监控您的工作负载#
本节帮助您通过查看以下内容来调试和监控 Dataset 的执行:
Ray Data 仪表板#
Ray Data 在执行数据集时实时发出 Prometheus 指标。这些指标由数据集和操作符标记,并在 Ray 仪表板的多个视图中显示。
备注
大多数指标仅适用于使用映射操作的物理操作符。例如,由 map_batches()、map() 和 flat_map() 创建的物理操作符。
任务:Ray 数据概述#
要查看已在您的集群上运行的所有数据集的概览,请参阅 作业视图 中的 Ray 数据概览。此表在第一个数据集开始在集群上执行后出现,并显示数据集的详细信息,例如:
执行进度(以区块为单位)
执行状态(运行中、失败或已完成)
数据集开始/结束时间
数据集级别的指标(例如,所有操作符处理的总行数)
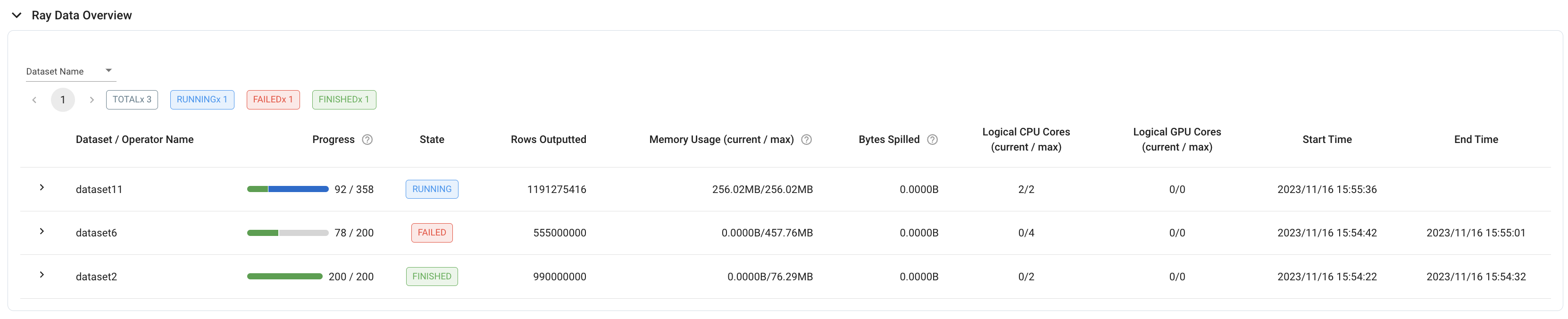
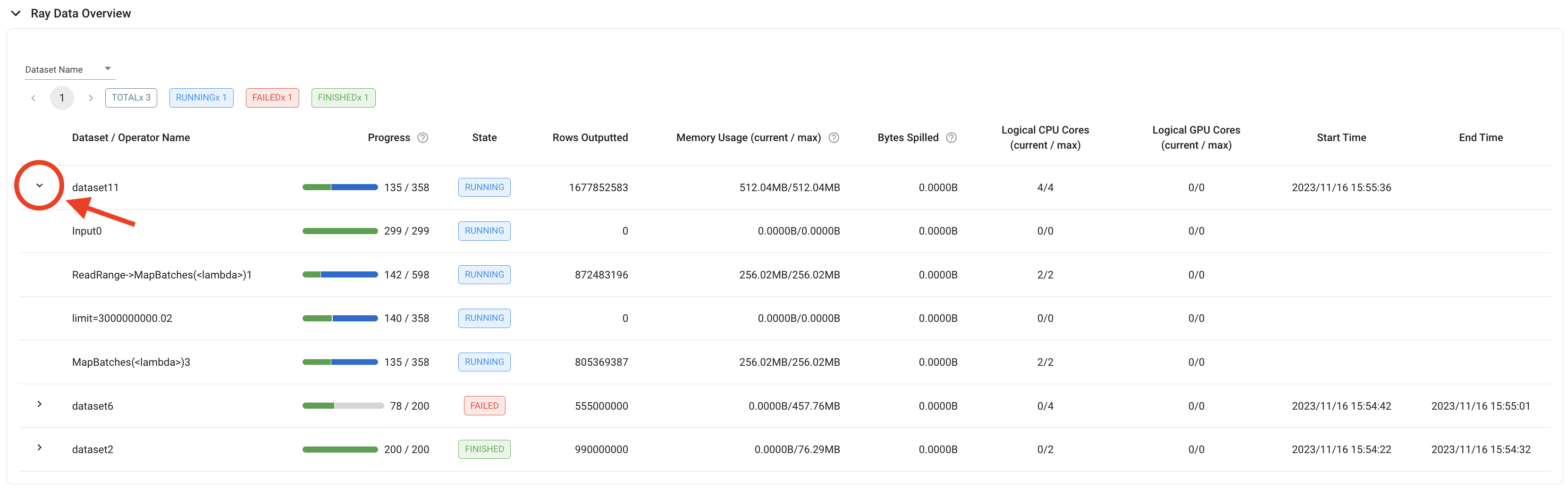
为了更细致的概览,表格中的每个数据集行也可以展开,以显示各个操作员的相同细节。
小技巧
在评估一个数据集级别的指标时,如果将所有单个操作符的值相加不合适,查看最后一个操作符的操作符级别指标可能会更有用。例如,要计算数据集的吞吐量,可以使用数据集最后一个操作符的“输出行数”,因为数据集级别的指标包含了所有操作符输出行的总和。
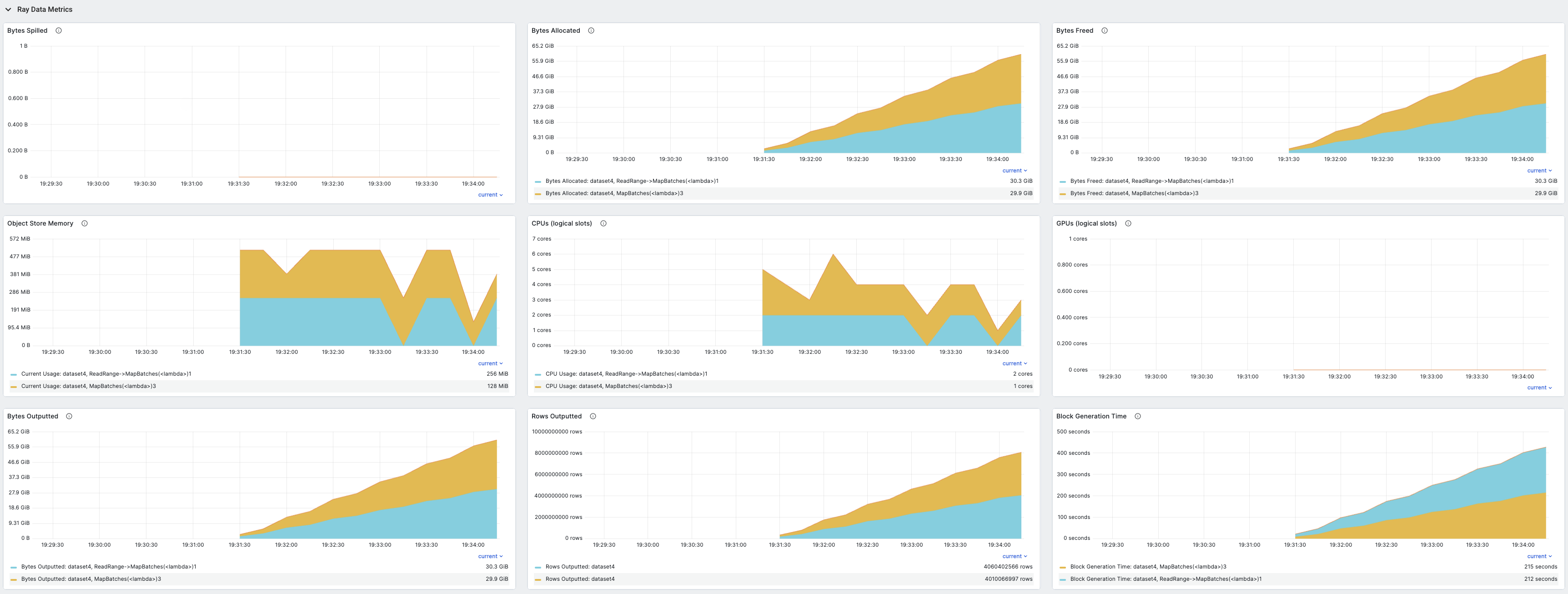
Ray 仪表盘指标#
要查看这些指标的时间序列视图,请参阅 指标视图 中的 Ray Data 部分。该部分包含 Ray Data 发出的所有指标的时间序列图。执行指标按数据集和操作符分组,迭代指标按数据集分组。
记录的指标包括:
对象存储中对象溢出到磁盘的字节数
对象存储中分配的对象字节数
对象存储中释放的对象字节数
对象存储中对象的当前总字节数
分配给数据集操作符的逻辑CPU
分配给数据集操作符的逻辑GPU
数据集操作输出的字节
数据集操作符输出的行
数据操作员接收的输入块
数据操作员在任务中处理的输入块/字节
数据操作员提交给任务的输入字节
数据操作员在任务中生成的输出块/字节/行
下游操作符占用的输出块/字节
从已完成任务输出块/字节
已提交的任务
运行任务
至少有一个输出块的任务
已完成任务
失败的任务
操作符内部队列大小(以块/字节为单位)
操作符内部输出队列大小(以块/字节为单位)
待处理任务中使用的块大小
对象存储中的释放内存
对象存储中的内存泄漏
生成区块所花费的时间
任务提交背压所花费的时间
初始化迭代所花费的时间。
迭代期间用户代码被阻塞的时间。
迭代期间在用户代码中花费的时间。
要了解更多关于 Ray 仪表盘的信息,包括详细的设置说明,请参阅 Ray 仪表盘。
Ray 数据日志#
在执行过程中,Ray Data 会定期将更新记录到 ray-data.log 中。
每五秒钟,Ray Data 会记录数据集中每个操作符的执行进度。如需更频繁的更新,请设置 RAY_DATA_TRACE_SCHEDULING=1,以便在每个任务分派后记录进度。
Execution Progress:
0: - Input: 0 active, 0 queued, 0.0 MiB objects, Blocks Outputted: 200/200
1: - ReadRange->MapBatches(<lambda>): 10 active, 190 queued, 381.47 MiB objects, Blocks Outputted: 100/200
当一个操作完成时,该操作的指标也会被记录。
Operator InputDataBuffer[Input] -> TaskPoolMapOperator[ReadRange->MapBatches(<lambda>)] completed. Operator Metrics:
{'num_inputs_received': 20, 'bytes_inputs_received': 46440, 'num_task_inputs_processed': 20, 'bytes_task_inputs_processed': 46440, 'num_task_outputs_generated': 20, 'bytes_task_outputs_generated': 800, 'rows_task_outputs_generated': 100, 'num_outputs_taken': 20, 'bytes_outputs_taken': 800, 'num_outputs_of_finished_tasks': 20, 'bytes_outputs_of_finished_tasks': 800, 'num_tasks_submitted': 20, 'num_tasks_running': 0, 'num_tasks_have_outputs': 20, 'num_tasks_finished': 20, 'obj_store_mem_freed': 46440, 'obj_store_mem_spilled': 0, 'block_generation_time': 1.191296085, 'cpu_usage': 0, 'gpu_usage': 0, 'ray_remote_args': {'num_cpus': 1, 'scheduling_strategy': 'SPREAD'}}
该日志文件可以在本地 /tmp/ray/{SESSION_NAME}/logs/ray-data/ray-data.log 找到。它也可以在 Ray Dashboard 的头节点日志中找到,位于 日志视图。
Ray 数据统计#
要查看数据集执行的详细统计信息,可以使用 stats() 方法。
操作员统计#
统计输出包括每个操作符执行统计的摘要。Ray Data 在许多不同的块上计算此摘要,因此某些统计数据显示了所有块上聚合统计的最小值、最大值、平均值和总和。以下是操作符级别包含的各种统计数据的描述:
远程挂钟时间:挂钟时间是操作员从开始到结束的时间。它包括操作员不处理数据、休眠、等待I/O等的时间。
远程CPU时间:CPU时间是操作符的进程时间,不包括睡眠时间。这个时间包括用户和系统CPU时间。
UDF 时间:UDF 时间是用户定义函数中花费的时间。这包括您传递给 Ray Data 方法的时间,包括
map()、map_batches()、filter()等。您可以使用此统计信息来跟踪在您定义的函数中花费的时间,以及优化这些函数可以节省多少时间。内存使用:输出显示每个块的内存使用情况,单位为 MiB。
输出统计:输出包括每个块输出的行数和字节大小的统计信息。还包括每个任务的输出行数。所有这些信息一起让您了解 Ray Data 在每个块和每个任务级别输出的数据量。
任务统计: 输出显示了任务分配到节点的调度情况,这使您能够查看是否如预期那样利用了所有节点。
吞吐量:该摘要计算了操作符的吞吐量,并且为了便于比较,还估算了在单个节点上执行相同任务的吞吐量。该估算假设工作总时间保持不变,但没有并发性。总体摘要还计算了数据集级别的吞吐量,包括单节点估算。
迭代器统计#
如果你遍历数据,Ray Data 也会生成迭代统计信息。即使你没有直接遍历数据,你也可能看到迭代统计信息,例如,如果你调用 take_all()。Ray Data 在迭代器级别包含的一些统计信息有:
迭代器初始化:Ray Data 花费在初始化迭代器上的时间。这部分时间是 Ray Data 内部的。
用户线程被阻塞的时间:Ray Data 在迭代器中生成数据所花费的时间。如果你之前没有具体化数据集,这段时间通常是数据集的主要执行时间。
用户线程中的时间:在 Ray Data 代码之外,用户线程迭代数据集所花费的时间。如果此时间较长,请考虑优化迭代数据集的循环体。
批处理迭代统计: Ray Data 还包括关于批处理预取的统计信息。这些时间是 Ray Data 代码内部的,但您可以通过调整预取过程来进一步优化这个时间。
详细统计#
默认情况下,Ray Data 只记录最重要的高级统计信息。要启用详细的统计输出,请在 Ray Data 代码中包含以下代码片段:
from ray.data import DataContext
context = DataContext.get_current()
context.verbose_stats_logs = True
通过启用详细模式,Ray Data 会添加一些额外的输出:
额外指标:操作员、执行器等可以向这个包含各种指标的字典中添加内容。默认输出和这个字典之间存在一些统计数据的重复,但对于高级用户来说,这个统计数据提供了对数据集执行情况的更深入的洞察。
运行时指标: 这些指标是数据集执行运行时的高级细分。这些统计数据是每个操作符的摘要,显示每个操作符完成所需的时间以及该操作符完成所需的总执行时间的比例。由于可能存在多个并发操作符,这些百分比不一定总和为100%。相反,它们显示了在完整数据集执行的上下文中,每个操作符的运行时间。
示例统计#
作为一个具体的例子,下面是一个来自 使用PyTorch ResNet18进行图像分类批量推理 的统计输出:
Operator 1 ReadImage->Map(preprocess_image): 384 tasks executed, 386 blocks produced in 9.21s
* Remote wall time: 33.55ms min, 2.22s max, 1.03s mean, 395.65s total
* Remote cpu time: 34.93ms min, 3.36s max, 1.64s mean, 632.26s total
* UDF time: 535.1ms min, 2.16s max, 975.7ms mean, 376.62s total
* Peak heap memory usage (MiB): 556.32 min, 1126.95 max, 655 mean
* Output num rows per block: 4 min, 25 max, 24 mean, 9469 total
* Output size bytes per block: 6060399 min, 105223020 max, 31525416 mean, 12168810909 total
* Output rows per task: 24 min, 25 max, 24 mean, 384 tasks used
* Tasks per node: 32 min, 64 max, 48 mean; 8 nodes used
* Operator throughput:
* Ray Data throughput: 1028.5218637702708 rows/s
* Estimated single node throughput: 23.932674100499128 rows/s
Operator 2 MapBatches(ResnetModel): 14 tasks executed, 48 blocks produced in 27.43s
* Remote wall time: 523.93us min, 7.01s max, 1.82s mean, 87.18s total
* Remote cpu time: 523.23us min, 6.23s max, 1.76s mean, 84.61s total
* UDF time: 4.49s min, 17.81s max, 10.52s mean, 505.08s total
* Peak heap memory usage (MiB): 4025.42 min, 7920.44 max, 5803 mean
* Output num rows per block: 84 min, 334 max, 197 mean, 9469 total
* Output size bytes per block: 72317976 min, 215806447 max, 134739694 mean, 6467505318 total
* Output rows per task: 319 min, 720 max, 676 mean, 14 tasks used
