调整试验调度器 (tune.schedulers)#
在Tune中,一些超参数优化算法被编写为“调度算法”。这些试验调度器可以提前终止不良试验、暂停试验、克隆试验,以及修改运行中试验的超参数。
所有试验调度器都接收一个 metric,这是一个在你的可训练对象的结果字典中返回的值,并根据 mode 进行最大化或最小化。
from ray import train, tune
from tune.schedulers import ASHAScheduler
def train_fn(config):
# This objective function is just for demonstration purposes
train.report({"loss": config["param"]})
tuner = tune.Tuner(
train_fn,
tune_config=tune.TuneConfig(
scheduler=ASHAScheduler(),
metric="loss",
mode="min",
num_samples=10,
),
param_space={"param": tune.uniform(0, 1)},
)
results = tuner.fit()
ASHA (tune.schedulers.ASHAScheduler)#
ASHA 调度器可以通过设置 tune.TuneConfig 的 scheduler 参数来使用,该参数由 Tuner 接收,例如:
from ray import tune
from tune.schedulers import ASHAScheduler
asha_scheduler = ASHAScheduler(
time_attr='training_iteration',
metric='loss',
mode='min',
max_t=100,
grace_period=10,
reduction_factor=3,
brackets=1,
)
tuner = tune.Tuner(
train_fn,
tune_config=tune.TuneConfig(scheduler=asha_scheduler),
)
results = tuner.fit()
与HyperBand的原始版本相比,此实现提供了更好的并行性,并在淘汰过程中避免了滞后问题。我们建议使用此版本而非标准的HyperBand调度器。 此实现的示例可以在此处找到:异步 HyperBand 示例。
尽管原文提到括号数量为3,但与作者的讨论结果认为该值应保留为1个括号。如果没有为 brackets 参数提供值,则这是默认使用的值。
实现异步连续减半。 |
|
HyperBand (tune.schedulers.HyperBandScheduler)#
Tune 实现了 HyperBand 的标准版本。我们推荐使用 ASHA 调度器而不是标准的 HyperBand 调度器。
实现了 HyperBand 早期停止算法。 |
HyperBand 实现细节#
实现细节可能与理论略有偏差,但专注于提高可用性。注意:R、s_max 和 eta 是 HyperBand 的参数,由论文给出。有关上下文,请参阅 这篇文章。
s_max``(表示 ``括号数量 - 1)和 ``eta``(表示下采样率)都是固定的。在许多实际应用中,
R代表某种资源单位,通常是训练迭代次数,可以设置得相当大,例如R >= 200。为简单起见,假设eta = 3。在R = 200和R = 1000之间变化R会创建一个巨大的试验次数范围,以填满所有括号。
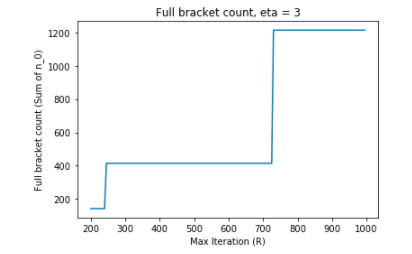
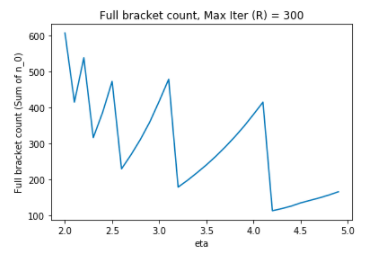
另一方面,将 R 固定在 R = 300 并改变 eta 也会导致不太直观的 HyperBand 配置:
该实现采用了与论文中给出的示例相同的配置,并公开了 max_t,这在论文中并不是一个参数。
- 在 post 中的示例用于计算
n_0 实际上与论文中给出的算法略有不同。在这个实现中,我们根据论文实现
n_0(在下例中为n):
- 在 post 中的示例用于计算

- 还有一些实现细节,比如试验如何分组到括号中,这些内容在论文中没有涉及。
此实现根据较小的括号将试验放置在括号内 - 这意味着在试验次数较少的情况下,早期停止的情况会减少。
中位数停止规则 (tune.schedulers.MedianStoppingRule)#
中位数停止规则实现了这样一个简单的策略:如果在相似时间点上,一个试验的表现低于其他试验的中位数,则停止该试验。
实现了Vizier论文中描述的中位数停止规则: |
基于种群的训练 (tune.schedulers.PopulationBasedTraining)#
Tune 包含了一个分布式的 Population Based Training (PBT) 实现。这可以通过设置 tune.TuneConfig 的 scheduler 参数来启用,该参数由 Tuner 接收,例如:
from ray import tune
from ray.tune.schedulers import PopulationBasedTraining
pbt_scheduler = PopulationBasedTraining(
time_attr='training_iteration',
metric='loss',
mode='min',
perturbation_interval=1,
hyperparam_mutations={
"lr": [1e-3, 5e-4, 1e-4, 5e-5, 1e-5],
"alpha": tune.uniform(0.0, 1.0),
}
)
tuner = tune.Tuner(
train_fn,
tune_config=tune.TuneConfig(
num_samples=4,
scheduler=pbt_scheduler,
),
)
tuner.fit()
