备注
Ray 2.10.0 引入了 RLlib 的“新 API 栈”的 alpha 阶段。Ray 团队计划将算法、示例脚本和文档迁移到新的代码库中,从而在 Ray 3.0 之前的后续小版本中逐步替换“旧 API 栈”(例如,ModelV2、Policy、RolloutWorker)。
然而,请注意,到目前为止,只有 PPO(单代理和多代理)和 SAC(仅单代理)支持“新 API 堆栈”,并且默认情况下继续使用旧 API 运行。您可以继续使用现有的自定义(旧堆栈)类。
请参阅此处 以获取有关如何使用新API堆栈的更多详细信息。
环境#
RLlib 支持多种不同类型的环境,包括 Farama-Foundation Gymnasium、用户自定义环境、多智能体环境以及批处理环境。
小技巧
并非所有环境都适用于所有算法。更多信息请参见 算法概览。

配置环境#
你可以传递一个字符串名称或一个Python类来指定环境。默认情况下,字符串将被解释为gym 环境名称。直接传递给算法的自定义环境类必须在它们的构造函数中接受一个``env_config``参数:
import gymnasium as gym
import ray
from ray.rllib.algorithms import ppo
class MyEnv(gym.Env):
def __init__(self, env_config):
self.action_space = <gym.Space>
self.observation_space = <gym.Space>
def reset(self, seed, options):
return <obs>, <info>
def step(self, action):
return <obs>, <reward: float>, <terminated: bool>, <truncated: bool>, <info: dict>
ray.init()
algo = ppo.PPO(env=MyEnv, config={
"env_config": {}, # config to pass to env class
})
while True:
print(algo.train())
你也可以用一个字符串名称注册一个自定义的环境创建函数。这个函数必须接受一个 env_config (字典) 参数并返回一个环境实例:
from ray.tune.registry import register_env
def env_creator(env_config):
return MyEnv(...) # return an env instance
register_env("my_env", env_creator)
algo = ppo.PPO(env="my_env")
有关使用自定义环境API的完整可运行代码示例,请参见 custom_env.py。
警告
体育馆注册表与 Ray 不兼容。相反,请始终使用上述文档中的注册流程,以确保 Ray 工作线程可以访问环境。
在上面的例子中,注意 env_creator 函数接受一个 env_config 对象。这是一个包含通过你的算法传递的选项的字典。你还可以访问 env_config.worker_index 和 env_config.vector_index 来获取工作器ID和在工作器内的环境ID(如果 num_envs_per_env_runner > 0)。如果你想在一个不同的环境集合上进行训练,这可能会很有用,例如:
class MultiEnv(gym.Env):
def __init__(self, env_config):
# pick actual env based on worker and env indexes
self.env = gym.make(
choose_env_for(env_config.worker_index, env_config.vector_index))
self.action_space = self.env.action_space
self.observation_space = self.env.observation_space
def reset(self, seed, options):
return self.env.reset(seed, options)
def step(self, action):
return self.env.step(action)