* Tasks per node: 3 min, 4 max, 3 mean; 4 nodes used
* Operator throughput:
* Ray Data throughput: 345.1533728632648 rows/s
* Estimated single node throughput: 108.62003864820711 rows/s
Dataset iterator time breakdown:
* Total time overall: 38.53s
* Total time in Ray Data iterator initialization code: 16.86s
* Total time user thread is blocked by Ray Data iter_batches: 19.76s
* Total execution time for user thread: 1.9s
* Batch iteration time breakdown (summed across prefetch threads):
* In ray.get(): 70.49ms min, 2.16s max, 272.8ms avg, 13.09s total
* In batch creation: 3.6us min, 5.95us max, 4.26us avg, 204.41us total
* In batch formatting: 4.81us min, 7.88us max, 5.5us avg, 263.94us total
Dataset throughput:
* Ray Data throughput: 1026.5318925757008 rows/s
* Estimated single node throughput: 19.611578909587674 rows/s
对于启用了详细模式的相同示例,统计输出如下:
Operator 1 ReadImage->Map(preprocess_image): 384 tasks executed, 387 blocks produced in 9.49s
* Remote wall time: 22.81ms min, 2.5s max, 999.95ms mean, 386.98s total
* Remote cpu time: 24.06ms min, 3.36s max, 1.63s mean, 629.93s total
* UDF time: 552.79ms min, 2.41s max, 956.84ms mean, 370.3s total
* Peak heap memory usage (MiB): 550.95 min, 1186.28 max, 651 mean
* Output num rows per block: 4 min, 25 max, 24 mean, 9469 total
* Output size bytes per block: 4444092 min, 105223020 max, 31443955 mean, 12168810909 total
* Output rows per task: 24 min, 25 max, 24 mean, 384 tasks used
* Tasks per node: 39 min, 60 max, 48 mean; 8 nodes used
* Operator throughput:
* Ray Data throughput: 997.9207015895857 rows/s
* Estimated single node throughput: 24.46899945870273 rows/s
