务:
根据 scaling_config 定义启动工作节点。
在所有工作节点上设置框架的分布式环境。
在所有工作节点上运行
train_func。
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(train_func, scaling_config=scaling_config)
trainer.fit()