register_env("multienv", lambda config: MultiEnv(config))
小技巧
在使用日志记录的环境中,日志配置需要在环境中完成,该环境在 Ray 工作进程内运行。环境外的任何配置,例如在启动 Ray 之前,都将被忽略。
健身房#
RLlib 使用 Gymnasium 作为其单智能体训练的环境接口。有关如何实现自定义 Gymnasium 环境的更多信息,请参阅 gymnasium.Env 类定义。您可能会发现 SimpleCorridor 示例作为参考很有用。
性能#
小技巧
此外,请查看 RLlib 训练的扩展指南。
有两种方法可以扩展与 Gym 环境一起收集经验:
单进程内的向量化: 尽管许多环境可以在每个核心上实现高帧率,但它们的吞吐量实际上受限于步骤之间的策略评估。例如,即使是小型的 TensorFlow 模型也会产生几毫秒的评估延迟。这可以通过在每个进程中创建多个环境并在这些环境中批量进行策略评估来解决。
你可以配置
{"num_envs_per_env_runner": M}来让 RLlib 为每个工作线程创建M个并发环境。RLlib 通过 VectorEnv.wrap() 自动向量化 Gym 环境。
跨多个进程分布: 你也可以让 RLlib 创建多个进程(Ray 角色)用于经验收集。在大多数算法中,这可以通过设置
{"num_env_runners": N}配置来控制。
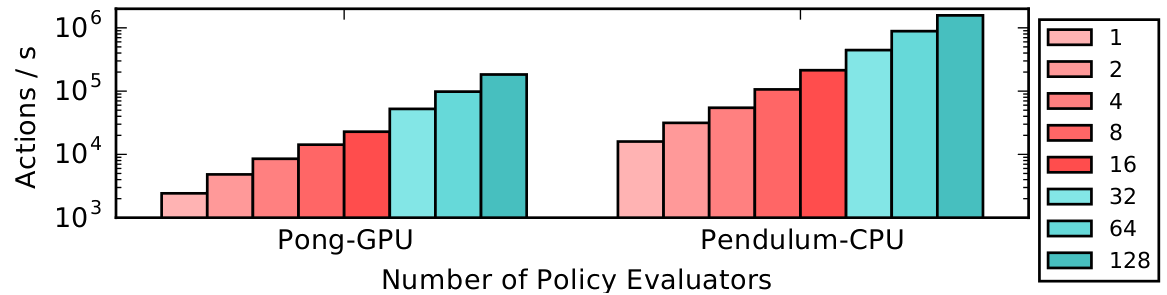
你也可以结合向量化和分布式执行,如上图所示。这里我们仅绘制了从1到128个CPU的RLlib策略评估吞吐量。PongNoFrameskip-v4在GPU上从2.4k扩展到∼200k动作/秒,而Pendulum-v1在CPU上从15k扩展到1.5M动作/秒。一台机器用于1-16个工作线程,一个由四台机器组成的Ray集群用于32-128个工作线程。每个工作线程配置为``num_envs_per_env_runner=64``。
昂贵的环境#
某些环境可能创建时非常消耗资源。RLlib 会创建 num_env_runners + 1 个环境的副本,因为需要一个副本用于驱动进程。为了避免支付驱动副本的额外开销,该副本用于访问环境的动作和观察空间,您可以将环境初始化推迟到 reset() 被调用时。
矢量化#
如果设置了 num_envs_per_env_runner 配置,RLlib 将自动向量化 Gym 环境以进行批量评估,或者您可以定义一个自定义环境类,该类继承自 VectorEnv 以实现 vector_step() 和 vector_reset()。
请注意,自动向量化默认仅适用于策略推理。这意味着策略推理将被批处理,但您的环境仍将一次一个地进行步骤。如果您希望您的环境并行进行步骤,可以设置 "remote_worker_envs": True。这将创建Ray角色中的环境实例并在并行中进行步骤。这些远程进程引入了通信开销,因此只有在您的环境进行步骤/重置非常昂贵时,这才有帮助。
在使用远程环境时,您可以通过 remote_env_batch_wait_ms 控制推理的批处理级别。默认值 0ms 表示环境异步执行,推理仅在有机会时进行批处理。将超时设置为较大的值将导致完全批处理的推理和有效的同步环境步骤。最佳值取决于您的环境步骤/重置时间和模型推理速度。
多智能体与层次结构#
在多智能体环境中,存在多个“智能体”同时行动,以回合制方式行动,或结合这两种方式。
例如,在交通模拟中,环境中可能会有多个“汽车”和“交通灯”代理同时行动。而在棋盘游戏中,你可能会有两个或更多的代理以轮流的方式行动。
RLlib 中多智能体的心理模型如下:(1) 你的环境(MultiAgentEnv 的子类)返回一个字典,该字典将智能体ID(例如字符串;环境可以任意选择这些ID)映射到各个智能体的观察、奖励和完成标志。(2) 你预先定义(部分)可用的策略(你也可以在训练过程中动态添加新策略),以及 (3) 你定义一个函数,该函数将环境生成的智能体ID映射到任何可用的策略ID,然后用于计算该特定智能体的动作。
这由下图总结:

在实现你自己的 MultiAgentEnv 时,请注意你只应在观察字典中返回那些你期望在下次调用 step() 时接收动作的代理ID。
此API允许您实现任何类型的多智能体环境,从 回合制游戏 到 所有智能体始终同时行动 的环境,再到两者之间的任何类型。
以下是一个环境的示例,其中所有代理总是同时行动:
# Env, in which all agents (whose IDs are entirely determined by the env
# itself via the returned multi-agent obs/reward/dones-dicts) step
# simultaneously.
env = MultiAgentTrafficEnv(num_cars=2, num_traffic_lights=1)
# Observations are a dict mapping agent names to their obs. Only those
# agents' names that require actions in the next call to `step()` should
# be present in the returned observation dict (here: all, as we always step
# simultaneously).
print(env.reset())
# ... {
# ... "car_1": [[...]],
# ... "car_2": [[...]],
# ... "traffic_light_1": [[...]],
# ... }
# In the following call to `step`, actions should be provided for each
# agent that returned an observation before:
new_obs, rewards, dones, infos = env.step(
actions={"car_1": ..., "car_2": ..., "traffic_light_1": ...})
# Similarly, new_obs, rewards, dones, etc. also become dicts.
print(rewards)
# ... {"car_1": 3, "car_2": -1, "traffic_light_1": 0}
# Individual agents can early exit; The entire episode is done when
# dones["__all__"] = True.
print(dones)
# ... {"car_2": True, "__all__": False}
另一个例子,其中代理一个接一个地行动(回合制游戏):
# Env, in which two agents step in sequence (tuen-based game).
# The env is in charge of the produced agent ID. Our env here produces
# agent IDs: "player1" and "player2".
env = TicTacToe()
# Observations are a dict mapping agent names to their obs. Only those
# agents' names that require actions in the next call to `step()` should
# be present in the returned observation dict (here: one agent at a time).
print(env.reset())
# ... {
# ... "player1": [[...]],
# ... }
# In the following call to `step`, only those agents' actions should be
# provided that were present in the returned obs dict:
new_obs, rewards, dones, infos = env.step(actions={"player1": ...})
# Similarly, new_obs, rewards, dones, etc. also become dicts.
# Note that only in the `rewards` dict, any agent may be listed (even those that have
# not(!) acted in the `step()` call). Rewards for individual agents will be added
# up to the point where a new action for that agent is needed. This way, you may
# implement a turn-based 2-player game, in which player-2's reward is published
# in the `rewards` dict immediately after player-1 has acted.
print(rewards)
# ... {"player1": 0, "player2": 0}
# Individual agents can early exit; The entire episode is done when
# dones["__all__"] = True.
print(dones)
# ... {"player1": False, "__all__": False}
# In the next step, it's player2's turn. Therefore, `new_obs` only container
# this agent's ID:
print(new_obs)
# ... {
# ... "player2": [[...]]
# ... }
如果所有代理都将使用相同的算法类进行训练,那么您可以按如下方式设置多代理训练:
algo = pg.PGAgent(env="my_multiagent_env", config={
"multiagent": {
"policies": {
# Use the PolicySpec namedtuple to specify an individual policy:
"car1": PolicySpec(
policy_class=None, # infer automatically from Algorithm
observation_space=None, # infer automatically from env
action_space=None, # infer automatically from env
config={"gamma": 0.85}, # use main config plus <- this override here
), # alternatively, simply do: `PolicySpec(config={"gamma": 0.85})`
# Deprecated way: Tuple specifying class, obs-/action-spaces,
# config-overrides for each policy as a tuple.
# If class is None -> Uses Algorithm's default policy class.
"car2": (None, car_obs_space, car_act_space, {"gamma": 0.99}),
# New way: Use PolicySpec() with keywords: `policy_class`,
# `observation_space`, `action_space`, `config`.
"traffic_light": PolicySpec(
observation_space=tl_obs_space, # special obs space for lights?
action_space=tl_act_space, # special action space for lights?