* Extra metrics: {'num_inputs_received': 384, 'bytes_inputs_received': 1104723940, 'num_task_inputs_processed': 384, 'bytes_task_inputs_processed': 1104723940, 'bytes_inputs_of_submitted_tasks': 1104723940, 'num_task_outputs_generated': 387, 'bytes_task_outputs_generated': 12168810909, 'rows_task_outputs_generated': 9469, 'num_outputs_taken': 387, 'bytes_outputs_taken': 12168810909, 'num_outputs_of_finished_tasks': 387, 'bytes_outputs_of_finished_tasks': 12168810909, 'num_tasks_submitted': 384, 'num_tasks_running': 0, 'num_tasks_have_outputs': 384, 'num_tasks_finished': 384, 'num_tasks_failed': 0, 'block_generation_time': 386.97945193799995, 'task_submission_backpressure_time': 7.263684450000142, 'obj_store_mem_internal_inqueue_blocks': 0, 'obj_store_mem_internal_inqueue': 0, 'obj_store_mem_internal_outqueue_blocks': 0, 'obj_store_mem_internal_outqueue': 0, 'obj_store_mem_pending_task_inputs': 0, 'obj_store_mem_freed': 1104723940, 'obj_store_mem_spilled': 0, 'obj_store_mem_used': 12582535566, 'cpu_usage': 0, 'gpu_usage': 0, 'ray_remote_args': {'num_cpus': 1, 'scheduling_strategy': 'SPREAD'}}
Operator 2 MapBatches(ResnetModel): 14 tasks executed, 48 blocks produced in 28.81s
* Remote wall time: 134.84us min, 7.23s max, 1.82s mean, 87.16s total
* Remote cpu time: 133.78us min, 6.28s max, 1.75s mean, 83.98s total
* UDF time: 4.56s min, 17.78s max, 10.28s mean, 493.48s total
* Peak heap memory usage (MiB): 3925.88 min, 7713.01 max, 5688 mean
* Output num rows per block: 125 min, 259 max, 197 mean, 9469 total
* Output size bytes per block: 75531617 min, 187889580 max, 134739694 mean, 6467505318 total
* Output rows per task: 325 min, 719 max, 676 mean, 14 tasks used
* Tasks per node: 3 min, 4 max, 3 mean; 4 nodes used
* Operator throughput:
* Ray Data throughput: 328.71474145609153 rows/s
* Estimated single node throughput: 108.6352856660782 rows/s