当启用 PBT 调度器时,每个试验变体都被视为种群的一员。定期地,表现最好的试验会被检查点保存**(这要求您的 Trainable 支持 :ref:`保存和恢复 <tune-trial-checkpoint>`)。**表现较差的试验会克隆表现最好者的超参数配置并对其进行轻微扰动,以期发现更好的超参数设置。表现较差的试验还会从表现最好者的检查点恢复,使得试验能够从部分训练的模型开始探索新的超参数配置(例如,通过从表现最好的试验之一复制模型权重)。
查看 可视化基于人群的训练 (PBT) 超参数优化 以了解PBT的运作方式。 基于种群的训练指南 提供了更多PBT使用的示例。
实现了基于种群的训练(Population Based Training, PBT)算法。 |
基于种群的训练重放 (tune.schedulers.PopulationBasedTrainingReplay)#
Tune 包含一个实用工具,用于重放基于群体训练运行的超参数调度。您只需指定一个现有的实验目录和您希望重放的试验的ID。调度器只接受一个试验,并会根据获得的调度更新其配置。
from ray import tune
from ray.tune.schedulers import PopulationBasedTrainingReplay
replay = PopulationBasedTrainingReplay(
experiment_dir="~/ray_results/pbt_experiment/",
trial_id="XXXXX_00001"
)
tuner = tune.Tuner(
train_fn,
tune_config=tune.TuneConfig(scheduler=replay)
)
results = tuner.fit()
参见 这里 的示例,了解如何在实践中使用重放工具。
重放基于种群的训练运行。 |
基于种群的Bandits (PB2) (tune.schedulers.pb2.PB2)#
Tune 包含了一个分布式的 Population Based Bandits (PB2) 实现。该算法基于 PBT,主要区别在于 PB2 使用高斯过程模型来选择新的超参数配置,而不是使用随机扰动。
PB2 的 Tune 实现需要安装 GPy 和 sklearn:
pip install GPy scikit-learn
可以通过设置 tune.TuneConfig 的 scheduler 参数来启用 PB2,该参数由 Tuner 接收,例如:
from ray.tune.schedulers.pb2 import PB2
pb2_scheduler = PB2(
time_attr='time_total_s',
metric='mean_accuracy',
mode='max',
perturbation_interval=600.0,
hyperparam_bounds={
"lr": [1e-3, 1e-5],
"alpha": [0.0, 1.0],
...
}
)
tuner = tune.Tuner( ... , tune_config=tune.TuneConfig(scheduler=pb2_scheduler))
results = tuner.fit()
当启用 PB2 调度器时,每个试验变体都被视为种群的一员。定期地,表现最好的试验会被检查点保存(这要求您的 Trainable 支持 保存和恢复)。表现较差的试验会克隆表现最好的试验的检查点,并扰动配置,以期发现更好的变体。
PB2 的主要动机是能够在只有少量种群规模的情况下找到有潜力的超参数。考虑到这一点,你可以运行这个 PB2 PPO 示例 来比较 PB2 与 PBT,种群规模为 4``(如论文中所述)。该示例使用了 ``BipedalWalker 环境,因此不需要任何额外的许可证。
实现了基于种群的Bandit(PB2)算法。 |
BOHB (tune.schedulers.HyperBandForBOHB)#
此类是 HyperBand 的一个变体,启用了 BOHB 算法。此实现忠实于原始 HyperBand 实现,未实现流水线处理也未实现落后者缓解。
这将与 Tune BOHB 搜索算法结合使用。有关包要求、示例和详细信息,请参阅 TuneBOHB。
使用中的一个例子可以在这里找到:BOHB Example。
扩展了BOHB的超带早期停止算法。 |
ResourceChangingScheduler#
此类是一个实用调度器,允许在调优过程中更改试验资源需求。它包装了另一个调度器并使用其决策。
- 如果你正在使用可训练(类)API进行调优,你的可训练对象必须实现
Trainable.update_resources。 这将让您的模型了解新分配的资源。您还可以通过调用
Trainable.trial_resources来获取当前试验的资源。
- 如果你正在使用可训练(类)API进行调优,你的可训练对象必须实现
- 如果你使用的是调优的功能性API,可以通过调用来获取当前试验的资源
tune.get_trial_resources()在训练函数内部。该函数应能够 :ref:`加载和保存检查点 <tune-function-trainable-checkpointing>`(后者最好在每次迭代时进行)。
使用中的一个示例可以在这里找到:XGBoost 动态资源示例。
一个实用调度器,用于动态更改实时试验的资源。 |
|
此类创建了一个基本的统一资源分配函数。 |
|
此类创建一个“TopJob”资源分配函数。 |
FIFOScheduler(默认调度器)#
简单的调度器,仅按提交顺序运行试验。 |
TrialScheduler 接口#
用于实现 Trial Scheduler 类的接口。 |
调用以选择一个新的试验来运行。 |
|
在每次试验返回的中间结果上调用。 |
|
试用完成的通知。 |
Shim 实例化 (tune.create_scheduler)#
还有一个shim函数,它根据提供的字符串构建调度器。如果你想使用的调度器经常变化(例如,通过CLI选项或配置文件指定调度器),这可能会很有用。
基于给定的字符串实例化一个调度器。 |