),
},
"policy_mapping_fn":
lambda agent_id, episode, worker, **kwargs:
"traffic_light" # Traffic lights are always controlled by this policy
if agent_id.startswith("traffic_light_")
else random.choice(["car1", "car2"]) # Randomly choose from car policies
},
})
while True:
print(algo.train())
要在 multiagent.policies 字典中排除某些策略,可以使用 multiagent.policies_to_train 设置。例如,您可能希望让一个或多个随机(非学习)策略与您的学习策略进行交互:
# Example for a mapping function that maps agent IDs "player1" and "player2" to either
# "random_policy" or "learning_policy", making sure that in each episode, both policies
# are always playing each other.
def policy_mapping_fn(agent_id, episode, worker, **kwargs):
agent_idx = int(agent_id[-1]) # 0 (player1) or 1 (player2)
# agent_id = "player[1|2]" -> policy depends on episode ID
# This way, we make sure that both policies sometimes play player1
# (start player) and sometimes player2 (player to move 2nd).
return "learning_policy" if episode.episode_id % 2 == agent_idx else "random_policy"
algo = pg.PGAgent(env="two_player_game", config={
"multiagent": {
"policies": {
"learning_policy": PolicySpec(), # <- use default class & infer obs-/act-spaces from env.
"random_policy": PolicySpec(policy_class=RandomPolicy), # infer obs-/act-spaces from env.
},
# Example for a mapping function that maps agent IDs "player1" and "player2" to either
# "random_policy" or "learning_policy", making sure that in each episode, both policies
# are always playing each other.
"policy_mapping_fn": policy_mapping_fn,
# Specify a (fixed) list (or set) of policy IDs that should be updated.
"policies_to_train": ["learning_policy"],
# Alternatively, you can provide a callable that returns True or False, when provided
# with a policy ID and an (optional) SampleBatch:
# "policies_to_train": lambda pid, batch: ... (<- return True or False)
# This allows you to more flexibly update (or not) policies, based on
# who they played with in the episode (or other information that can be
# found in the given batch, e.g. rewards).
},
})
RLlib 将创建三个不同的策略,并使用给定的 policy_mapping_fn 将代理决策路由到其绑定的策略。当代理首次出现在环境中时,policy_mapping_fn 将被调用以确定其绑定到哪个策略。RLlib 在 train() 的返回中为每个策略报告单独的训练统计数据,以及组合奖励。
这里有一个简单的 训练脚本示例 ,你可以在其中改变环境中代理和策略的数量。关于如何同时使用多种训练方法(这里使用DQN和PPO),请参见 两种算法的示例 。指标会分别报告给每个策略,例如:
Result for PPO_multi_cartpole_0:
episode_len_mean: 34.025862068965516
episode_return_max: 159.0
episode_return_mean: 86.06896551724138
info:
policy_0:
cur_lr: 4.999999873689376e-05