* Extra metrics: {'num_inputs_received': 387, 'bytes_inputs_received': 12168810909, 'num_task_inputs_processed': 0, 'bytes_task_inputs_processed': 0, 'bytes_inputs_of_submitted_tasks': 12168810909, 'num_task_outputs_generated': 1, 'bytes_task_outputs_generated': 135681874, 'rows_task_outputs_generated': 252, 'num_outputs_taken': 1, 'bytes_outputs_taken': 135681874, 'num_outputs_of_finished_tasks': 0, 'bytes_outputs_of_finished_tasks': 0, 'num_tasks_submitted': 14, 'num_tasks_running': 14, 'num_tasks_have_outputs': 1, 'num_tasks_finished': 0, 'num_tasks_failed': 0, 'block_generation_time': 7.229860895999991, 'task_submission_backpressure_time': 0, 'obj_store_mem_internal_inqueue_blocks': 13, 'obj_store_mem_internal_inqueue': 413724657, 'obj_store_mem_internal_outqueue_blocks': 0, 'obj_store_mem_internal_outqueue': 0, 'obj_store_mem_pending_task_inputs': 12168810909, 'obj_store_mem_freed': 0, 'obj_store_mem_spilled': 0, 'obj_store_mem_used': 1221136866.0, 'cpu_usage': 0, 'gpu_usage': 4}
Dataset iterator time breakdown:
* Total time overall: 42.29s
* Total time in Ray Data iterator initialization code: 20.24s
* Total time user thread is blocked by Ray Data iter_batches: 19.96s
* Total execution time for user thread: 2.08s
* Batch iteration time breakdown (summed across prefetch threads):
* In ray.get(): 73.0ms min, 2.15s max, 246.3ms avg, 11.82s total
* In batch creation: 3.62us min, 6.6us max, 4.39us avg, 210.7us total
* In batch formatting: 4.75us min, 8.67us max, 5.52us avg, 264.98us total
Dataset throughput:
* Ray Data throughput: 468.11051989434594 rows/s
* Estimated single node throughput: 972.8197093015862 rows/s
Runtime Metrics:
* ReadImage->Map(preprocess_image): 9.49s (46.909%)
* MapBatches(ResnetModel): 28.81s (142.406%)
* Scheduling: 6.16s (30.448%)
* Total: 20.23s (100.000%)