entropy: 0.6833480000495911
kl: 0.010264254175126553
policy_loss: -11.95590591430664
total_loss: 197.7039794921875
vf_explained_var: 0.0010995268821716309
vf_loss: 209.6578826904297
policy_1:
cur_lr: 4.999999873689376e-05
entropy: 0.6827034950256348
kl: 0.01119876280426979
policy_loss: -8.787769317626953
total_loss: 88.26161193847656
vf_explained_var: 0.0005457401275634766
vf_loss: 97.0471420288086
policy_reward_mean:
policy_0: 21.194444444444443
policy_1: 21.798387096774192
为了扩展到数百个代理(如果这些代理使用相同的策略),MultiAgentEnv 在内部对多个代理的策略评估进行批处理。您的 MultiAgentEnvs 也可以通过设置 num_envs_per_env_runner > 1 来自动向量化(就像普通的单一代理环境一样,例如 gym.Env)。
PettingZoo 多智能体环境#
PettingZoo 是一个包含超过50个多样化多智能体环境的仓库。然而,其API并不直接兼容rllib,但可以像这个例子中那样转换为rllib的MultiAgentEnv。
from ray.tune.registry import register_env
# import the pettingzoo environment
from pettingzoo.butterfly import prison_v3
# import rllib pettingzoo interface
from ray.rllib.env import PettingZooEnv
# define how to make the environment. This way takes an optional environment config, num_floors
env_creator = lambda config: prison_v3.env(num_floors=config.get("num_floors", 4))
# register that way to make the environment under an rllib name
register_env('prison', lambda config: PettingZooEnv(env_creator(config)))
# now you can use `prison` as an environment
# you can pass arguments to the environment creator with the env_config option in the config
config['env_config'] = {"num_floors": 5}
一个更完整的示例如下:rllib_pistonball.py
石头剪刀布示例#
rock_paper_scissors_heuristic_vs_learned.py 和 rock_paper_scissors_learned_vs_learned.py 示例展示了多种类型的策略相互竞争:重复相同动作的启发式策略、击败对手上一次动作的策略,以及学习到的LSTM和前馈策略。
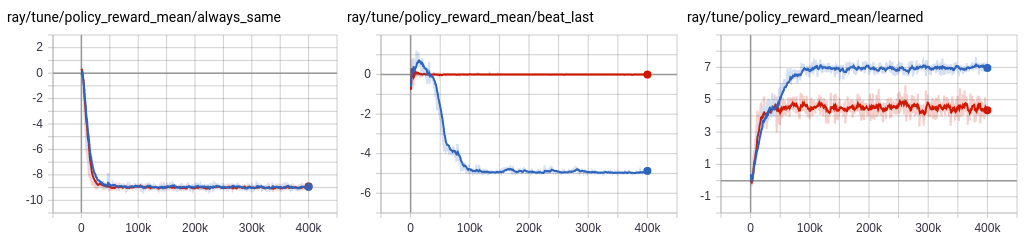
运行石头剪刀布示例的 TensorBoard 输出,其中学习到的策略与相同动作和击败上一步动作的启发式策略的随机选择进行对决。这里比较了启发式策略与学习到的策略的性能,启用了 LSTM(蓝色)和普通的前馈策略(红色)。虽然前馈策略可以通过简单地避免上一步动作轻松击败相同动作的启发式策略,但需要 LSTM 策略来区分并持续击败这两种策略。#
策略间的变量共享#
备注
通过 ModelV2 ,你可以将层放在全局变量中,并在模型之间直接共享这些层对象,而不是使用变量作用域。
RLlib 将在单独的 tf.variable_scope 中创建每个策略的模型。然而,通过显式地使用 tf.VariableScope(reuse=tf.AUTO_REUSE) 进入全局共享变量作用域,变量仍然可以在策略之间共享:
with tf.variable_scope(
tf.VariableScope(tf.AUTO_REUSE, "name_of_global_shared_scope"),
reuse=tf.AUTO_REUSE,
auxiliary_name_scope=False):
<create the shared layers here>
在 示例训练脚本 中有一个完整的示例。
实现一个集中式评论者#
以下是两种实现与多智能体API兼容的集中式批评者的方法:
策略1:在轨迹预处理器中分享经验:
实现集中式批评者的最通用方法涉及定义自定义策略的 postprocess_fn 方法。postprocess_fn 由 Policy.postprocess_trajectory 调用,该方法可以通过 other_agent_batches 和 episode 参数完全访问并发代理的策略和观察结果。然后可以将批评者预测的批次添加到后处理的轨迹中。以下是一个示例:
def postprocess_fn(policy, sample_batch, other_agent_batches, episode):
agents = ["agent_1", "agent_2", "agent_3"] # simple example of 3 agents
global_obs_batch = np.stack(
[other_agent_batches[agent_id][1]["obs"] for agent_id in agents],
axis=1)
# add the global obs and global critic value
sample_batch["global_obs"] = global_obs_batch
sample_batch["central_vf"] = self.sess.run(
self.critic_network, feed_dict={"obs": global_obs_batch})
return sample_batch
要更新批评者,您还需要修改策略的损失。有关端到端可运行的示例,请参见 examples/centralized_critic.py。
策略 2:通过观察函数共享观察结果:
或者,您可以使用一个观察函数来在代理之间共享观察结果。在这种策略中,每个观察都包含所有全局状态,策略使用自定义模型在计算动作时忽略它们不应该“看到”的状态。这种方法的优点是非常简单,您根本不需要更改算法——只需使用观察函数(即,类似于环境包装器)和自定义模型。然而,这种方法在某种程度上不太原则化,因为您必须更改代理的观察空间以包含仅在训练时才需要的信息。您可以在 examples/centralized_critic_2.py 找到这种策略的可运行示例。
分组代理#
在多智能体强化学习中,通常会有智能体组。RLlib 将智能体组视为具有元组动作和观察空间的单一智能体。然后可以将组智能体分配给一个用于集中执行的单一策略,或分配给实现集中训练但分散执行的专门多智能体策略。您可以使用 MultiAgentEnv.with_agent_groups() 方法来定义这些组:
def with_agent_groups(
self,
groups: Dict[str, List[AgentID]],
obs_space: gym.Space = None,
act_space: gym.Space = None,
) -> "MultiAgentEnv":
"""Convenience method for grouping together agents in this env.
An agent group is a list of agent IDs that are mapped to a single
logical agent. All agents of the group must act at the same time in the
environment. The grouped agent exposes Tuple action and observation
spaces that are the concatenated action and obs spaces of the
individual agents.
The rewards of all the agents in a group are summed. The individual
agent rewards are available under the "individual_rewards" key of the
group info return.
Agent grouping is required to leverage algorithms such as Q-Mix.
Args:
groups: Mapping from group id to a list of the agent ids
of group members. If an agent id is not present in any group
value, it will be left ungrouped. The group id becomes a new agent ID
in the final environment.
obs_space: Optional observation space for the grouped
env. Must be a tuple space. If not provided, will infer this to be a
Tuple of n individual agents spaces (n=num agents in a group).
act_space: Optional action space for the grouped env.
Must be a tuple space. If not provided, will infer this to be a Tuple
of n individual agents spaces (n=num agents in a group).
.. testcode::
:skipif: True
from ray.rllib.env.multi_agent_env import MultiAgentEnv
class MyMultiAgentEnv(MultiAgentEnv):
# define your env here
...
env = MyMultiAgentEnv(...)
grouped_env = env.with_agent_groups(env, {
"group1": ["agent1", "agent2", "agent3"],
"group2": ["agent4", "agent5"],
})
"""
from ray.rllib.env.wrappers.group_agents_wrapper import \
GroupAgentsWrapper
return GroupAgentsWrapper(self, groups, obs_space, act_space)
对于包含多个组或混合了代理组和单个代理的环境,您可以结合使用分组和前几节中描述的策略映射API。
层次化环境#
层次化训练有时可以作为多智能体强化学习的一个特例来实现。例如,考虑一个三层策略的层次结构,其中顶层策略发出高级动作,这些动作由中层和底层策略在更细的时间尺度上执行。以下时间线显示了顶层策略的一步,这对应于两个中层动作和五个底层动作:
top_level ---------------------------------------------------------------> top_level --->
mid_level_0 -------------------------------> mid_level_0 ----------------> mid_level_1 ->
low_level_0 -> low_level_0 -> low_level_0 -> low_level_1 -> low_level_1 -> low_level_2 ->
这可以作为一个多代理环境来实现,其中有三种类型的代理。每个高级动作都会创建一个新的低级代理实例,并赋予一个新的ID(例如,在上面的例子中,low_level_0,low_level_1,low_level_2)。这些低级代理在高级步骤开始时出现,并在其高级动作结束时终止。它们的经验由策略聚合,因此从RLlib的角度来看,它只是在优化三种不同类型的策略。配置可能看起来像这样:
"multiagent": {
"policies": {
"top_level": (custom_policy or None, ...),
"mid_level": (custom_policy or None, ...),
"low_level": (custom_policy or None, ...),
},
"policy_mapping_fn":
lambda agent_id:
"low_level" if agent_id.startswith("low_level_") else
"mid_level" if agent_id.startswith("mid_level_") else "top_level"
"policies_to_train": ["top_level"],
},
在这个设置中,训练低级代理的适当奖励必须由多代理环境实现提供。环境类还负责在代理之间进行路由,例如,将 目标 从高级代理传递给低级代理作为低级代理观察的一部分。
查看此文件以获取可运行的示例:hierarchical_training.py。
外部代理和应用程序#
在许多情况下,环境由 RLlib 进行“步进”是没有意义的。例如,如果一个策略用于网络服务系统,那么更自然的方式是让代理查询一个提供策略决策的服务,并且该服务随着时间的推移从经验中学习。这种情况也自然出现在 **外部模拟器**(例如 Unity3D、其他游戏引擎或 Gazebo 机器人模拟器)中,这些模拟器在 RLlib 的控制之外独立运行,但仍可能希望利用 RLlib 进行训练。
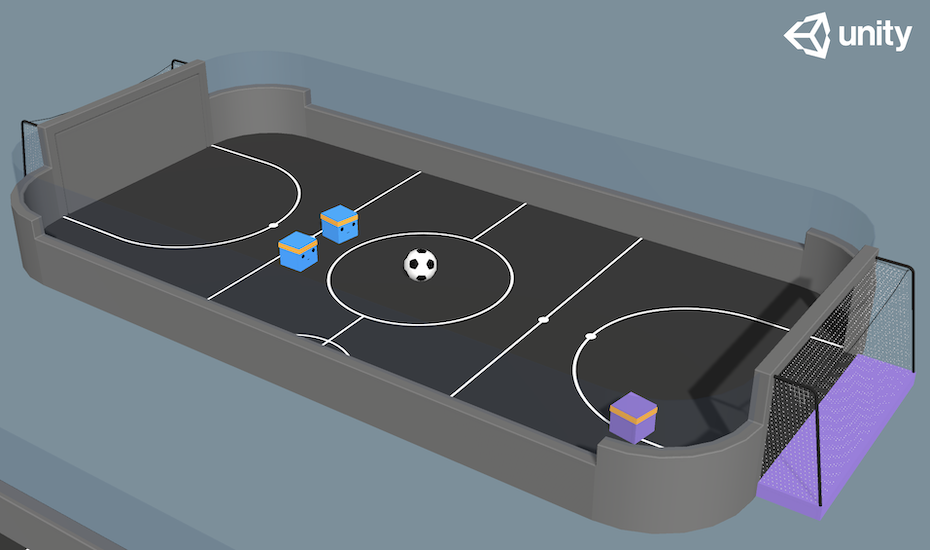
通过 ExternalEnv API,RLlib 正在学习一个 Unity3D 足球游戏。#
RLlib 为此提供了 ExternalEnv 类。与其他环境不同,ExternalEnv 有自己的控制线程。在任何时候,该线程上的代理都可以通过 self.get_action() 查询当前策略以获取决策,并通过 self.log_returns() 报告奖励、完成字典和信息。这也可以同时为多个并发剧集完成。
请参阅这些示例,了解一个 简单的“CartPole-v1”服务器 和 n个客户端 脚本,在这些脚本中,我们设置了一个RLlib策略服务器,该服务器监听一个或多个端口以等待客户端连接,并将多个客户端连接到此服务器以学习环境。
另一个 示例 展示了如何针对 Unity3D 外部游戏引擎运行类似的设置。
记录离策略行为#
ExternalEnv 提供了一个 self.log_action() 调用,以支持非策略行动。这使得客户端能够做出独立的决策,例如,比较两种不同的策略,并且 RLlib 仍然可以从这些非策略行动中学习。请注意,这要求所使用的算法支持从非策略决策中学习(例如,DQN)。
参见
离线数据集 提供了更高层次的接口,用于处理离策略经验数据集。
外部应用程序客户端#
对于完全运行在 Ray 集群之外的应用程序(即,无法打包成任何形式的 Python 环境),RLlib 提供了 PolicyServerInput 应用连接器,可以通过 PolicyClient 实例在网络上连接。
您可以使用以下配置将任何算法配置为启动策略服务器:
config = {
# An environment class is still required, but it doesn't need to be runnable.
# You only need to define its action and observation space attributes.
# See examples/envs/external_envs/unity3d_server.py for an example using a RandomMultiAgentEnv stub.
"env": YOUR_ENV_STUB,
# Use the policy server to generate experiences.
"input": (
lambda ioctx: PolicyServerInput(ioctx, SERVER_ADDRESS, SERVER_PORT)
),
# Use the existing algorithm process to run the server.
"num_env_runners": 0,
}
客户端可以以 本地 或 远程 推理模式连接。在本地推理模式下,策略的副本从服务器下载并缓存在客户端,缓存时间可配置。这使得客户端可以在不需要每次都进行网络往返的情况下计算动作。在远程推理模式下,每次计算动作都需要向服务器发起网络调用。
示例:
client = PolicyClient("http://localhost:9900", inference_mode="local")
episode_id = client.start_episode()
...
action = client.get_action(episode_id, cur_obs)
...
client.end_episode(episode_id, last_obs)
要理解标准环境、外部环境和通过 PolicyClient 连接之间的区别,请参考以下图示:

通过启动一个 简单的 CartPole 服务器 (见下文),并将其连接到任意数量的客户端(cartpole_client.py),或者运行一个 Unity3D 学习服务器 来对抗云中的分布式 Unity 游戏引擎,自己尝试一下。
CartPole 示例:
# Start the server by running:
>>> python rllib/examples/envs/external_envs/cartpole_server.py --run=PPO
--
-- Starting policy server at localhost:9900
--
# To connect from a client with inference_mode="remote".
>>> python rllib/examples/envs/external_envs/cartpole_client.py --inference-mode=remote
Total reward: 10.0
Total reward: 58.0
...
Total reward: 200.0
...
# To connect from a client with inference_mode="local" (faster).
>>> python rllib/examples/envs/external_envs/cartpole_client.py --inference-mode=local
Querying server for new policy weights.
Generating new batch of experiences.
Total reward: 13.0
Total reward: 11.0
...
Sending batch of 1000 steps back to server.
Querying server for new policy weights.
...
Total reward: 200.0
...
为了获得最佳性能,我们建议在可能的情况下使用 inference_mode="local"。
高级集成#
对于更复杂/高性能的环境集成,你可以扩展低级别的 BaseEnv 类。这个低级API模拟了多个代理在多个环境中异步执行的情况。调用 BaseEnv:poll() 会返回来自就绪代理的观察结果,这些结果按1) 环境,然后2) 代理ID键控。这些代理的操作通过 BaseEnv:send_actions() 发送回去。BaseEnv 用于实现RLlib中的所有其他环境类型,因此它提供了它们功能的超集。